Xilinxが7nm製品の詳細の一部をHot Chips 30で公開
2018年3月、Xilinxは7nmプロセスを用いて製造予定の新世代製品である「Project Everest」について、そのさわりだけを公開したが、2018年8月19日~21日に掛けて開催された「Hot Chips 30」(https://news.mynavi.jp/article/20180605-641780/)でこのProject Everestの詳細の一端が公開されたので、それを元に、読み解いていきたい。
ちなみにHot Chips 30での発表者はJuanjo Noguera博士であるが、博士の肩書は自身のLinkedInのProfileなどを見るとSenior Staff Research Engineer, Research Labsであるが、XilinxのリリースによればEngineering director, Xilinx Architecture Groupとなっている。
Project Everestの概要
さてProject Everest、実際には「ACAP(Adaptive Compute Acceleration Platform)」という名称で説明されているが、その概略については以前の記事を参照していただければと思う。
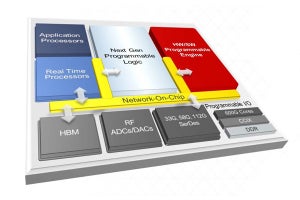
ただこの時点では、「HW/SWプログラマブルエンジン"の中身がまったく説明されなかった。まずその概略であるが、構成は先に書いた通りFPGAファブリックとProgrammable Engine、Processor Subsystem(+メモリ)、それとI/Oということになる。ただこのACAP、Machine Learningで20倍、5G基地局で4倍の性能を現行製品に比べて発揮し、しかも消費電力は40%低いとする(Photo01)。この概略図をもう少しブレークダウンしたのがこちら(Photo02)。S/W Programmable Engineとは実際には複数のSW Processor Elementの集合体だと判る
-

Photo01:これだけ見るとPSがI/Oと直結していないとか、いつの間にかH/Wの文言が消えてただのS/W Programmable Engineになっているとか色々不思議なところはあるが、高レベルの概略図ゆえの話であろう。ちなみに比較は現行の16nmプロセスを使ったVirtex UltraScale+あるいはZynq UltraScale+ MPSoCとなっている (出典:このレポートの図は、特に断りがないものについてはHot Chips 30における同社の発表資料のコピー)
-

Photo02:ちなみに説明の中では、すべてのブロックがすべてのACAP製品に搭載されているわけではなく、またSW PEもScaleする(つまり6個というのは単なる説明の都合)という話であった。また現時点ではProcessing SystemのOn Chip Memoryの詳細は不明。TCMの類だろうか?


Everestがターゲットとする機械学習と5G
さて、このSW Programmable EngineはDomain Specificだとされるわけだが、そのDomainとして何を考えているのか? 1つ目がMachine Learningである(Photo03)。Machine Learningの計算量の多さは、主に膨大な層のNetworkに対するConvolutionとPooling、Non-Linearityに起因するもので、これを専用プロセッサで処理することで負荷を大幅に軽減できるとする。
-

Photo03:さまざまなアプリケーションへのMachine Learningが検討されているが、精度を高めるためには計算量の増加は避けて通れない
-

Photo04:要するにMLというかDNNの処理(と、一部アプリケーション)を全部、S/W Programmable Engineにオフロードさせようという発想である


もう1つのDomainが5Gである(Photo05)。単にデータレートだけではなくLatency低減や高速ハンドオーバー、1つの基地局の収容する端末数などすべてが4Gから大幅な拡張を施されており、難易度は4Gの際の100倍に達する、とされる(Photo05)。
-

Photo05:一番厄介なのは、いまだに標準規格が進化し続けている("5G still evolving standard")事だろうか。だからFixed Functionとして実装できないことになる。これはMLというかDNNでも同じ話となる

ではこれをどうインプリメントできるのか? というのがPhoto06。DPD(Digital Pre-Distortion)のUpdateはプロセッサ側で処理するとして、DPDそのものとCPRIへのI/F(DUC:Digital Upling Conversion)をS/W Programmable Engineで、Digital RadioとADC/DACのAMS(Analog Mixed Signal)をI/Oでそれぞれ分散させるという形だ。ちなみに現行のUltraScale+ MPSoCを使って同じブロックを構成した例がPhoto07で、AMSがI/O Blockなのは同じとして、DPDはSoft I/Pの形でFPGAファブリックで実装されている。これをオフロードする形だ。
-

Photo06:これは上り方向の回路で、実際には下り方向むけにDDCを搭載したブロックが別に必要になる筈だが、このあたりは説明のために省いたと思われる
-

Photo07:実際にはCPU #1がDPD SWを動かしており、ここでDPD Updateの計算などが行われるものと思われる (この資料の出典は[「コチラ」]