Tenstorrentの日本法人であるテンストレント・ジャパンは3月28日、オンライン形式で日本法人設立に関する記者説明会を開催。国内におけるビジネスや同社の製品動向などについて説明を行った。
日本に初の海外法人を設立したTenstorrent
テンストレント・ジャパンの設立については既報の通りであるが、実は設立そのものは今年1月18日だったとの事(Photo01)。ただ設立の後も色々やるべきことが累積しており、発表が2か月ほど遅れてしまった、との事だった。
-

Photo01:社長の中野氏自身、Tenstorrentの入社は昨年12月との事

その日本法人であるが、同社は他のRISC-Vベンダーと異なり、MCU向けなどのソリューションは一切提供せず、エンタープライズやクラウド、HPC、車載といったハイエンドマーケットをターゲットとする(Photo02)。
-

Photo02:そもそもTenstorrentの製品ラインナップそのものにMCU向けコアがない

これについては「(MCUなどのマーケットは)すでに多数の競合が参入しており、競争が激しい分野であり、敢えてそこは外してハイエンド向けにフォーカスする」という説明であった。ちなみに日本法人のトップはこの3人になるとの事である(Photo03)。
-

Photo03:Jim Kellerは名目上のトップ(というか全社を見ているから当然トップ)なのだが、Benette氏がこうしたOverseas Officeの統括で、その下に中野氏が居るという感じになるのかと思う

日本法人は同社としては初の海外法人であり、今後他の国でも現地法人が出来る場合は、似たような構成になるものと思われる。
2製品がすでに出荷済み
さて同社はすでに「Grayskull」と「Wormhole」という2つの製品に関して、シリコンの出荷を開始している訳だが(Photo04)、これに続く「Black Hole」は昨年アナウンスがあったものの、「Quasar/Grendel」は今回初めての発表である。
-

Photo04:推論向けのGrayskullはすでにPCIeカードの形で2021年から出荷を開始しており、PoCあるいは検証などで若干であるがシステムが出ているとの事。一方学習向けのWormholeは昨年シリコンの出荷が開始されているが、こちらはまぁこれからだろう

Black HoleはWormholeの後継というかプロセスを微細化し、「Ascalon D5コア」とさらにはSiFiveの「X280」まで搭載するという構成だ。さて、これに続くものとして、4nmで製造される推論向けのQuasarと、3nmでChiplet構成となるGrendel(こちらは学習向け)がどちらも2024年に投入される、としている。
-

Photo05:GrendelはMemoryやI/O Chipletは7nm、CPUは3nmでの製造となる。L2/L3用の大容量SRAMも7nmあたりでChipletするかと思ったのだが、そういう訳ではなさそう

余談だが、このGrendelというのはこれ全体ではなく、AI Chipletの名前の可能性もある。というのは、後述するHPC向けではCPU Chipletが「Aegis」、AI Chipletが「Grendel」として記載されているためだ。
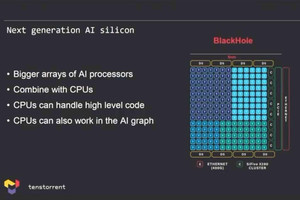
さてAIチップの方だが、基本は同社の開発した「Tensix」と呼ばれるコアが基本である。このTensixの詳細は明らかになってないのだが、以前の説明では5つのSingle Issue RISCコア(これは制御用)と4TOPSの性能を持つNN(Neural Network)用のConpute Engineが組み合わされたもので、これを複数集積した構成になるとしている(Photo06)。
-
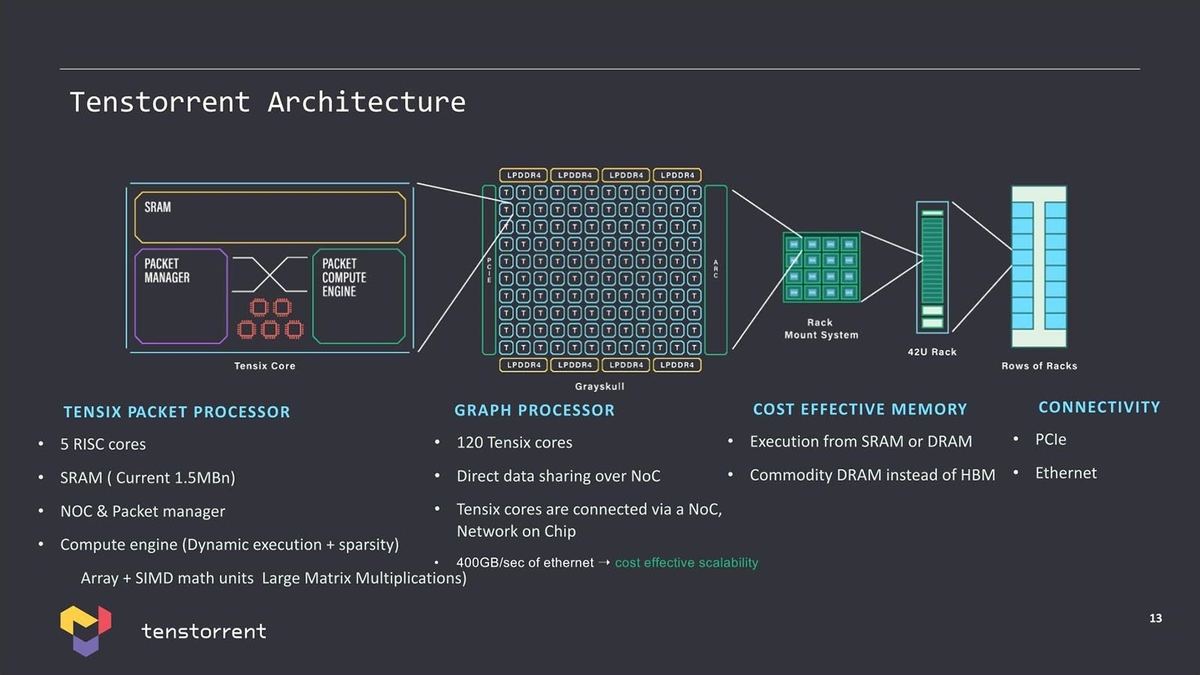
Photo06:このTensixコアはGrayskull/Wormhole/Black Holeで共通。これをPhoto05を見る限りはQuasar/Grendelも同じに見える

