クレジットカードの利用明細はこまめにチェックする必要があるが、専用サイトにログインして明細をダウンロードするのは面倒だ。そこで、自動でダウンロードするプログラムを作ってみよう。前回に引き続き今回は、実際に会員制のサイトにログインして、リンクをクリックしてデータをダウンロードするプログラムを作ってみよう。
-
会員制のWebサイトにアクセスしてデータをダウンロードするプログラムを作ろう

Webブラウザを操作する方法の復習
前回、Google Chromeを自動操縦するために、SeleniumとChromeDriverをインストールした。これを利用することで、ChromeブラウザをPythonから本格的に操作できる。Chromeを実際に操作するため、セッション機能を利用した会員制のサイトや、JavaScriptが多用されている動的なサイトにもアクセスできる。まだ、インストールしていなければ、前回の内容を確認しておこう。
また、今回データをダウンロードするのにrequestsモジュールも利用するので、コマンドラインから以下のコマンドを実行してインストールしておこう。
pip install requests
会員制のサイトからデータをダウンロードしよう
それでは、今回は会員制のサイトにログインして、データをダウンロードしてみよう。実際のところ、利用しているクレジットカード会社のWebサイトによって、ログインの方法や明細データの取得方法が異なる。そのため、ここでは、ダミーサイトを利用して、練習する方法を紹介しよう。
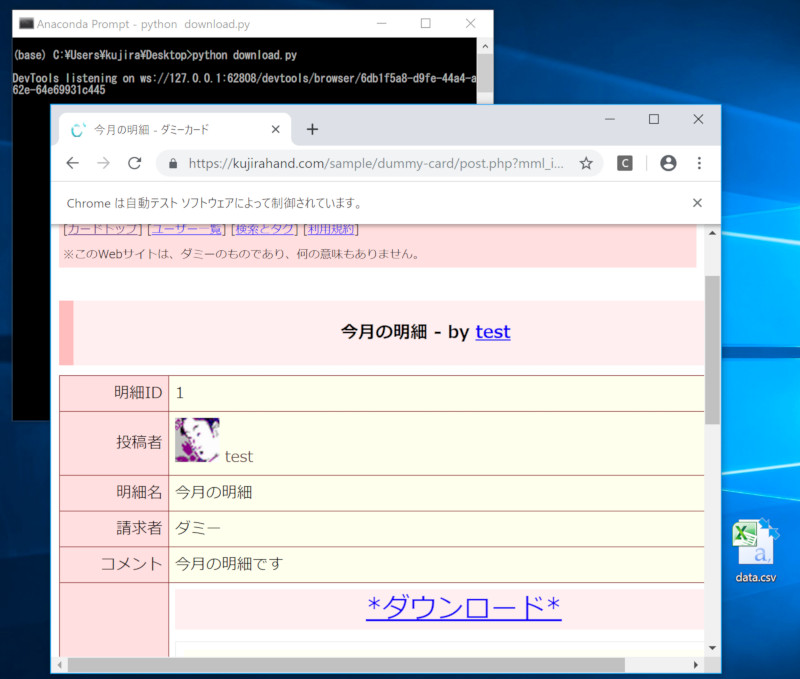
今回、練習用にこちらのダミーサイトを用意した。このダミーサイトから自動で明細データをダウンロードするプログラムを作ってみよう。
まず、以下のサイトにアクセスしてみると、「ログインしてください」とだけ表示される。ログインIDに「test」、パスワードに「pwpw」と指定してログインすると、下記のような明細確認画面が見られる。
-
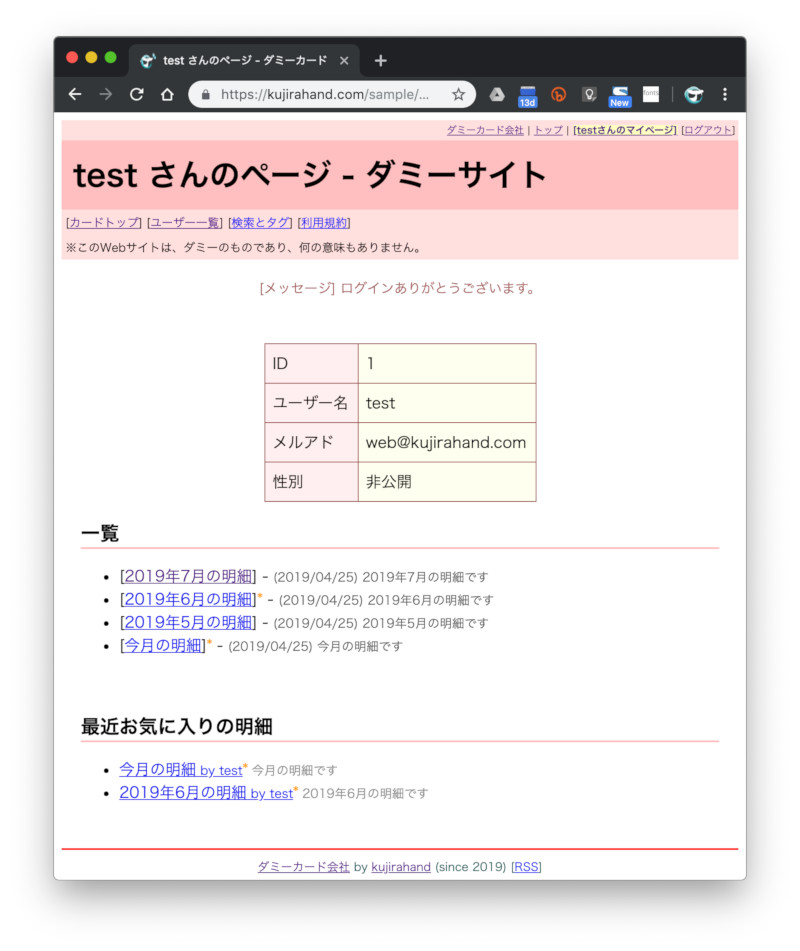
ログインが必要なダミーサイト

それでは、この練習用のダミーサイトにログインし、今月の明細のリンクたどって、データをダウンロードするプログラムを作ってみよう。以下がPythonのプログラムだ。「download.py」という名前で保存しよう。
import time, os, requests
from selenium import webdriver
import chromedriver_binary
# パスワードの指定
user_id = "test"
password = "pwpw"
download_dir = os.path.dirname(__file__)
# 保存先などオプションを指定してChromeを起動 --- (*1)
opt = webdriver.ChromeOptions()
opt.add_experimental_option("prefs", {
