



はじめに
今回はAzureのクラウド環境上で稼働するRedisサーバである「Azure Redis Cache」について説明します。サービスのベースとなっているRedisとキャッシュの概念についての説明と、Azure Redis Cacheを使ったサンプルアプリケーションの実装について説明していきます。


Redisとは
まずはAzure Redis CacheのベースとなるRedisについて説明します。Redisは元VMwareのイタリア人エンジニアSalvatore Sanfilippoによって開発されたKVS(Key-Value Store)型のNoSQLデータベースです。KVS型のNoSQLデータベースは、Keyを検索条件としてValueを取得する単純な構造のデータストアです。シンプルなデータ構造で他のデータとの関連を持たないことから、高速にデータの読み書きができ、さらにスケールアウトなどの分散処理に向いているといった特徴を持っています。 RedisはKVS型NoSQLデータベースの中でも、インメモリデータベースに位置づけられます。Redisで保存するデータは全てメモリ上に展開してディスクに保存しないことでI/Oのオーバーヘッドを少なくし、より高速にデータの読み書きができるようになっています。 また、Redisではクエリの処理がシングルスレッドで動作するためデータの書き込みが必然的に排他的になり、データの整合性の担保がマルチスレッドで動作するRDBMS等に比べて容易となっています。
Redisの利用シーン
Redisではデータをメモリ上に展開するため、膨大なデータを永続的に保存するいわゆるデータベースとしての用途には向いていません。Redisはデータベースとアプリケーションの間に入り、頻繁にアクセスされるデータのみを保持してアプリケーションへ高速にデータを返す「キャッシュ」としての位置づけが代表的な利用方法となっています。キャッシュとしての用途では、Webアプリケーションのセッション情報をRedisにキャッシュする使い方が代表的です。アプリケーションサーバからセッション情報を分離することで、アプリケーションサーバのスケーラビリティを確保することができるようになります。
キャッシュとしての用途の他にも、Redisは「キュー」や「Publish/Subscribe」としての機能も備えています。ともにアプリケーションとアプリケーションの間でメッセージの受け渡しを行うための仕組み・通信方式で、「キュー」は1対1で、「Publish/Subscribe」は1対多でのメッセージングを行うことができます。これらの仕組みを使うことで、アプリケーション同士が非同期的に処理を実行する疎結合なシステムを構築することができます。
本稿では、以降Redisをキャッシュとして扱う場合についての説明を行っていきます。
Redisのデータモデル
冒頭で説明したようにRedisはKVS型のNoSQLデータベースですが、Redisには単純なKVSのデータ構造を拡張した、5つの基本的なデータモデルが用意されています。
・文字列型
他のデータ型のベースとなるデータモデル。ごく一般的なKVSと同様Keyに対するValueを持ちます。KeyとValueはともに文字列で表現されます。
またバイナリセーフのため、JPEGなどの画像やJavaやRubyなどのシリアライズしたオブジェクトの格納にも対応できます。
・リスト型
文字列型のリスト。リストの先頭か末尾に値を追加することができます。
SNSのタイムラインのように、最新順に情報を表示する場合などにリスト型を使用したりします。
・セット型
文字列型の順不同の集合。同じ値を持つデータを保存することはできず、必ず一意になります。セット型では、セットと他のセット間での集合演算を行うことができます。
・ソート済セット型
ソート済セット型では、セット型の特徴に加えて各データが「スコア」と呼ばれる値を持っており、これによってセットに順位をつけることができるようになっています。スコアを使った範囲検索などが可能です。
オンラインゲームなどのリーダーボード(ゲームの成績上位者のランキング表)のように、頻繁に変動するランキングなどの使用に向いています。
・ハッシュ型
文字列型のフィールドと文字列型の値のマップ。フィールドでの検索は可能ですが、値での検索はできません。
Redisを使用するアプリケーションではこれらのデータモデルを使い分けることによって、柔軟なデータベースとしてRedisを使用することができるようになっています。
キャッシュ戦略
