VLSIシンポジウム 2022では、さまざまな半導体技術が発表が行われる。今回は、そんな発表の中からコンピューティング(機械学習、量子コンピューティングなど)分野の注目論文を紹介しよう。
コンピューティング分野
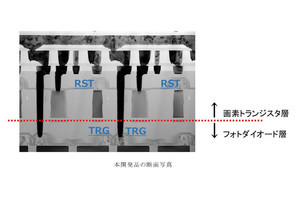
5-1:強誘電体トランジスタを用いたリザバーコンピューティング (東京大学)
東京大学は、誘電体トランジスタ(FeFET)を用いたリザバーコンピューティングの原理実証を行ったことを報告する予定。リザバーコンピューティングは、機械学習の一種であり、出力層の重みづけを学習するだけで済むため、エッジAI応用での効率的なオンライン学習が可能となる。
FeFETにおける分極のダイナミクスを用いる演算方式を示し、短期メモリ(STM)タスクとパリティチェック(PC)タスクについて、FeFETにおけるドレイン電流の時間応答からタスクを実証し、発話認識では95.9%の認識率を実現したという。
-
図1 強誘電体トランジスタを用いたリザバーコンピューティング (提供:VLSIシンポジウム、以下同様)

5-2:抵抗変化型メモリを用いた8ビット20.7TOPS/W コンピュート・エンジン (ミシガン大学)
米ミシガン大学は、Applied Materials(AMAT)と共同で、多値セル抵抗変化型メモリ(ReRAM)を用いたアナログ・CIM(Compute-in-Memory)により、機械学習や科学計算の高密度・高効率な演算を実現したことを報告する予定。
SoCプロトタイプは、4つの内蔵ReRAMベースCIMタイルとRISC-Vホストで構成されている。ピーク効率は20.7TOP/Wであり、演算密度は8.4TOPS/mm2、128MNISTデータセットを用いた時の分類精度は96.8%と報告している。
世界最大の前工程半導体製造装置メーカーのAMATが最先端の後工程にまで進出してきている点も注目される。
-
図2 抵抗変化型メモリを用いた8ビット20.7TOPS/Wコンピュート・エンジンのブロック図とシステム・オン・パッケージ(SoP)

5-3:5nmプロセスを用いて製作した95.6TOPS/W深層学習Transformerモデル向け推論アクセラレータ (NVIDIA)
自然言語処理・マシンビジョンなどで使用されるTransformerベースのDNNに特化した機械学習プロセッサはエッジデバイスやデータセンターの主力になりつつある。高精度の計算は消費電力増加を引き起こす一方で、低精度の計算は誤認識やユーザー満足度の低下につながる。
そこでNVIDIAは、最新の深層学習アクセラレータプロトタイプを5nm CMOSプロセスで製造したことを報告する。算術処理中にデータ内容に応じてベクトル単位で4ビット度にスケーリングするという新しい手法を提案する予定。
同手法により0.7%の精度劣化に抑えつつ95.6TOPS/Wという電力効率を達成している。
-
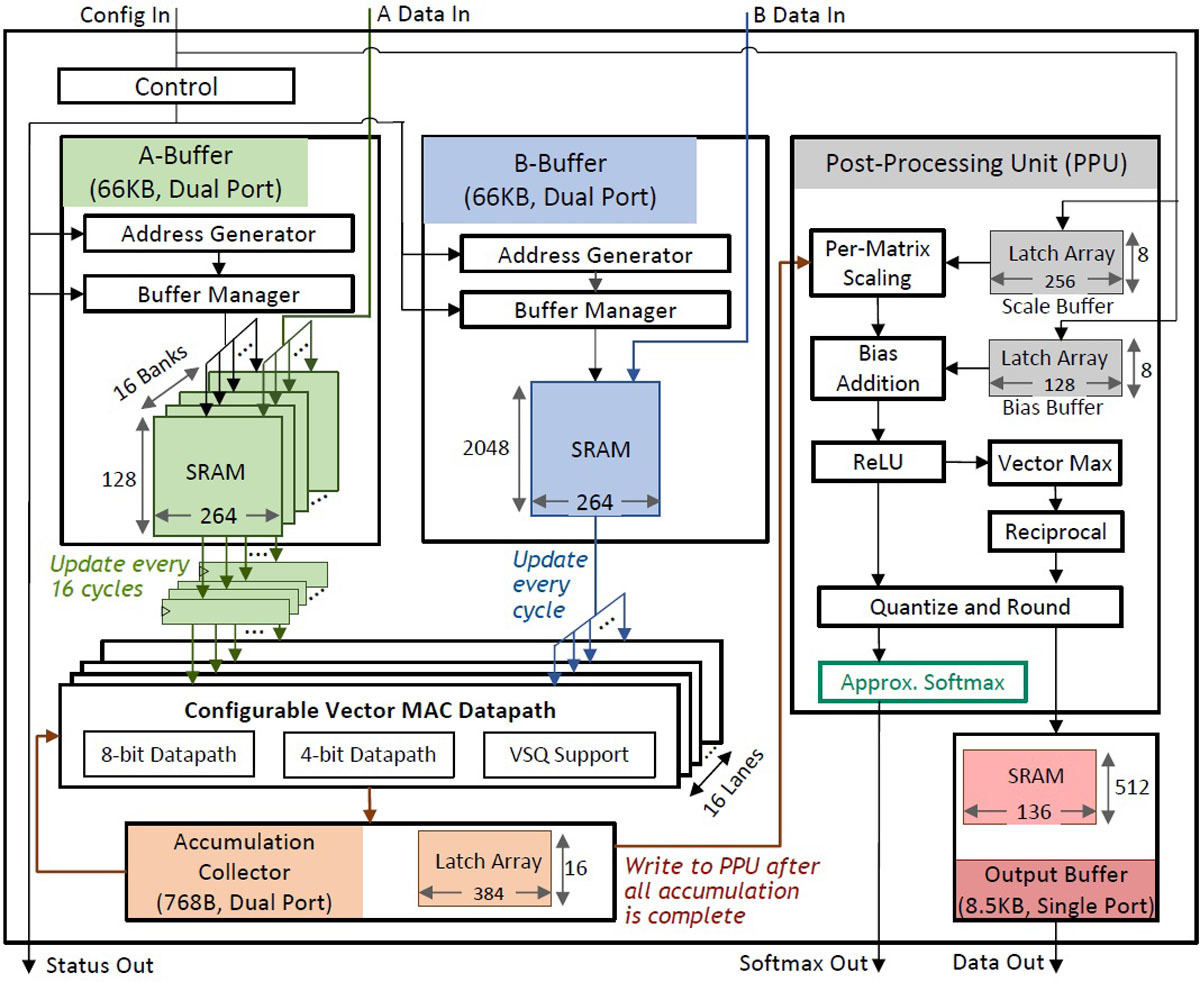
図3 95.6TOPS/W深層学習Transformerモデル向け推論アクセラレータのブロックダイアグラム

