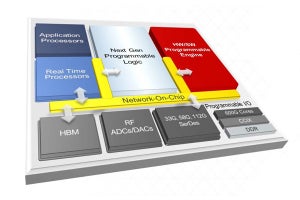
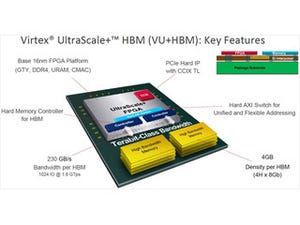
Processor Elementの内部を読み解く
さて、それではそのS/W Programmable Engineを構成するProcessor Elementの内部はどんな形なのか? というのがこちら(Photo08)である。
-
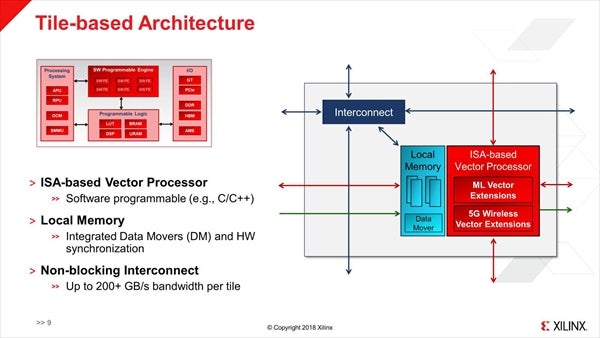
Photo08:タイルベースのVector Processorのマルチコアという、ある意味Special Processorでは基本の様な構成。各PEは通信と計算を同時に行える、という話だった

何というか良くありがちな構成ではあるのだが、面白いのはInterconnectを構成するRouterとは別に、Processor Elementそのものが相互接続されているという形はちょっと面白い。この直結がLocal Interconnect、Router経由がGlobal Interconnectと考えると、このあたりはFPGAの基本構成をそのまま踏襲している感じもある(Photo09)。
-
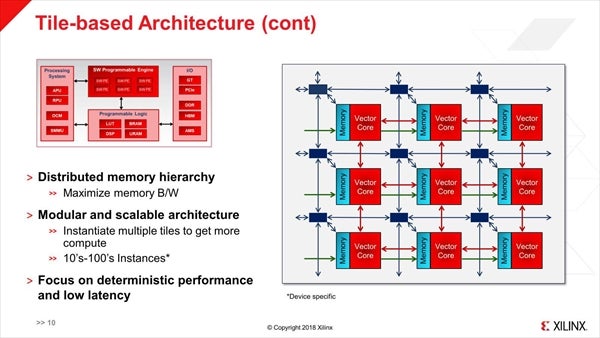
Photo09:ただ赤はBi-Directional Signalingなのに、緑はUni Directional Singnalingというのが気になる部分

これを利用して、Simple PipelineやGraph、Multicastingなどさまざまな接続形態が可能とされる(Photo10)。FPGA Fabricとの接続は、途中にCDC(Clock-Domain Crossing)というユニットを介することで可能であり(Photo11)、また外部のAcceleratorあるいはオンチップメモリへの接続も可能だそうだ(Photo12)。
-
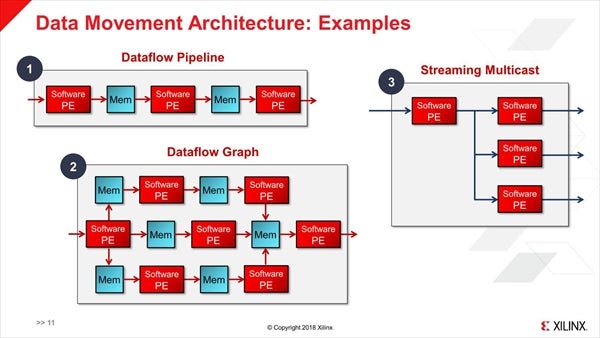
Photo10:Feedback(戻る方向)のPathも同様に組めるのかは不明。またいわゆるBroadcasting(すべてのPEへのMulticast)が可能なのかも不明。Router経由でならBroadcastが可能な気はするが
-
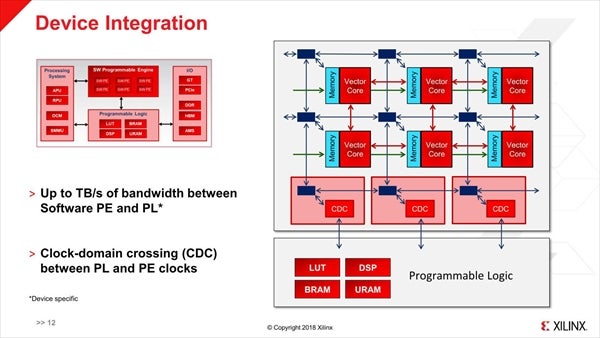
Photo11:CDDはいわばMailboxみたいなイメージになるのではないかと思われる。FPGA FabricとS/W Programmable Engineの間は、最大でTB/secの帯域が確保されるそうである
-
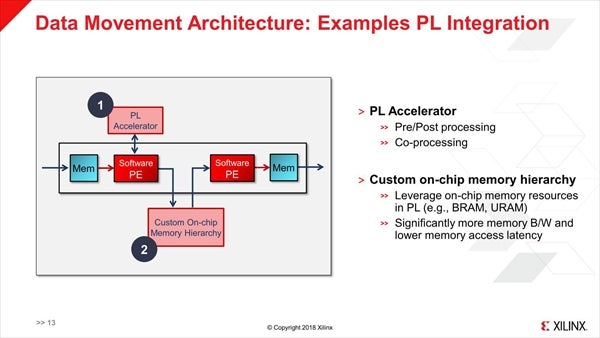
Photo12:そのPL AcceleratorはFPGA Fabric側で構築することになるとか。Custom On-chip Memoryの方は、Photo02でいうところのOCMに加えてFPGA Fabric側のBRAM/URAMも利用できるようだ



