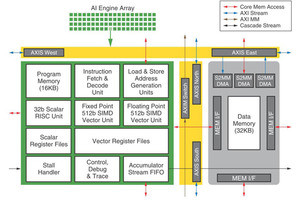
Versal AI Engine-ML(AIE-ML)はコンピュートコアがマシンラーニング用に最適化された製品である。前世代の製品と比べて、乗算器のサイズを2倍にし、INT8の演算性能を2倍に引き上げている。また、INT4の演算やBFLOAT16の演算を追加している。
さらに、データメモリのサイズを32KBから64KBに倍増している。そして、メモリタイルを一新し、最大38MBのメモリをAIEアレイに接続できるようにし、メモリバンド幅も拡大している。
-
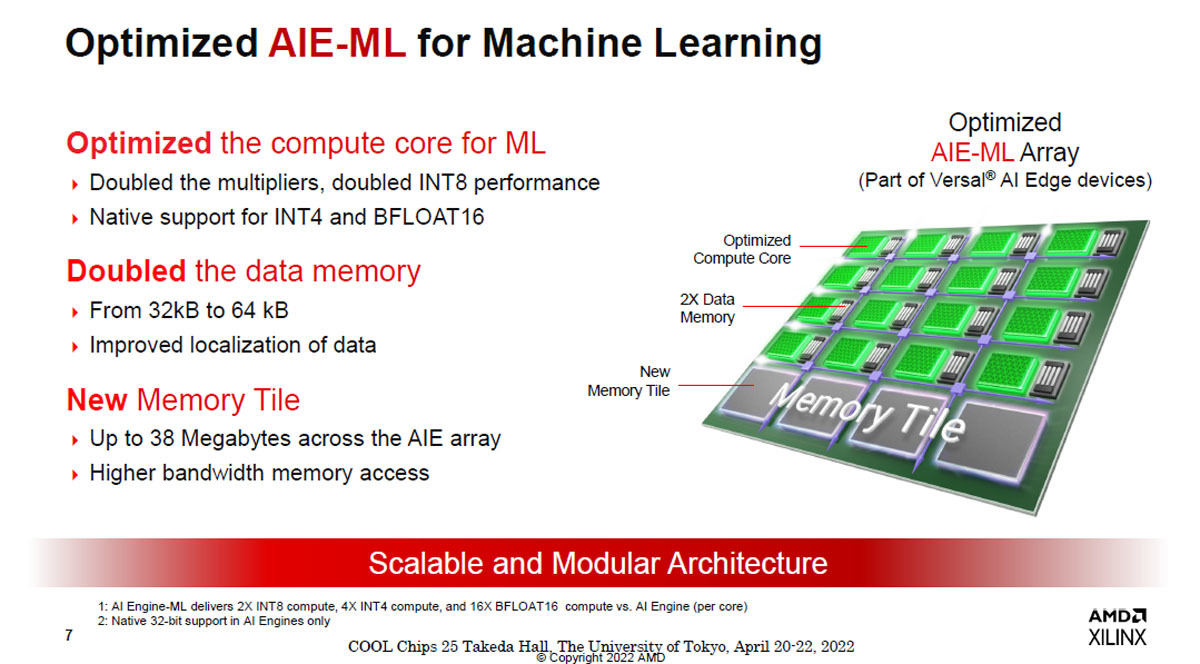
図4 AIE-MLアレイはマシンラーニング用に最適化されており、INT8の性能を倍増し、INT4、BFLOAT16演算をサポート。また、最大38MBのメモリをメモリタイルに搭載