今回発表になったのは、このTensixコアの中の5つのRISCコアもRISC-Vとの事だろうか。これは正直ちょっと意外だった(Tensixコアそのものの設計はJim Keller氏がTenstorrentに参加する前に終わっている)。ちなみにTenstorrentのAI性能は非常に高いとされるが、それは(恐らくソフトウェアで)Sparseにうまく対応しており、この結果としてメモリ利用効率も高い(Photo07)事が挙げられる。
-
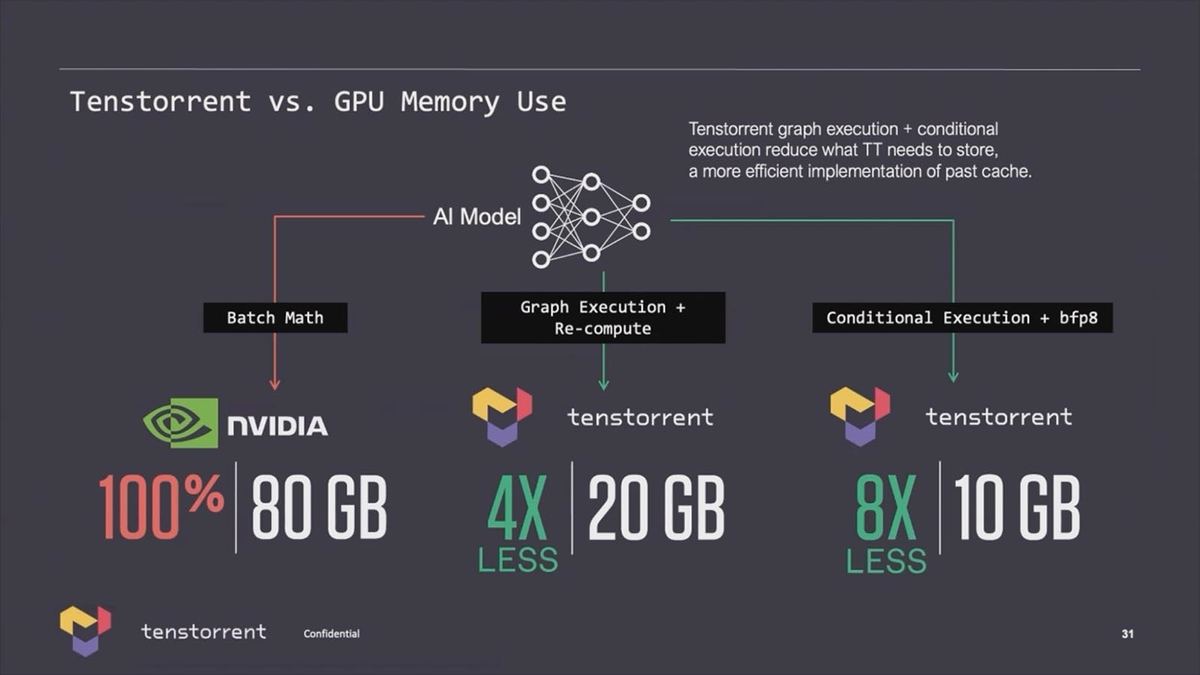
Photo07:これも今回初のスライド。同社のソフトウェアではうまくメモリ利用効率を上げる(つまりSparseな行列で、空き部分を排除することで、より少ないメモリでネットワークを処理できる)のが秘訣の1つという訳だ