システムの一部にキャッシュを導入する際は、そのシステムでのキャッシュの使用方法について整理する必要があります。ここでは、キャッシュをどう利用するのかの指針であるキャッシュ戦略についてRedisに限らない内容として説明します。
主な考慮ポイントは以下の3点になります。
・取得に時間やコストがかかるデータ
データベースからのデータ取得に時間のかかるデータや、複雑なクエリを使って検索するためデータベースのマシンリソースを大量に必要とするデータがアプリケーションに存在する場合は、それらのデータをキャッシュすることでシステム全体のスループットが向上する可能性があります。
ただし、テーブルの非正規化やリレーションの見直し、インデックスの付与などのデータベース側の修正によって充分な速度を得られる場合はキャッシュは必要ありません。
・アクセスされる頻度が高いデータ
キャッシュにはアクセスされる頻度が高いデータを保持するようにします。アクセス頻度が低いデータはそれだけユーザからのニーズが少ないことを意味しているため、高速に取得する必要がないものと考えます。またキャッシュのデータ容量には限りがあるため、なるべく参照頻度が高いデータのみを保持し、メモリに無駄のないようにすべきです。
・データの更新頻度が少ない、あるいは変更前のデータを参照しても問題とならない場合
キャッシュにデータを保存した時点から、そのデータはデータベース上のデータよりも古いものであるということになります。データの更新が頻繁に発生するぶん、キャッシュ上のデータの鮮度は落ちていくことなります。
またキャッシュ上のデータを更新するまではアプリケーションがキャッシュから古いデータを取得する可能性があるので、システムやユースケースとして古いデータの参照が許容されるかを検討する必要があります。
Azure Redis Cacheとは
Azure Redis Cacheは、Azureのデータセンター内にホスティングされたRedisを使用することができるサービスです。通常のRedis同様の機能に加え、可用性や運用保守の面でのサポートがプラットフォームとして提供されているものと捉えることができます。
なお、Azureには「Managed Cache Service」、「In−Role Cache」というキャッシュを提供するサービスがありましたが、ともに2016年11月でサービス提供を終了しており、現在はAzure Redis Cacheのみがキャッシュサービスとして提供されています。
Azure Redis Cacheの特徴
Azure Redis Cacheは、前述の通り機能面では通常のRedisができることは基本的にサポートしています。
それに加えてPaaSである強みとして、Redisを運用していく上で課題となるスケールアップやスケールアウトを無停止で実行することができるようになったり、データの永続化などにも対応させることが可能となっています。
これらは、Azure Redis Cacheが用意する3つのレベルに提供される機能も異なります。
「Basic」レベルでは単一ノードのみで提供されるレベルで、250MB〜53GBのメモリサイズを選択することができます。主に開発中や小規模アプリケーション向けとして位置付けられているため、SLAはありません。
「Standard」レベルでは、プライマリノードとセカンダリノードと呼ばれる2つのノード間で同じデータの共有(レプリケート)をして可用性を高めることができるようになっています。また99.9%のSLAが保障されています。
「Premium」レベルではBasicやStandardよりも高性能なマシン上にデプロイされたRedisを使用することができるためより高いスループットを実現することができます。また、Premiumレベルの特徴としてキャッシュ上のデータをディスクに永続化することが可能となっています。そのためスナップショットを作成してデータのバックアップをし、障害発生時にバックアップからデータを復元することができます。また、Azure Virtual Networkと呼ばれる仮想ネットワーク上にAzure Redis Cacheをデプロイすることができるため、アクセス制御などのセキュリティ設定をより詳細に行うことも可能となっています。
Azure Redis Cacheに接続するアプリケーションを作ってみよう
ここからは実際にAzure Redis Cacheを作成して、データの書き込みと読み込みをするまでの手順を紹介していきます。
Resis Cacheの作成
Azureポータルにログイン後、左側のメニューから「すべてのサービス」を選択し、検索フィールドに「redis」と入力してAzure Redis Cacheを選択します。
-