さて、肝心のVector Processorがどんなものか? という説明は今回はなし。またPhoto08でいうところのML Vector Extensions/5G Wireless Vector Extensionsについても説明はない。とりあえず説明の中では、キャッシュは持たないという話であり、Local MemoryがTCMのような形で動作するのだと思われる。
また複数のサイズのFloating Pointをサポートする(Fixed Pointではない)という話ではあったが、それ以上の話は公開されなかった。その代わりといっては何だが、開発環境についての説明があった。基本的にPSとS/W Processor Engine、FPGA Fabricの3つをまとめて高レベルのC/C++で記述する事も可能だし、そこからもう一段下の、直接S/W Processor Engineに対してのプログラミングも可能とされる(Photo13)。また統合開発環境とライブラリ、ランタイムが提供されるとのことである(Photo14)。
-
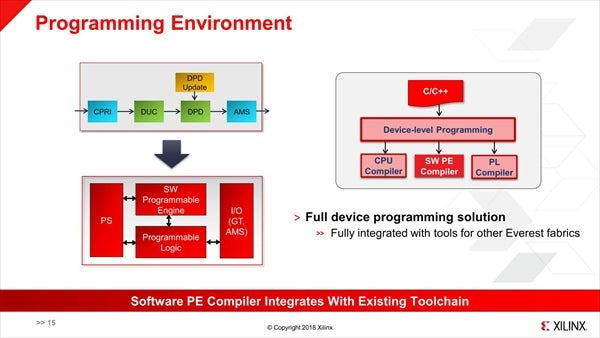
Photo13:はっきりとは確認できなかったが、おそらくS/W Programmable Engineを直接触る場合もC/C++でのプログラミングになる模様。ちなみにVector Compilerが提供されるのか? という質問に対して「そうではなく、別の方法を考えている」という返事があった
-
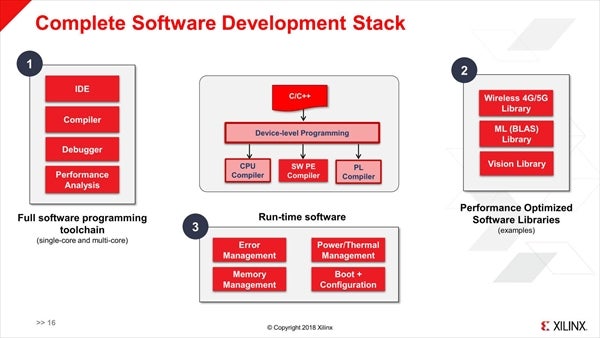
Photo14:もちろんこれはS/W Programmable Engineに対してという話で、Processor Subsystem(やFPGA Fabric)向けにはそれぞれ別のToolchainやLibrary、Runtimeが提供されることになるだろう


また、特にMachine Learningについては既存のフレームワークをシームレスにサポートする、としている(Photo15)。このライブラリ類を利用した場合、MLや5Gなどで高い性能を実現できる、という話であった(Photo16 )
-
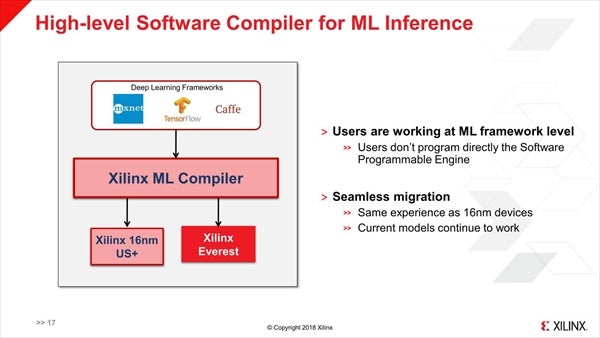
Photo15:EverestだけでなくUltraScale+製品も同様にサポートするというあたり、ML Compilerの中で何かしらをやっているのだと思われる。サポートするフレームワークが全部で幾つあるのか、などは今回は公表されなかった
-
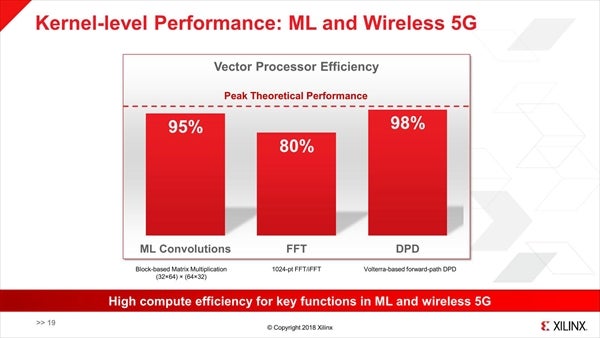
Photo16:ML ConvolutionsとFFTはML Library(というか、BLAS)を利用した場合、DPDはWireless 4G/5G Libraryを利用した場合の結果であろう


現時点での説明はこの程度で、一番肝心な部分が抜けている感もあるが、1つ推察すると3月の説明で内部接続がNoC(Network on Chip)になっていたのは、おそらくS/W Programmable EngineのPE同士の事を指しているのではないかと思われる。ただそうだとしても、まだ全貌は見えていないというところだ。Photo01の一番下にあるように、この製品は今年後半にTape Outという話で、早ければ来年の6月位にはFirst SiliconのαSamplingが始まるだろう。
なお、Xilinxは2018年10月にプライベートカンファレンス「XDF(Xilinx Developer Forum)」をサンノゼ・北京・フランクフルトで開催予定である。ここでもう少し細かい話が出てくることを期待したい。