
2019年の自作パーツの動向を占う「PCテクノロジートレンド」。プロセス編に続いては、IntelとAMDのCPUについて動向を紹介する。
|
PCテクノロジートレンド - その1 プロセス TSMC/Samsung編 PCテクノロジートレンド - その2 プロセス Intel/Globalfoundries編 PCテクノロジートレンド - その3 CPU編 PCテクノロジートレンド - その4 GPU編 |
|---|
2018年は、6月にCore i7-8086Kで話題を集めておき、11月に8コアのCore i9-9900Kをリリース、12月にCore-XシリーズのUpdate、という形でなんとかAMDの攻撃に立ち向かったIntelであるが、2019年はどうなるのか? という話である。
-

Photo01:猫こたつでのぼせたのか、半分出てきたチャシー(営業部長)

8コアのCoffeeLakeに関してはレビューをお届けしているので、今回はこれ以降の動きについて紹介したい。
Intelは12月にサンタクララでIntel Architecture Dayを開催し、ここで同社の将来製品のPreviewを行った。目的は単純で、AMDのRyzenと十分渡り合える製品を展開するというアピールある。まぁこれはIntelとしては、当然やらなければならないことである。
そのArchitecture Dayでは、まずロードマップが刷新された。これまでCore系CPUはアーキテクチャというよりも製品のコード名で呼ばれていたが、今回Sunny Cove/Willow Cove/Golden Coveという新アーキテクチャのコード名が明らかにされた(Photo02)。
-
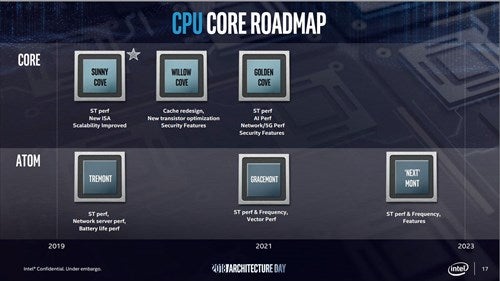
Photo02:時期的に言えば2020年にWillow Cove、2021年にGolden Coveとなる

このうちSunny Coveについては、これを実装したコアがIce Lakeになるのは明白であり、あえてここでIce Lakeではなく新しいSuuny Coveというコード名を前面に押し出してきたあたりに、Intelの苦しい事情が透けて見える。
Sunny CoveはSkylake-SPからの正常進化
さて、このSunny Coveだが、なかなか意欲的な製品である。まずBack End側から説明する。Photo03はSkylakeとSunny Coveを並べたものであるが、Reservation Stationが2→4に増え、Issue Portは8→10に拡張。またStore Dataが命令ALUから分離された。
-
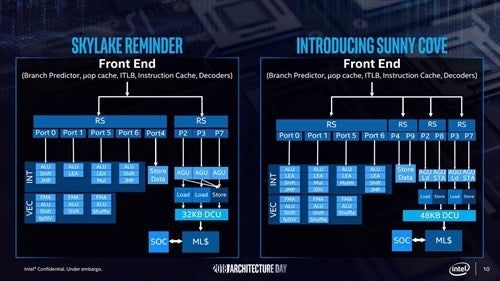
Photo03:こうしてみると、Skylake-SPのLoad/Storeのあたりはかなり無理やり、という感じがしなくもない

また、整数演算ではALUのみならずLEA(Load Effective Address)も4つのパイプで実行可能になった。またiDIV/MulHiが新たに追加。さらに浮動小数点演算では、Shuffle命令が倍増した(Port1でも扱えるようになった)。
このほか、Load/Storeが同時に2つずつ発行可能となり、StoreDataが2ポートで扱えるようになった。
基本的にこの構成は、Skylake-SPの延長にある。もともとSkylakeでは、Port 0とPort 1を組み合わせてAVX512命令を1命令/cycleで実行する形だが、Skylake-SPではPort 5を拡張し、ここに512bit幅のFMA/ALU/Shuffleを実装している。
このPort 5は単独でAVX512命令を1命令/cycle実行できるので、合計でAVX512命令を2命令/cycleで処理できるという仕組みだった。ただし、これを実装すると当然ながらLoad/Storeで必要な帯域が倍になるので、これはLoad/Storeユニットの帯域を倍にする、という力業で解決している。
-

Photo04:Skylake-SPは、Skylakeに後からAVX512とL2を加え、Load/Storeを強化するという、ちょっとアドホックな実装なので、最適化という意味では不十分ではあった

Sunny Coveではこれを踏襲しつつ、まずLoad/Sore AGUはそれぞれ別ユニットとするとともに、Reservation Stationも分離してスケジュールを行いやすくしている。
実のところIssue Portの増加は、すべてこのLoad/Store AGUとStore Dataユニットの分離に使われているわけで、Skylake-SPで行ったAVX512命令の強化を、足回りがきちんと受け止められるように最適化した、という感じの進化である。
これに加えて、キャッシュの大容量化も図られている(Photo05)。ただしPhoto02にもあるように、キャッシュの構造そのものは次のWillow Cove世代で見直しが図られる予定で、逆にいえばSunny Coveの世代では大容量化のみで対応にという形になるようだ。
-
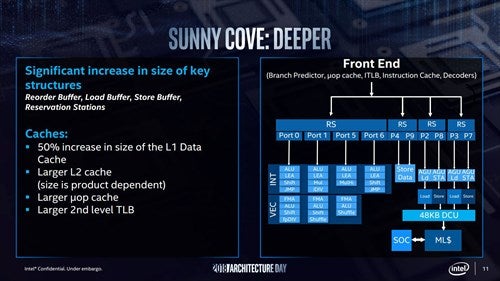
Photo05:L2の容量が可変なのはともかくとして、2nd Level TLBの大容量化に関して言えば間違いなくServer Workload向けの拡張である