「すべてのサービス」からAzure Redis Cacheを選択する

サービスの画面に遷移すると画面中央あたりに「Redis Cacheの作成」ボタンがあるので選択し、新規Redis Cacheの作成画面に移動します。
-
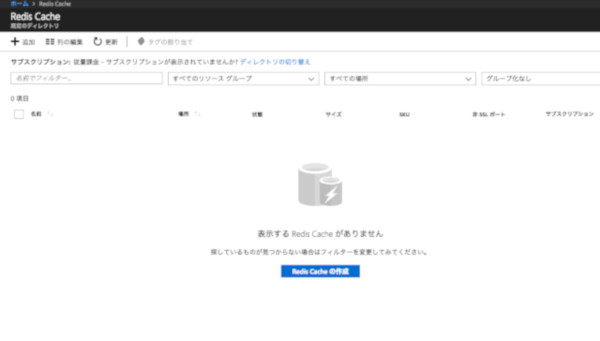
「Redis Cacheの作成」を選択する

新規Redis Cache画面で必須項目を入力していきます。任意の「DNS名」と「リソースグループ」、お手持ちの「サブスクリプション」を選択します。キャッシュには高速さが求められますので、「場所」はRedis Cacheにアクセスするアプリケーションに近いリージョンを選択してネットワークのレイテンシを少なくされることをおすすめします。「価格レベル」については、今回は最も安いBasic C0プランを選択しています。また、Azure Redis Cacheはデフォルトでは通常SSL通信用のポート(6380)のみが使用可能ですが、今回は画面下部の「ポート6379のブロックを解除」にチェックを入れてSSL通信を使用しないポートも開放しています(この設定はRedis Cache作成後にも変更可能です)。
-
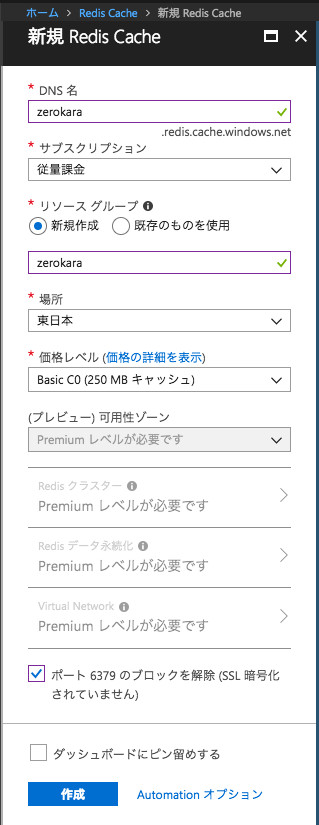
Redis Cacheの新規作成

項目を入力したら、「作成」ボタンを選択してRedis Cacheを作成します。しばらくすると作成が完了してRedis Cacheのダッシュボード画面が表示されます。
-
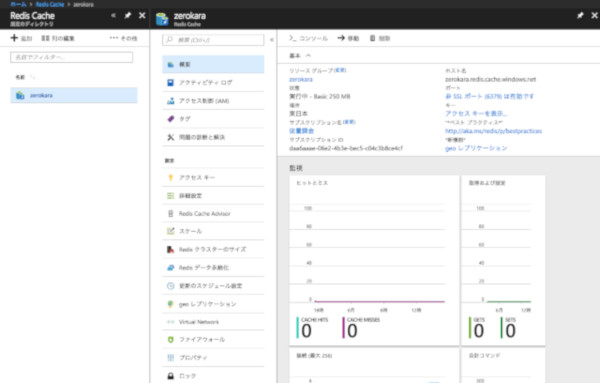
Redis Cacheのダッシュボード