-
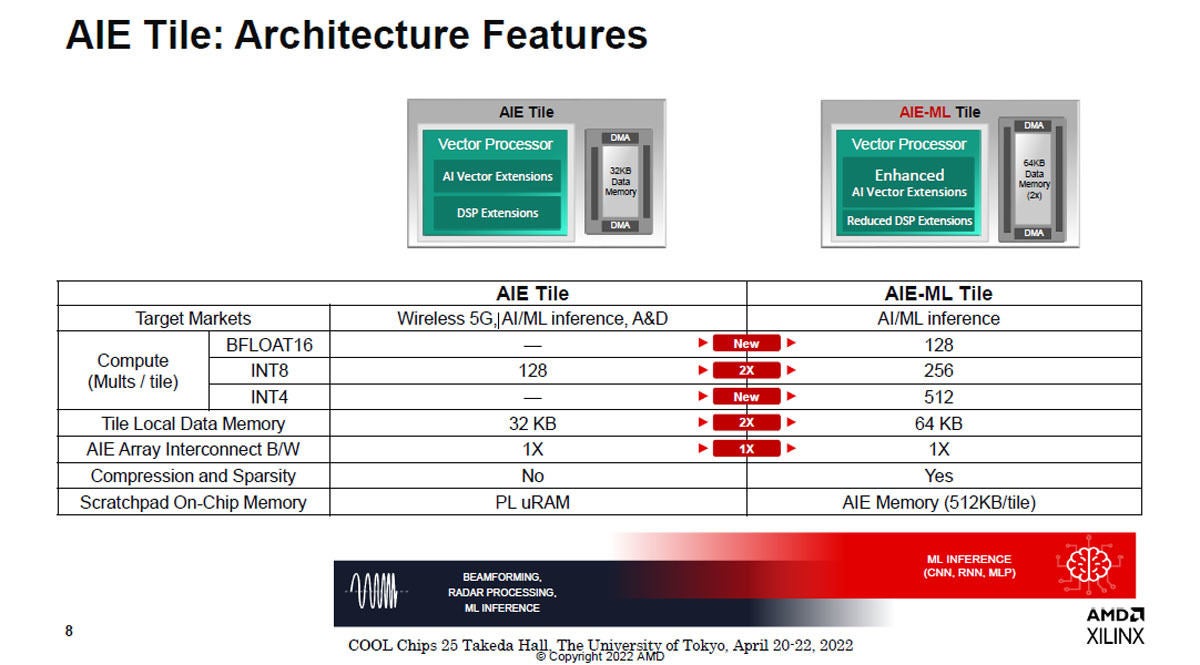
図5 AIE-MLタイルでは、従来のAIEタイルでは無かったINT4、BFLOAT16をサポート。INT8演算器を256個/タイルに倍増。スクラッチパッドメモリを512KBに増加

-
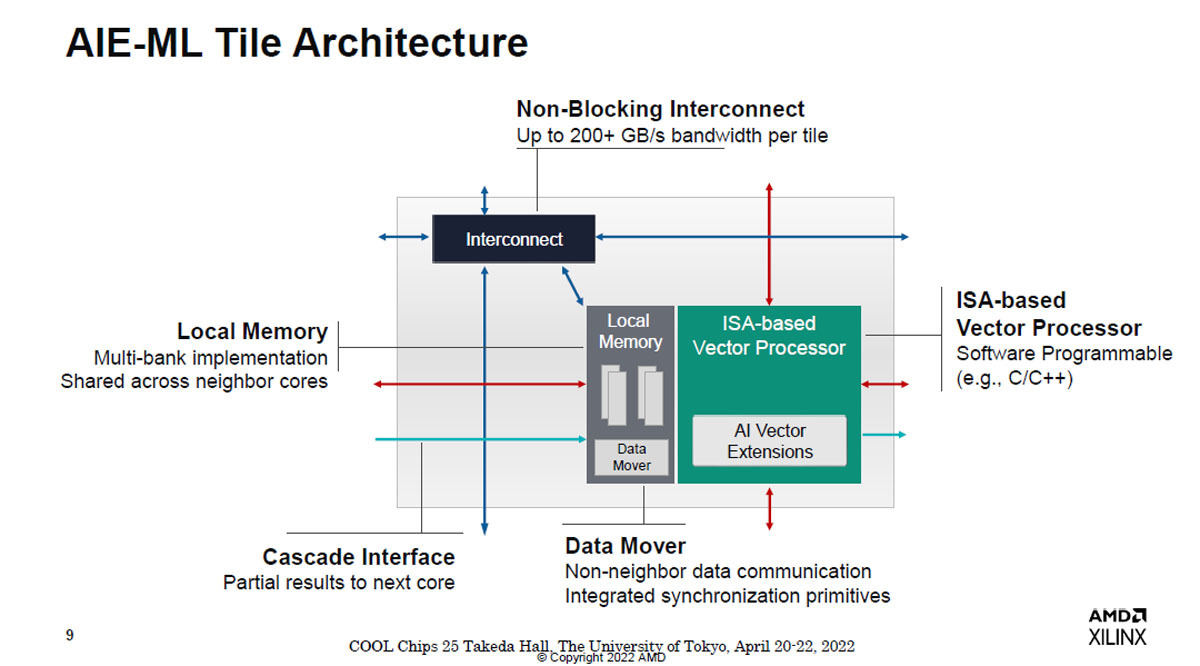
図6 AIE-MLタイルのアーキテクチャ。AI向けのベクタプロセサと附属するローカルメモリからなるタイルを2次元メッシュネットワークで接続した構造になっている