"download.default_directory": download_dir,
"download.prompt_for_download": False,
"plugins.always_open_pdf_externally": True
})
driver = webdriver.Chrome(options=opt)
# カード会社のページを開く
driver.get('https://kujirahand.com/sample/dummy-card/')
time.sleep(3) # ページが開くまで待つ
# ログインページを開く --- (*2)
tag = driver.find_element_by_link_text('ログイン')
tag.click()
# ログイン画面のユーザー名にキーを送信 --- (*3)
u = driver.find_element_by_name('username_mmlbbs6')
u.send_keys(user_id)
# ログイン画面のパスワードにキーを送信
p = driver.find_element_by_name('password_mmlbbs6')
p.send_keys(password)
p.submit()
time.sleep(3) # ページが開くまで待つ
# 今月の明細のページを開く
tag = driver.find_element_by_link_text('今月の明細')
tag.click()
# データのダウンロードリンク先を取得 --- (*4)
tag = driver.find_element_by_link_text('*ダウンロード*')
href = tag.get_attribute('href')
# Chromeからクッキーデータを得る --- (*5)
c = {}
for cookie in driver.get_cookies():
c[cookie['name']] = cookie['value']
# requestsを利用してデータのダウンロード --- (*6)
r = requests.get(href, cookies=c)
with open("data.csv", 'wb') as f:
f.write(r.content)
# 結果を30秒表示して終了する
time.sleep(30)
driver.quit()
そして、以下のコマンドを実行すると、Chromeが起動し、ログインしデータをダウンロードする。
python download.py
実行すると、Chromeが起動し、ダミーサイトにアクセスが行われる。ログインページが表示され、ユーザー名やパスワードが書き込まれ、ログインする。そしてリンクがクリックされデータがプログラムと同じディレクトリにダウンロードされる。
-
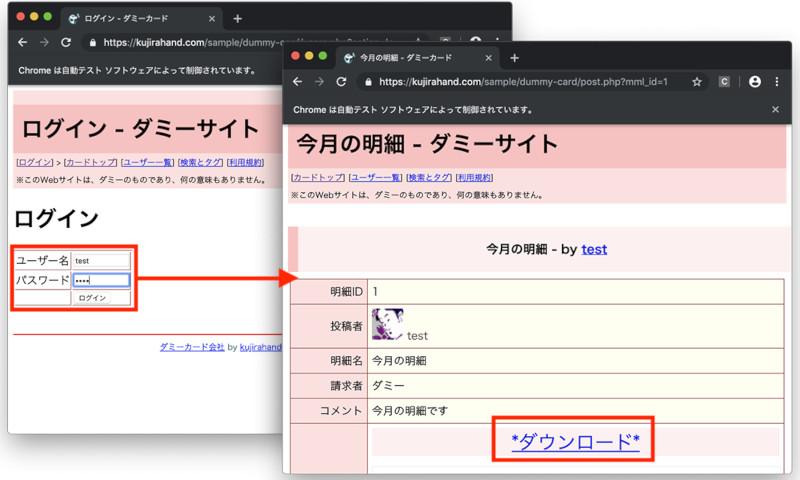