ダッシュボードではキャッシュヒットとキャッシュミス率や現在の接続数やメモリ使用量などを確認することができます。またダッシュボード左側に表示されているメニューから各種設定の変更が行えます。
アプリケーションからAzure Redis Cacheに接続しよう
Azure Redis Cacheへアプリケーションから接続する際は、通常のRedisと同様のクライアントを利用することができます。各言語ごとに利用できるクライアントライブラリは、Redisの公式サイトに掲載されています。
今回はNode.jsを使ってAzure Redis Cacheからデータを読み書きするコードを書いていきます。クライアントライブラリにはnode_redisを使用します。
まずは任意のディレクトリにnpmコマンドを使ってnode_redisをインストールします。
npmコマンドによるnode_redisのインストール
# 任意のディレクトリに移動する
$ cd redis-nodejs-sample
# ライブラリ(node_redis)のダウンロード
$ npm install redis --save
・・・中略
$
インストールが完了すると、ディレクトリに「node_modules」ディレクトリと「package-lock.json」というファイルが生成されます。「node_modules」ディレクトリ配下にnode_redisとその依存ライブラリがダウンロードされ、コード内で使用できる状態となります。 次にNode.jsで実行するJavaScriptのコードを実装します。同じディレクトリで「index.js」というファイルを作成し、コードエディタ等で以下のコードを記述します。
Azure Redis CacheにアクセスするJavaScript(index.js)
// node_redisライブラリの読み込み
var redis = require("redis");
// Azure Redis CacheのURLとポートを指定してクライアントを作成する
var client = redis.createClient({'url': 'redis://<Azureポータルに表示されるホスト名>:6379'}); ・・・①
// アクセスキーを使って認証する
client.auth('<Azureポータルに表示されるアクセスキー>'); ・・・②
// エラーハンドラーの登録
client.on("error", function(err) {
console.log("Error " + err);
});
// 文字列型のデータ書き込み ・・・③
client.set("string-key", "string-value");
// 文字列型のデータ読み込み ・・・④
client.get("string-key", function(err, reply) {
console.log(reply);
});
// ハッシュ型のデータ書き込み ・・・⑤
client.hset("hash-key", "hashtest1", "hashtest1-value");
client.hmset("hash-key", ["hashtest2", "hashtest2-value", "hashtest3", "hash-test3-value"]);
// ハッシュ型のデータ読み込み ・・・⑥
client.hgetall("hash-key", function(err, obj) {
console.log(obj);
});
// クライアントの接続を終了する ・・・⑦
client.quit();
ここではAzure Redis Cacheに接続し、文字列型とハッシュ型のデータの書き込みと読み込みを行うコードを実装しました。
①ではAzure Redis Cacheに接続するためのクライアントオブジェクトを「createClient」メソッドから生成しています。メソッドの引数に、クライアント生成時のオプションオブジェクトを設定することができるようになっています。デフォルトではlocalhost上のRedisに接続するように設定されているため、明示的にURLを指定しています。URLに使用するホスト名は、Azureポータル上のRedis Cacheの概要画面に表示されているものを指定してください。
続いて、Azure Redis Cacheへ接続するために必要な認証情報をクライアントにセットしていきます(②)。アクセスキーは、Redisダッシュボードの「アクセス キー」メニューを選択した画面上に表示されている「プライマリ」の情報を使用します。
-