AIE-MLタイルは4要素の入力ベクトルと重みベクトルの内積を計算する。また、共通の重みベクトルに4つの異なる入力ベクトルを掛ける計算を同時に実行できる。このデータマルチキャスティングを行うと演算性能を4倍に引き上げることができる(データマルチキャスティングを行わない場合はVE2802のINT8演算性能は228TOPSで、データマルチキャスティングを行うと479TOPSとなる)。
-
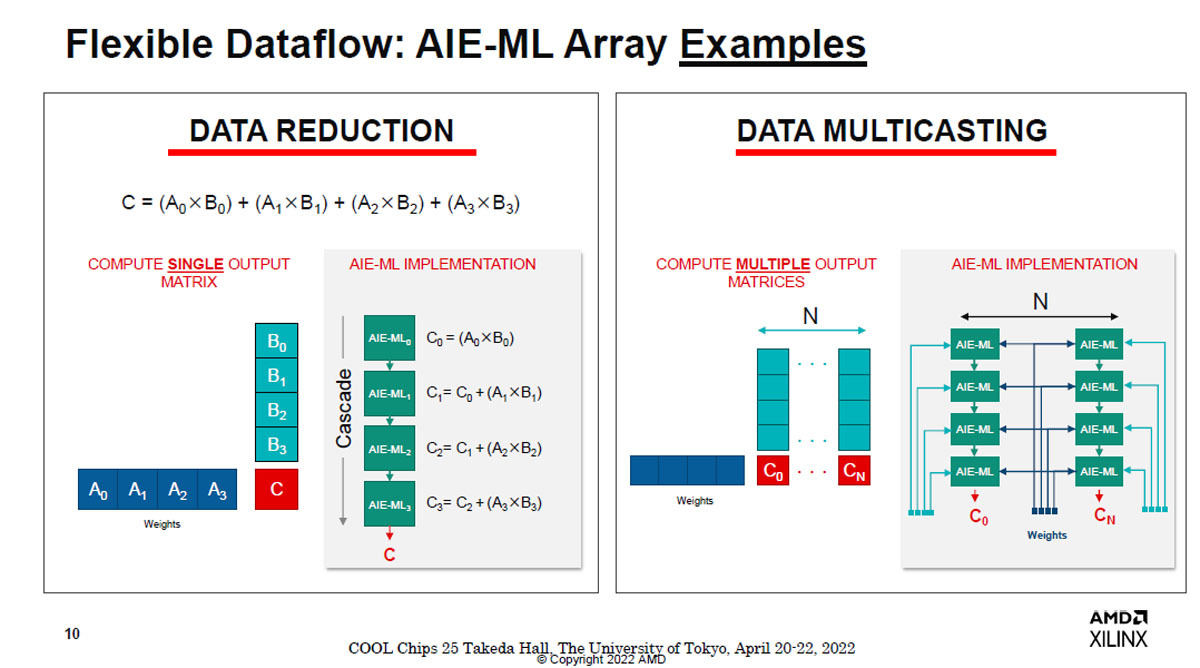
図7 AIE-MLアレイの演算の例。1つの内積を計算する場合と、共通の重みを使って4つの内積を計算する場合の2つのモードがある