またソフトウェアフレームワークでは、TT-Metalという、Tensixコアに近いところまでAPIを公開している事も特徴とされる(Photo08)。
-
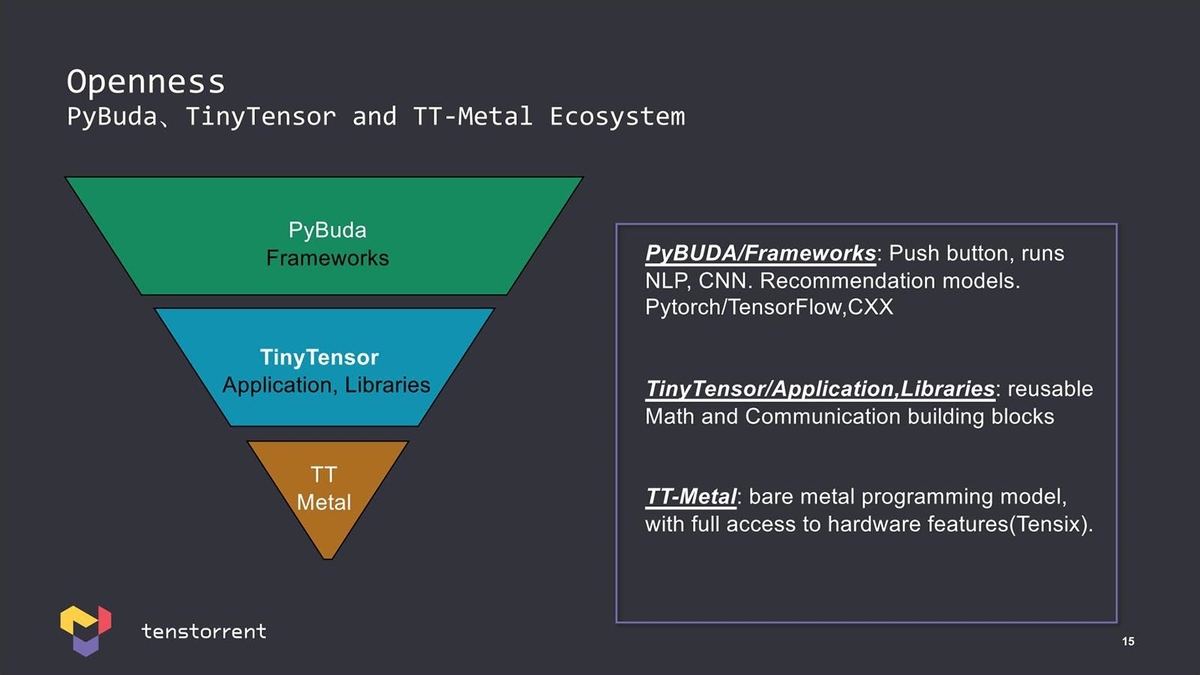
Photo08:といいつつ、そのTensixコアの詳細が明らかになってない辺り、TT-Metalを利用するにはNDA契約が必要なのかもしれない

先にも書いたようにGrayskullはすでに量産をスタートしており、3種類のPCIeカードの形で提供される。Wormholeの方は、Single/Dual Chipのカードが存在するのは間違いなさそうだが、まだGalaxy Nebula Serverが存在するのかどうかは不明である(Photo10)。
-

Photo09:正直言えばE75の75W TDPはEmbeddedにはちょいと厳しくないか? という気もするのだが。あとE150は恐らく1.3GHz動作、E300は1.1GHz動作と想定される。E75は900MHz動作でないと数字が合わない。まぁ丸めれば全部1GHzなのだが

-

Photo10:余談だがWormholeのチップ単体のTensixコアの数そのものは実はGrayskullより少ない。というのはWormholeはそもそも複数チップを繋ぐことを前提としているためで、この目的で100GbEを16ポートチップに搭載している

ただ、小規模なPoC向けサーバーはすでに存在するようだ(Photo11)。
-

Photo11:E300カードを装着できる組み込み向けサーバー例

IPの提供メインもChipletの設計サポートまでも視野にいれるRISC-V
次にRISC-Vについて。Tenstorrent自身はあくまでもRISC-VのIPを提供するのがメインであるが、場合によってはChipletの設計までサポートする事も視野に入れているとする(Photo12)。
-

Photo12:現在進行している商談では、本当にIPだけ欲しいという顧客からチップを持ってこいという顧客まで、非常に幅広いニーズが寄せられているとする。Chipletに関してはまだ未知の部分が大きいだけに、Chipletそのものを欲しいという顧客がいるのも理解できる