5-4:超伝導Qubit計測のための10mK動作クライオCMOSマルチプレクサー (ベルギーKU Leuven)
量子コンピューティングで、高スループットの実現にマルチプレクサは魅力的であるが、動作時に発生する熱雑音は、量子ビットの性能に悪影響を与える可能性がある。
ベルギーのルーベンカトリック大学(KU Leuven)は10mKのベース温度で動作する超低電力クライオCMOS単極4スロー(SP4T)RFマルチプレクサーを使用して超伝導キュービットのベンチマークを行い、35μsを超えるキュービットコヒーレンス時間を取得し、サーフェスコードに基づく量子エラー訂正に必要な、99.93%の平均シングルキュービットゲート忠実度を取得したことを報告する予定。
KU LeuvenはベルギーimecおよびTSMCと協業して開発したとしている。
-
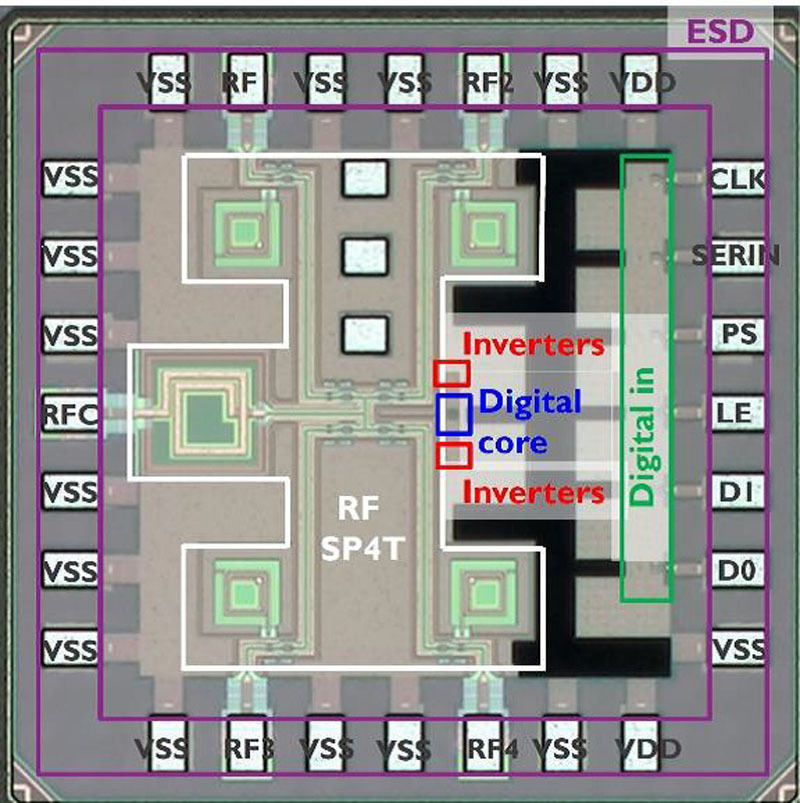
図4 KU Leuvenが開発したクライオCMOSマルチプレクサーチップ