Hot Chips 30 - 16個のGPU接続を実現した小さな巨人「NVSwitch」(前編)はコチラ
DGX-2の構成
DGX-2システムの諸元を次の図にまとめる。16個のV100 GPUを持ち、FP64のピーク演算性能は125TFlopsとなっている。FP16のTensor計算の場合のピーク性能は2000TFlopsに達する。
ピークの消費電力は10kWで、10Uのサーバの重量は154.2kgである。
-

DGX-2システムの諸元。V100 GPUを16個搭載し、FP64のピーク演算性能は125TFlops。Tensorコアを使うFP16のディープラーニング計算では2000Tflopsの性能を持つ

DGX-2の内部構造を次の図に示す。基本的に8個のGPUを搭載するボードが2枚あり、上下に重ねられている。この図で側面が黒く見えているのがV100 GPUのヒートシンクである。
8個のGPUの左側に上に3つの白い球のようなものが付いた縦長の箱が6個あるが、これがNVLinkチップのヒートシンクである。NVSwitchの消費電力はそれほど大きくはないが、GPUを冷却して暖まった空気での冷却であるので、背の高い大きなヒートシンクが必要であるという。
そして、その左の6枚のオレンジの板が、上下のボードの6個のNVSwitchの間を直結するケーブルの役目をするコネクタ付きのプリント配線基板である。ただし、この図は次の写真とは一致していない。
-

DGX-2の構造を示す図。基本的に8個のGPUを搭載するボードが2枚でできており、12枚のコネクタ付きのプリント基板で上下のボードのNVSwitchを接続している

次の写真はNVIDIAの展示ブースで筆者が撮影したものであるが、上下のボードを接続するプリント板が6ペアの内、4ペア挿入された状態になっている。全部挿入しようとすると隣接する2枚のプリント板の間隔が狭く、やりにくいので、展示員がそこまでやらなかったのではないかと思われる。また、6個のNVSwitchチップはヒートシンクを取り外してチップが見える状態で展示されている。
-

DGX-2の2枚の8GPUノードの接続部の写真。12枚のコネクタ付きのプリント基板が使われているが、4リンク分の8枚だけが挿入されている。NVSwitchはヒートシンクを取り外し細長いチップが見える状態で展示されている

NVSwitchチップとGPUの間の配線は多少長くなっても、NVSwitchからプリント板のジャンパーケーブルのコネクタまでの配線は極力短くして、信号品質を改善するように配線したという。また、上下のボードを接続するコネクタは送信信号と受信信号を物理的にグループを分割して、配線やコネクタ部分でのクロストークノイズを減らしたという。
-

8GPUボードのNVLinkの接続部の配線。同一ボード内となるNVSwitchとGPUの間の配線が多少長くなっても、2枚のボードにまたがり、コネクタなどが間に入るNVSwitchとコネクタ間の配線を短くして伝送特性を改善するように配線を行った。コネクタは送信と受信の信号ピンのグループを分離し、クロストークノイズを減らしている

次の図に、16K×16Kの高速フーリエ変換をcuFFTで実行した場合の性能を示す。横軸はGPUの数で、緑線がDGX-2の半分のGPUでcuFFTを行った場合のFlops性能、青線がDGX-1での性能である。
FFTは計算の間で通信が多い計算であり、GPU間の通信性能が計算性能に大きく影響する。このため、DGX-1では4GPUを使用した場合は例外的に少し性能が上がっているが、それ以外のGPU数ではGPU数を増やしても1GPUの性能を下回っている。一方、NVSwitchで通信性能が向上したDGX-2の場合は、8GPUでの計算では1GPUの4倍程度の性能になっている。理想的なスケーリングではないが、それでもDGX-2の場合は、GPU数が増えるにつれて性能が上がるという結果になっている。
-
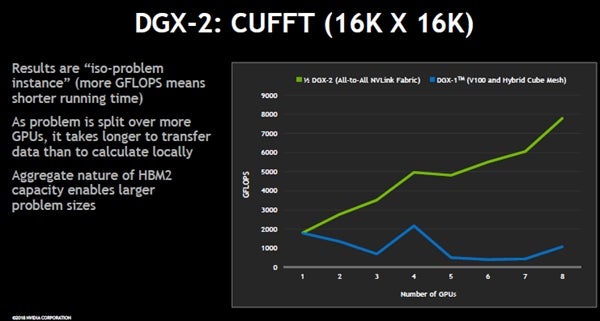
DGX-1とDGX-2でcuFFTを実行した場合の性能。横軸はGPU数である。DGX-1ではGPU数が増えても性能は上がらないが、DGX-2では8GPUを使うと1GPUの4倍に性能が向上している

次の図は、1台のDGX-2と2台のDGX-1(GPU数は同じ)で全ノードの計算結果の総和を計算して、全ノードに総和を配布するようなAll-Reduceで得られるバンド幅を比較したものである。メッセージサイズが512MBと大きい場合はDGX-1に比べてDGX-2は3倍高いバンド幅を示している。この差は1MBのメッセージサイズでは8倍に拡大している。これはDGX-2では全ノードのメモリが自由にアクセスが出来、オーバヘッドが小さいことが効いていると考えられる。
-

All-Reduceの性能比較。512MBの大きなメッセージの場合は、DGX-2は2台のDGX-1の3倍速い。メッセージサイズが1MBの場合は8倍速い

各種の実アプリケーションをDGX-2で実行した場合の性能と2台のDGX-1(GPU数は同じ)で実行した場合の性能との比較を次の図に示す。
DGX-2の方の性能は、物理計算であるMILCのベンチマークでは2倍、ECMWFの気象モデルの実行では2.4倍、AIのリコメンデーションの計算では2倍、言語モデルの処理では2.7倍の性能となっている。
なお、科学技術計算であるMILCの場合は、4Dグリッドの処理、気象アプリの場合はAll-to-Allの処理、AI計算であるリコメンデーションもReduceとブロードキャスト、言語モデルはAll-to-AllとNVSwitchによる16GPUの間の通信性能の向上が性能向上に効いているとのことである。
-

DGX-2を使うと、同じGPU数となる2台のGDX-1と比べて、科学技術計算のMILCは2倍、気象計算は2.4倍、AI計算であるリコメンデーションは2倍、言語モデルは2.7倍の性能が得られた

まとめであるが、DGX-2で導入されたNVSwitchは18ポートでノンブロッキングのNVLinkのスイッチである。NVSwitchは、ポート当たり51.5GBps(双方向合計)の通信バンド幅を持つ。18ポートのスイッチであるので、総バンド幅は928GBpsに達する。
DGX-2は16個のV100 GPUが1つのメモリをアクセスするようにプログラムを作ることができ、メモリ間のデータのコピーなどが不要となり、プログラムが作りやすくなる。このため、NVSwitchを使ったネットワークの採用でGDX-2では実アプリケーションの実行性能を2倍以上に引き上げることができた。
-

NVSwitchは18ポートのノンブロッキングのNVLink用のスイッチである。ポート当たり51.5GBpsの伝送速度を持つ。16GPUで512GBの共通メモリを持つ巨大GPUサーバを構成でき、HPCやAIの実アプリの性能を同じ数のV100 GPUを使うDGX-1の2倍以上に向上させる

この最後の、実アプリケーションの実行性能を2倍以上に引き上げたというところが重要で、半分以下の時間で計算ができるようになり、あるいは半分のV100 GPUで同じ計算ができるようになったという意味であり、NVSwitchの開発とDGX-2への組み込みで計算コストを半分以下に減らしたというのは大きな功績である。