まずそのコアであるが、「Ascalon」と呼ばれる、最大8命令デコード/11命令発行のSuper Scalar/Out-of-Orderコア(Photo13)がメインである。
-
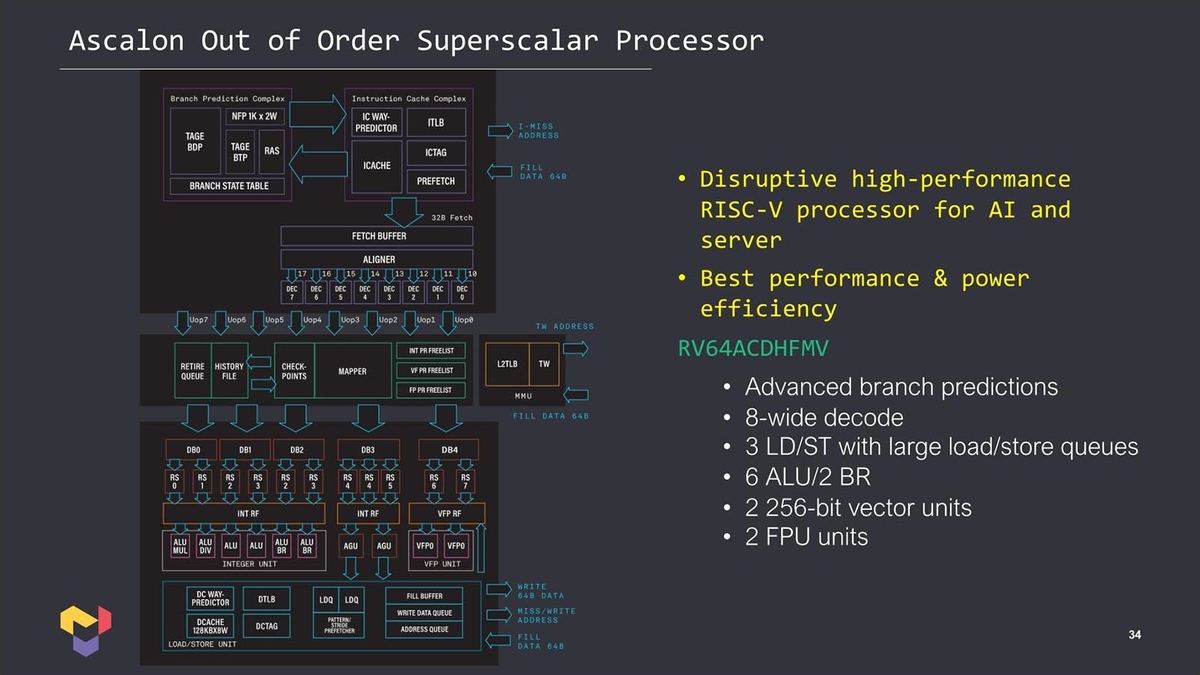
Photo13:これを見るとしみじみJim Kellerのデザインだなと思う

面白いのは、最初にこのハイエンド(Ascalon D6)を開発、これのサブセットとして2~6命令デコードのコアを用意した(Photo14)との事だ。
-
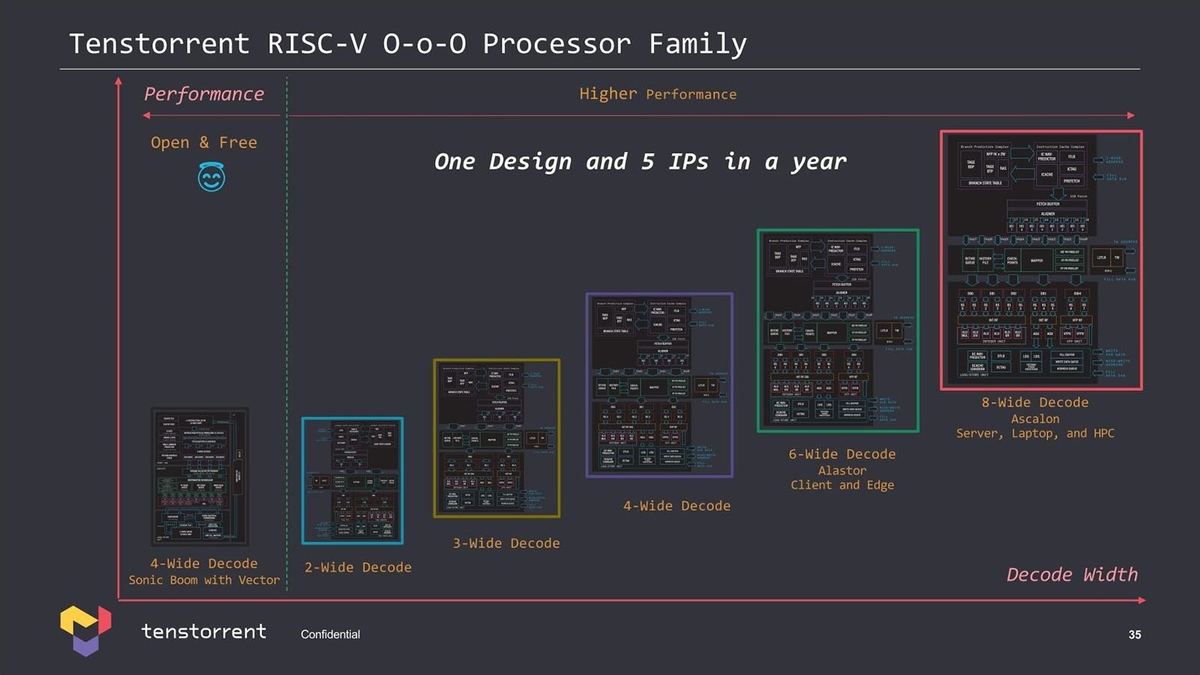
Photo14:普通はアップサイジングでコアを展開するのであって、ダウンサイジングでコアを展開するというパターンは珍しい気がする