プライマリアクセスキーの取得

ここまでの設定でAzure Redis Cacheに接続できるようになります。以降はアプリケーションの実装として、Azure Redis Cacheに対するデータアクセスのコードを記述していくことができます。
Redisではデータモデルごとにデータ操作のAPIが用意されており、今回使用しているnode_redisライブラリもこれらのコマンドをラップしたメソッドを提供しています。
文字列型のデータ書き込みには「set」メソッドを使用し(③)、読み込みには「get」メソッドを使用します(④)。文字列型の場合はキーと値を指定するだけですので非常にシンプルです。
ハッシュ型のデータ書き込みには1件書き込む「hset」メソッドや複数件書き込む「hmset」メソッドなどが使用できます(⑤)。ハッシュ型の場合は、キーとフィールドと値の3つの要素を指定して書き込む必要があります。
ハッシュ型のデータの読み込みには、キーを検索条件に全てのフィールドと値を取得する「hgetall」メソッド(⑥)などを使用します。
この「index.js」ファイルを保存し、同じディレクトリで「node index.js」コマンドを実行してください。JavaScriptがNode.jsで実行され、Azure Redis Cacheへのデータの書き込みと読み込みが行われます。実行後、コンソールに以下の内容が出力されていれば実行は成功です。
Azure Redis CacheにアクセスするJavaScript(index.js)
$ node index.js
string-value
{ hashtest1: 'hashtest1-value',
hashtest2: 'hashtest2-value',
hashtest3: 'hash-test3-value' }
$
文字列型とハッシュ型のデータが、実際にAzure Redis Cacheにアクセスして取得されました。このように、RDBMSのように複雑なSQLを発行せずに、プログラミング言語のオブジェクトやコレクションに対する操作に近いAPIを使ってデータの読み書きができることが分かったかと思います。
Azureポータル上のコンソールからRedis Cacheを使おう
最後に、Azure Redis Cacheに保存されたデータをAzureポータルから確認してみましょう。RedisにはさまざまなGUIのクライアントツールが存在しており、それらからもAzure Redis Cacheに保存されているデータを確認することができますが、ここではAzureポータルに付属しているRedis コンソールを使って簡単にデータを確認する方法を説明します。
まずAzureポータルからRedis Cacheのダッシュボードに移動し、概要画面上部の「コンソール」を選択します。
-
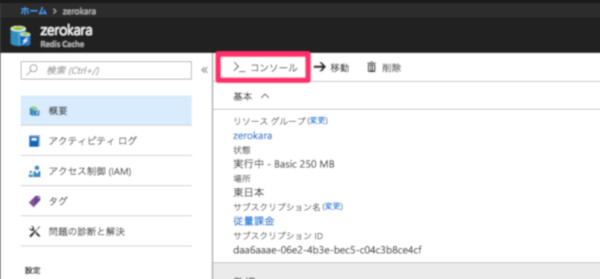
Redis コンソールへ移動する

選択すると、Azureポータル上にRedisのCLI画面が表示されます。このコンソールは、あらかじめAzure Redis Cacheに接続済みの状態となっているので、いきなりデータ操作のコマンドを実行することができるようになっています。
-
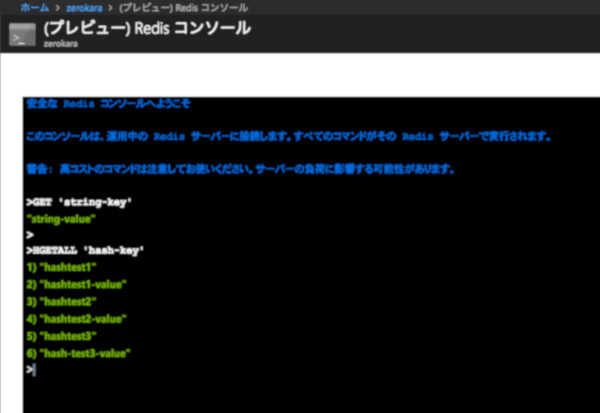
Redis コンソールでデータを参照する

上図は、先程「index.js」で実装したデータの読み込み処理と同等のコマンドを実行した例です。このように、Redis コンソールを使うととても簡単にAzure Redis Cacheにアクセスできることが分かりました。この他にもデータの追加などもコマンドで行うことができるので、ぜひ試してみてください。
まとめ
今回はAzure Redis Cacheについて説明しました。Redisの機能はそのままにAzureのPaaSとしてのサポートを享受することのできる本サービスは、スモールスタートに使ってもよいですし、もちろん本番運用でも活用できることが分かったのではないかと思います。
WINGSプロジェクト 秋葉龍一 著/山田祥寛監修
<WINGSプロジェクトについて>テクニカル執筆プロジェクト(代表山田祥寛)。海外記事の翻訳から、主にWeb開発分野の書籍・雑誌/Web記事の執筆、講演等を幅広く手がける。一緒に執筆をできる有志を募集中