ただ、L1 DataとμOps Cacheの大容量化により、より多くの命令を同時に処理できる素地が整った。これを踏まえて、Decodeはついに同時5命令処理に達した(Photo06)。
-
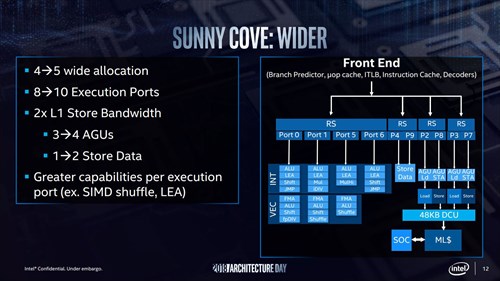
Photo06:本来ならなかなかインパクトがある話なのだが、2018年にSamsungがリリースした同時6命令デコード、12命令処理(Issueポートが12)のM3というお化けがいるので、あまりインパクトを感じないのは筆者がマヒしているだけかも知れない。ちなみにSamsungはこの後継のM4を2018年末に発表しており、さらにIPCが向上している(詳細はまだ明らかにされていない)

Sunny Coveにおける最大の特徴はIPCの向上であるが、その骨子がこのDecode段のワイド化だ。加えて当然の様に、内部バッファも大容量化が図られている。そもそもIssue Portが10まで増えているから、ROBのサイズは間違いなく大容量化されているだろうし、それぞれのReservation Stationが独立でIn-Flight Windowを持つわけだから、In-Flight出来る命令数も当然増えている。
また、よりScalabilityを持つように工夫されたというあたりも重要である。これはCoreというよりもXeon Scalable向けの特徴で、1つのダイに対して、多数のコアをMeshなどで接続できるように、バッファを大容量化し、Latencyの削減に努めたということであろう。
-
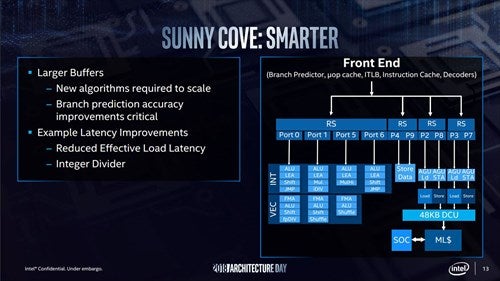
Photo07:分岐予測の精度を更に引き上げるとなると、あるいはIBMやAMDの様にPerceptronベースの分岐予測メカニズムを搭載している可能性もある

ということで総じて言えばIce Lakeのベースとなると思われるSunny Coveは、Skylake-SPからの正常進化という形の実装になっている。
Sunny CoveベースのIce Lakeはいつ出るの?
問題は、これがいつ出荷開始されるかという話だ。前回、プロセスのところで説明した通り、Intelは10nmプロセスの再デザインをほぼ終了している「はず」で、ぼちぼちIce Lakeの実装に入る事になる。
ちなみにIce Lakeに関しては、クライアント向け製品が先行することが明らかになってる。2018年5月の事だが、J.P.Morganの64th Annual Global Technology, Media, and Communication Conferenceが行われたが、ここでIntelのMurthy Renduchintala氏がJ.P.MorganのアナリストであるHarlan Sur氏に、以下のような説明をしている。Xeonについては
"I'm equally excited by the products we would be launching this year and next year in 14-nanometers on our datacenter roadmaps."(今年と来年、われわれは14nmベースのデータセンター向け製品を投入する)
とのことで、Xeonは2020年まで10nmに移行しないとしている。その一方で
"And so, therefore we're comfortable with the 14-nanometer roadmap that will give us leadership products in the next 12 to 18 months, as we seek to optimize the cost structure and yields of our 10-nanometer portfolio."(われわれは今後12~18カ月掛けて10nm製品のポートフォリオのコストと歩留まりを改善する予定で、その間は14nmプロセスを利用した製品のロードマップが予定されている)
ともコメントしている。改善に要する期間が、12か月とすると2019年5月あたり、18か月で2019年末あたりに10nm製品が投入されるわけだ。
Ice Lake世代の場合、前述したとおり、コアそのものが複雑化している上にバッファとかキャッシュも大容量化されている。さらに後で細かく説明するが、統合されるGPUも大幅にEUを増やしており、14nmプロセスのままだと相当ダイサイズが大きくなる。
つまり、Ice Lakeは10nm以下を前提とした設計になっている。そのため、現実問題として2019年末までは、製品が登場しないと考えられる。運が良ければ2019年のクリスマス商戦に間に合う、というあたりが現実的な見方だろう。
ちなみにRenduchintala氏が12~18か月と幅を持たせたのは、まだこの時点では10nmの配線層をやり直すという最終的な決断が下されてなかった(プロセスのところで書いたが、下されたのは6月以降だろうと筆者は想像している)ためで、つまり配線層のデザインはそのままで、Ice Lakeの物理設計だけをやり直して解決する、というオプションが残っていたためと考えられる。ただ、このプランは現時点では消えていると思う。