このAscalonを複数集積した「Cluster」(Photo15)や、そのClusterをさらに集積した大規模Cluster(Photo16)なども示された。
-
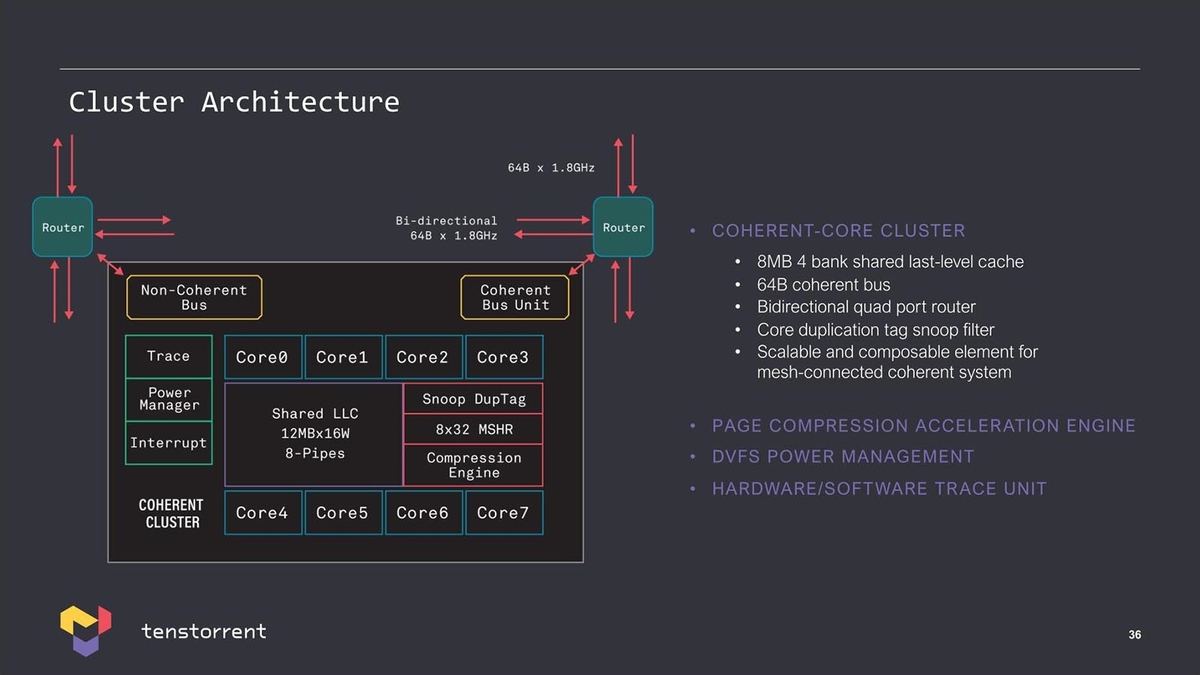
Photo15:このClusterがChipletの最小単位になりそうな気がする

-
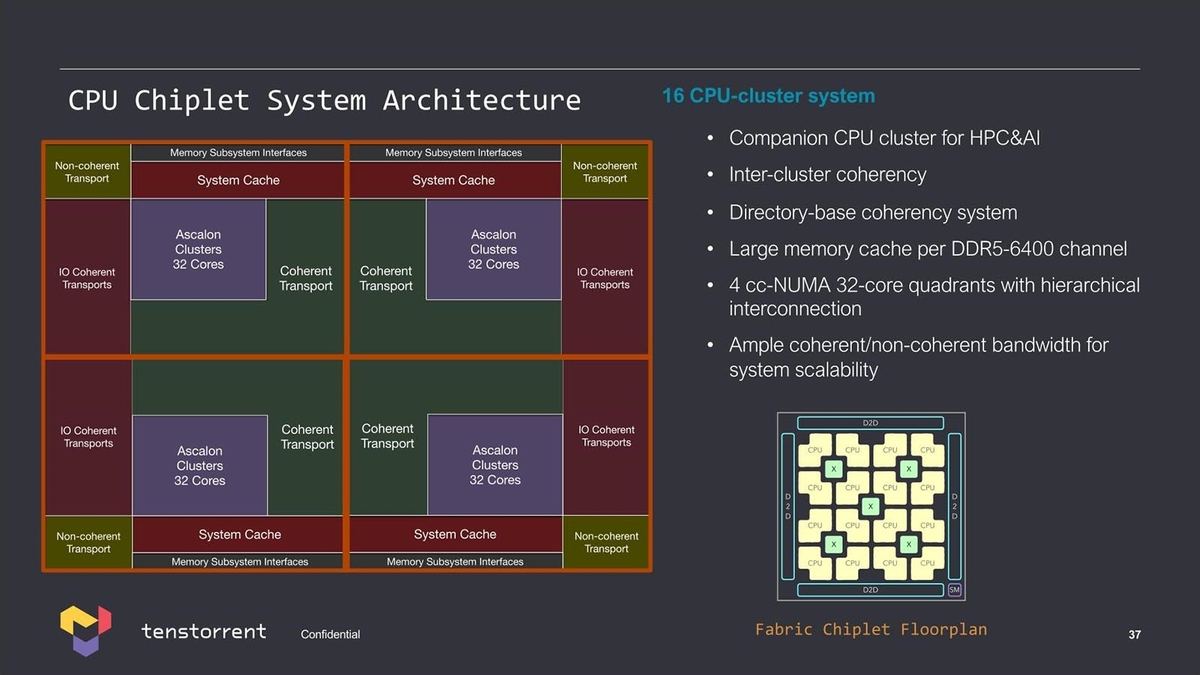
Photo16:左の図では32core Cluster×4だが、右のFloor Planは8core Cluster×16で、このあたりはニーズ次第で色々変更できるという意味だろうか?