-
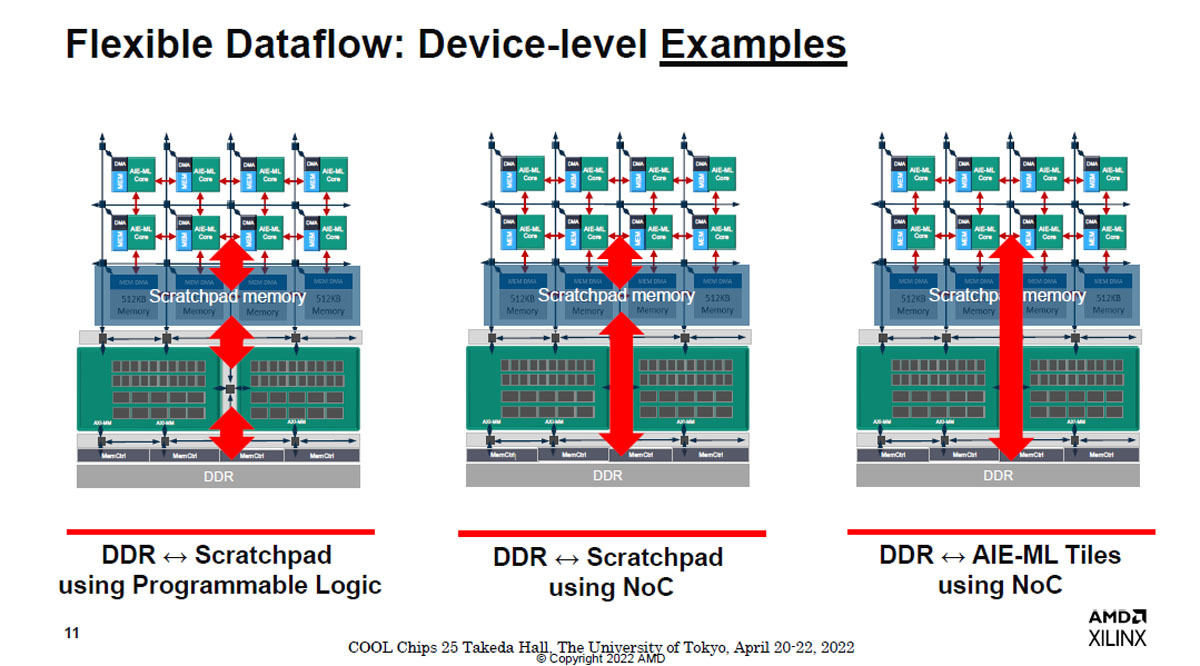
図8 AIE-MLタイルはDDRメモリから直接転送ができる。左端の図のプログラマブルロジックで転送する場合は、2ステップの転送が必要。NoCネットワークを使う場合もスクラッチパッドメモリを経由する必要があり、メモリから演算タイルに直送する転送がもっとも効率が高い

AIE-MLタイルは圧縮演算ができ、圧縮してメモリ転送を行うことにより転送するデータ量を減らすことができる。図9のグラフはResNet50の中間結果の圧縮結果を示すもので、でこぼこはあるが、層の番号が大きくなるに連れて圧縮によりデータ量が減る傾向にある。
圧縮無しの場合は、DDR DRAMとの間のデータのやり取りに~56GB/sを必要としているのに対して、圧縮を行うと~29GB/sとほぼ半分のデータ転送で済んでいる。
-
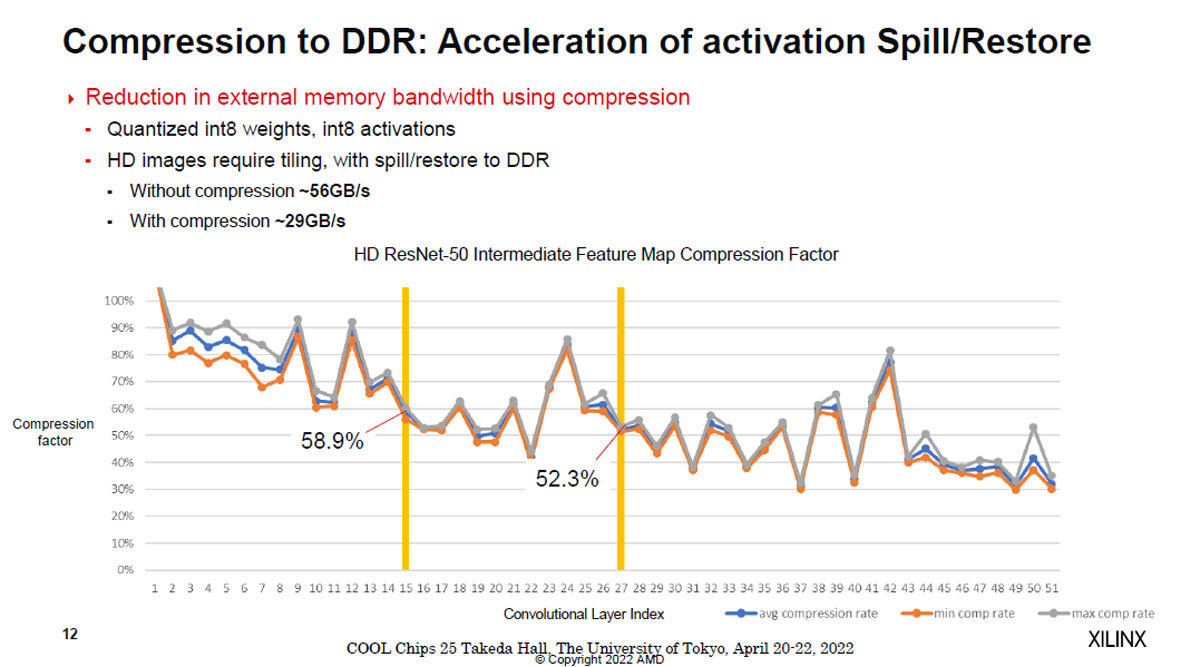
図9 AIE-MLタイルは外部メモリに書き出す情報を圧縮することができ、トラフィックを半分程度に低減することができる

-

図10 AIE-MLは高い計算能力を持っており、渋滞を起こさないノンブロッキングな転送が可能。転送と並列に計算を実行することができる

通常のマルチコアの場合はL1キャッシュ、L2キャッシュを経由して他ブロックのCPUにデータを移動させることになる。また、そのデータはDRAMにも書かれることになるが、これは無駄な書き込みである。これに対して、右側のAIE-MLアレイを使った場合は左の構成で発生するキャッシュミスは起こらず、ノンブロッキングで常に同じタイミングで動作する。そして、転送バンド幅も大きく、スクラッチパッドメモリも小さくて済む。
-
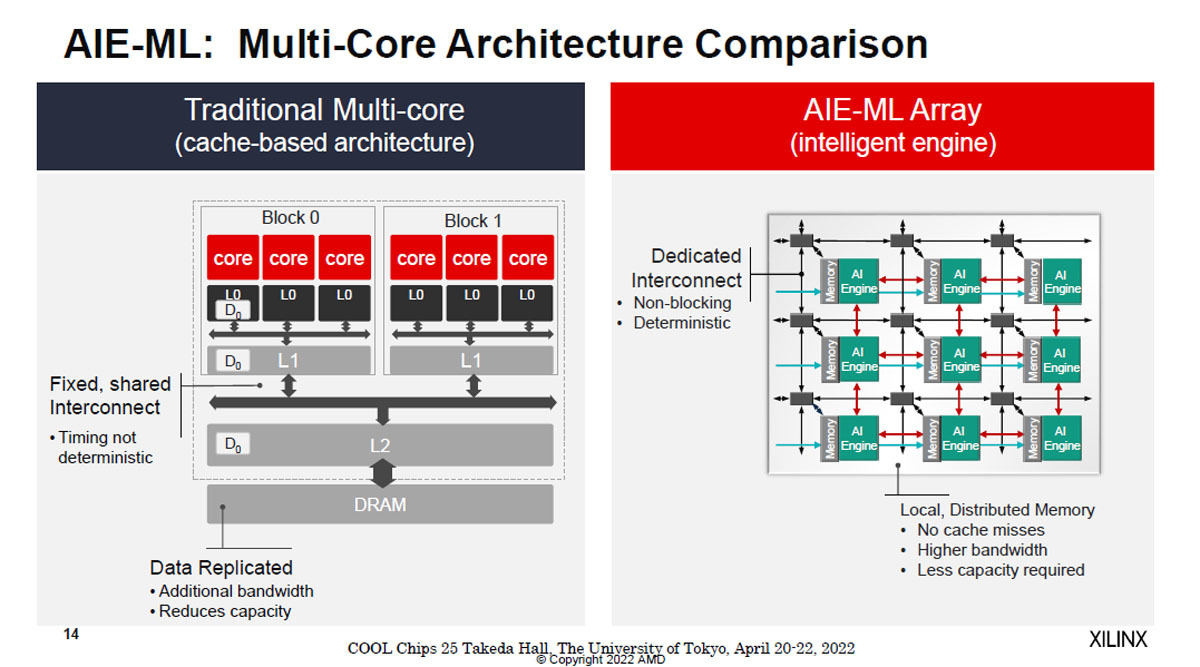
図11 通常のマルチコアの構成(左)とAIE-MLアレイを比べると、AIE-MLはキャッシュミスは発生せず、ノンブロッキングで常に同じタイミングで動作する