実際この128core Clusterの場合、もう少し具体的な構成(Photo17)も紹介されている。
-
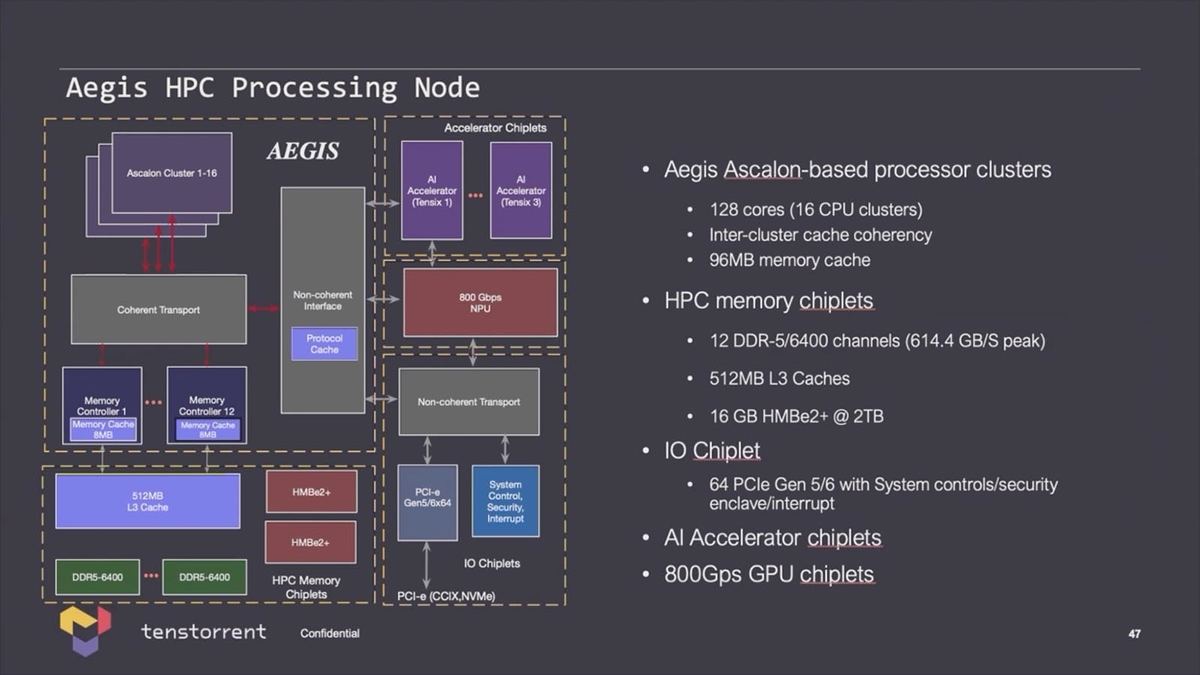
Photo17:L3は“AEGIS” Clusterの外にあるとか、そのL3へのI/Fが12chとかいうあたりがなかなか独創的と言うか、何でこうなった? と言うべきか。まぁL3がClusterの外にあるのは、こうした大容量SRAMは先端プロセスを使ってもエリア削減効果が見込めないので、これは7nmあたりで製造。AEGISは3nmあたりを使う、ということだろう