AIE-MLのインタフェースはバックワード互換で、古いハードウェアの機能範囲であれば同じプログラムが動作する。新しいハードウェアを使えば、当然、新しい機能を追加できる。
-
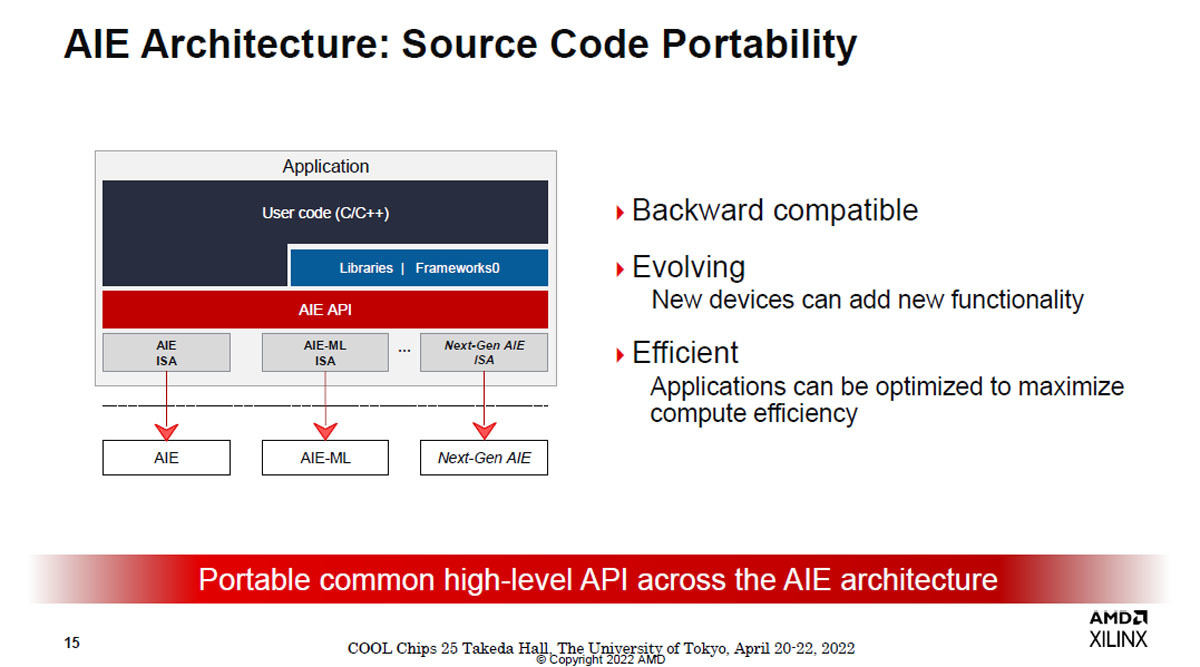
図12 AIEタイルのアーキテクチャ。AIEタイルはバックワード互換で、古いハードウェアでも必要な機能を持っていれば動作する。そして、新しい機能が必要な場合は、その機能を持つハードウェアを追加すれば動作させられる

XilinxはAIの開発用にVitis AIというソフトウェアスタッを提供している。モデルの記述を行うフレームワークとしては、PyTorch、TensorFlow、Caffe、TVMなどを使うことができる。そして、AIのOptimizer、Quantizer、Compiler、Profilerなどと各種のライブラリを提供している。その下にXilinx Runtime Libraryがあり、CNN DPU、LSTM DPU、MLP DPUなどのハードウェアモデルがある。
-

図13 PytorchやTensorFlowなどでモデルを記述して、コンパイルすれば動作させられる。各種ライブラリもXilinxから提供される

これは1つの例であるが、ビデオのデコーダはXilinxのハードマクロのユニットを使い、ビデオのサイズの調整ユニットはプログラマブルロジックで作成する。そして、オブジェクト検出はYoloV3のようなAIフレームワークで記述されたものを利用する。この部分は物理的にはAIE-MLで作る。そして、この例では3つのML ClassifierをResNet50モデルで作り、その結果を総合して認識結果をArm Cortex-A72 CPUで生成するという構成になっている。
このように、ロジックで容易に作れるVideo SchedulerはFPGAで、AI関係はAIE-ML、専用回路が向いているDecoderはハードマクロ、最終段のDecision MakingはArmのCortex-A72を使うという適材適所の造りとすることで、全体が1個のVE2802で作られている。
-
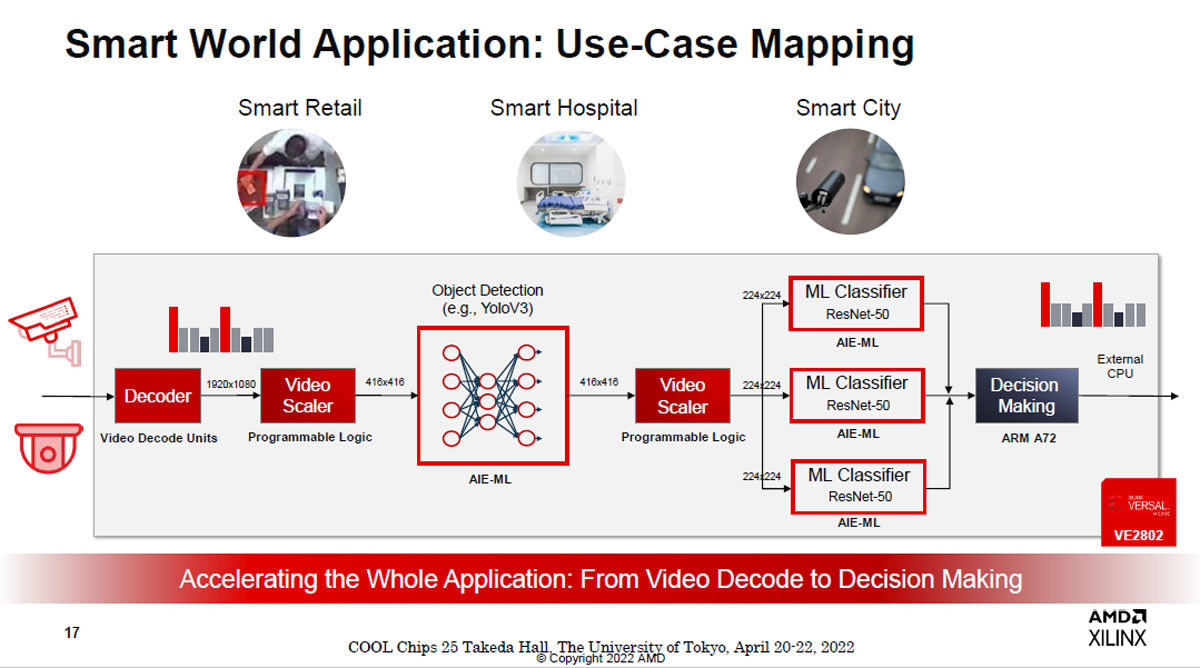
図14 VE2802でビデオ信号から3つの特徴抽出を行って目的のパターンを認識する装置を設計する例。用途ごとにそれに適したタイルを使っている