またここからは「技術的に可能」のレベルであるが、大規模なAIプロセッサ(Photo18)や、さらに大規模なシステム(Photo19)も可能とされる。
-
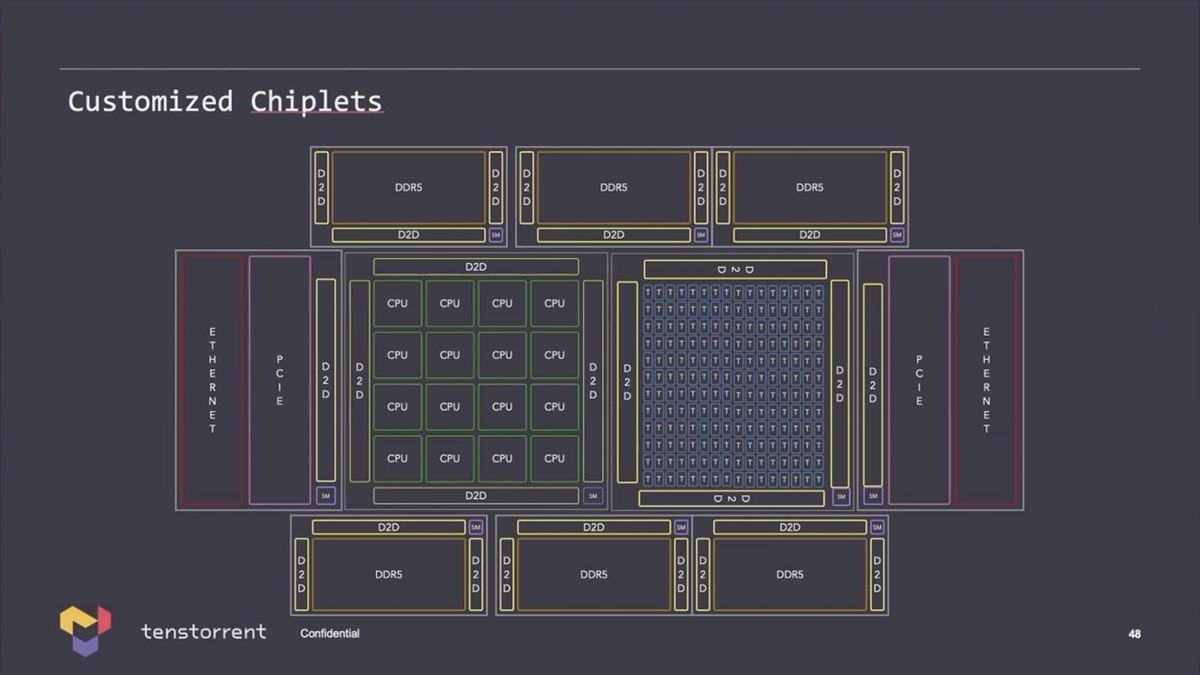
Photo18:これはAMDのMI300とかNVIDIAのGrace Hopper、IntelのFalcon Shoreなどと同じ発想で、GPUとAIプロセッサをCache Coherentで接続するというもの。ただこれだと大容量のL3のChipletも必要にならないだろうか?(DDR5 I/Fに統合されるのかもしれないが)

-

Photo19:これを見るとGrendelとAegisがTSMCのN3E、他がN7での製造になっている

同社は単にプロセッサだけでなく、様々なChipletを提供する事もビジネス的に視野に入れており、これを組み合わせる事で大規模システムでも構築可能、という事だろう(Photo20)。
-

Photo20:ただこれ、どこかのOSATとパートナーシップでも結ばないと実際には難しい気もするのだが……

もう1つ同社が狙っているのが自動車向けである。といってもAutomotive ECUとかではなく、自動運転を狙う方向である(Photo21)。
-
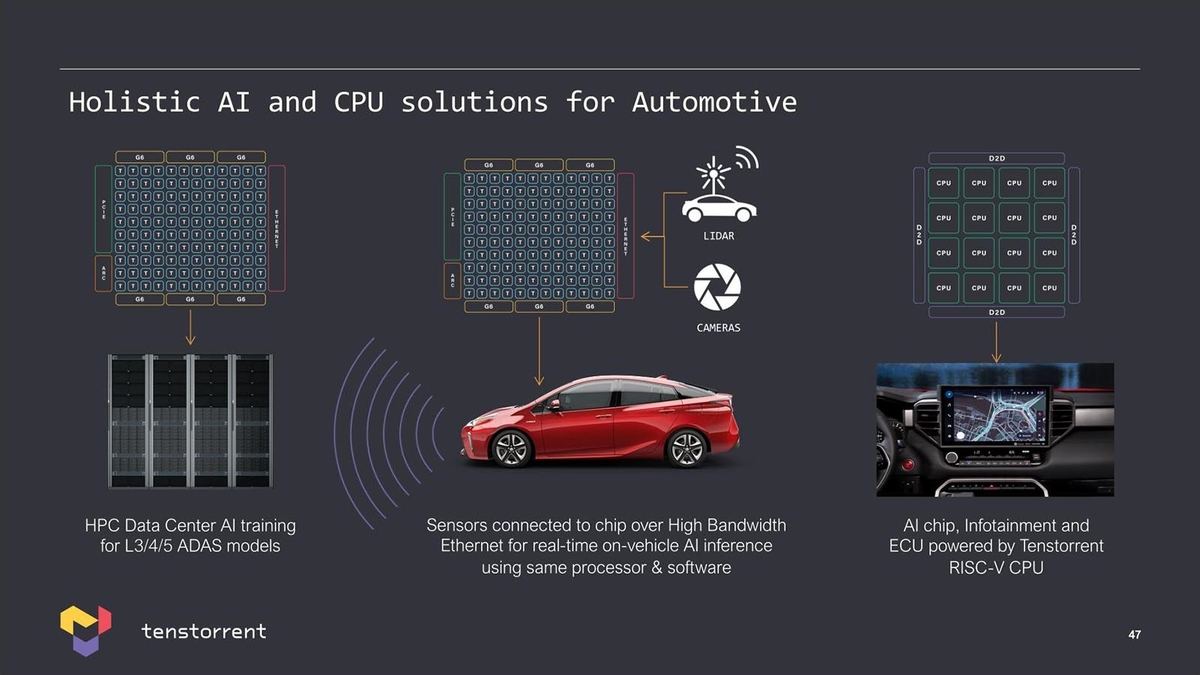
Photo21:このあたりの戦略は、そもそもJim Keller氏がTeslaに居た事と無縁ではなさそう

もともとTeslaのAutopilotとかFSDは、単に車内に自動運転用のソフトウェアを入れて終わりではなく、その運転データを常時吸い上げ、それを基により良い自動運転のアルゴリズムを開発するというフィードバックが形成されており、この目的で今年からTeslaは自社開発のDojoと呼ばれるスーパーコンピュータを稼働させている(従来はNVIDIA A100ベースのシステムが使われていたが、Dojoはこれの30倍高速だそうだ)。同じようなシステムを自動車会社が提供したいと思った際に、これを容易に構築するための環境を同社は提供する、という訳だ(Photo22)。
-
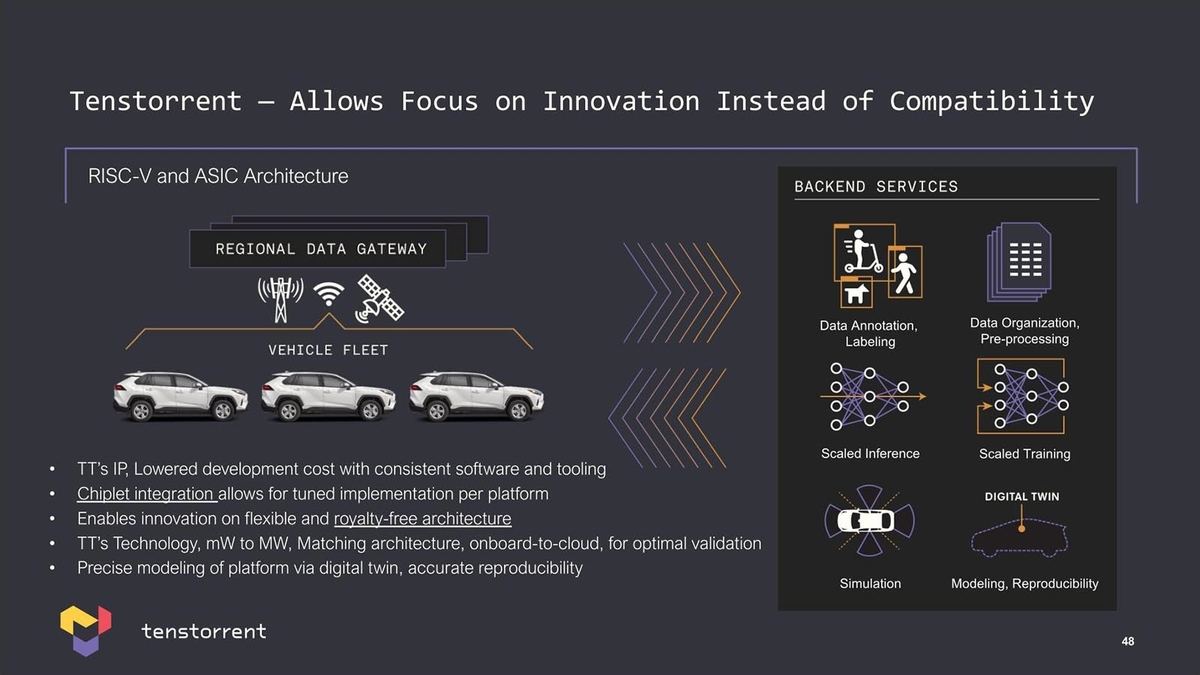
Photo22:これは車載側、つまりTeslaのFSD Computerに相当するものを、同社のChipletを使って簡単に構築できるという話。余談だが“royalty-free architecture”はあくまでもRISC-Vを使うのにロイヤリティが掛からないという話で、実際に同社のIPを使ってチップを作る場合には、そのチップへのロイヤリティは当然かかるとの事

すでにこれに向けたPoC用のボードも存在する(Photo23)との事で、色々水面下ではすでに活発に活動していることが明らかになった説明会であった。
-

Photo23:本来のNuburaはWormholeを32個つないだ構成だが、ここに搭載されているものはもう少し規模が小さい気がする