次の図15はVersalとNVIDIAのJetson AGX Xavierの性能を比較した図である。左のグラフは15W程度のAIアクセラレータを比較したもので、ResNet50でエッジアグレゲーションを行った場合の結果で、Versal AIが3.3倍の性能、右はVE2802とより大きなJetson AGXの比較で、Versalが4.2倍の性能となっている。
-
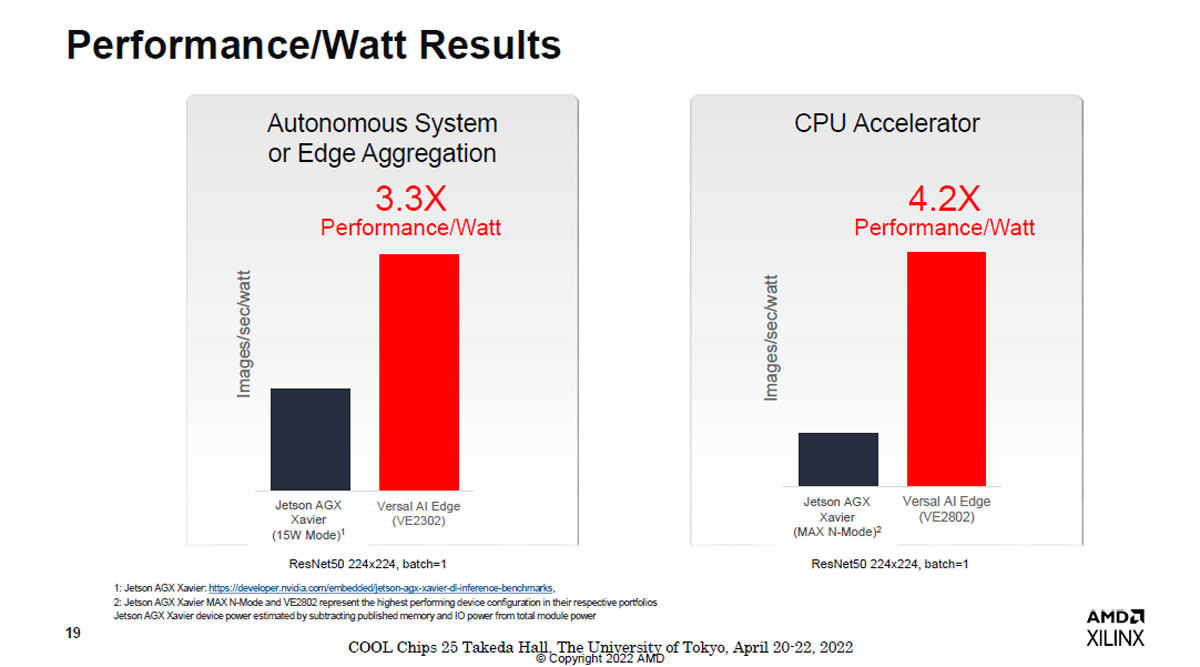
図15 自動システムの処理を行うアクセラレータでJetson AGXとVersal VEの性能の比較を行ったもの。左はJetson AGX Xavierの15WモードとVersal VE2302の比較、右はJetson AGXはMax N-ModeでVersalはVE2802を使っている。ただし縦軸はImages/sec/Wattであるので、電力あたりの比較にはなっている。この左側の比較ではVersalが3.3倍の性能、右側の比較では4.2倍の性能となっている

サマリであるが、AMD-Xilinxは7nmプロセスを使うVersal アーキテクチャのAI/MLチップを開発した。このAIE-MLチップは広い用途に適用でき、アプリケーション全体を加速することができる。また、この製品は前世代の製品に比べてTOPS/w性能が大きく改善している。
-

図16 AMD-XilinxはAI-MLに最適化したVersal Edge推論チップを開発した。用途が広くアプリケーションのすべての処理を加速できる。従来の製品に比べてTOPs/w性能が大幅に向上している