自動的にサイトにログインし明細データをダウンロードする

それでは、プログラムを確認してみよう。
(*1)では、データの保存先ディレクトリを指定している。ここでは、プログラムと同じディレクトリにデータを保存するようにしている。このように指定すると、Chromeの機能を利用してダウンロードする際に、自動的に任意のディレクトリに保存できる。
ただし、macOSではこの機能が正しく動いたのだが、残念ながらWindowsでは正しく動かなかった。そのため、プログラムの(*5)(*6)で指定しているように、requestsを利用してChromeとは別でデータをダウンロードするようにした。
(*2)の部分では、「ログイン」と書かれたリンクを取得し、そのリンクをクリックするように指示している。find_element_by_link_textメソッドでリンク先のオブジェクトを取得し、clickメソッドでクリックする。これによってページが遷移する。
(*3)の部分では、ログインフォームにテキストを書き込んでフォームを送信する。これで、ログイン処理が行われ画面が遷移する。前回の連載を参考に、Chromeの開発者ツールでユーザー名とパスワードのテキストボックスのname属性を確認してみると良いだろう。
(*4)の部分では、「ダウンロード」と書かれたリンクを得て、リンク先の情報を取得している。
そして、(*5)の部分では、Chromeからクッキーの情報を取得し、(*6)の部分でrequestsを利用してデータをダウンロードする。
一般的に会員制のサイトでは、セッションの情報を利用してログインしているかどうかを判定しているので、Chromeからクッキーの情報を得て、requestsに受け渡すことで、Chrome以外の方法で会員だけに許されているデータがダウンロードできるようになる。
まとめ
以上、前回と今回でPythonでChromeブラウザを自動操縦する方法を紹介した。今回は特にログインの必要な会員制のサイトにログインする方法と、データをダウンロードする方法を紹介した。
このような方法でWebブラウザを操作する場合、基本的にブラウザでできることは何でもできる。ブラウザ内の要素に対して、任意のキーを送信したりクリックしたりできる。その際、リンクを表示ラベルで取得したり、HTMLタグに付与されているidやname属性で取得できる。ブラウザ内に表示されている要素を検索するメソッドがSeleniumのマニュアルにまとまっているので参考になる。
ただし、注意点もある。このようなプログラムを利用することで、Webサーバーに負荷を与えてしまうこともある。画面遷移やデータの送受信の際には、time.sleepを利用して一定時間の間隔を空けるように心がけよう。また、プログラムからのアクセスを禁止しているサイトもあるので利用規約も確認する必要があるだろう。
また、クレジットカードの明細以外でも、会員制のWebからデータを取得したい場面は多いので、今回のプログラムを参考にWebブラウザの操作を自動化してみよう。
自由型プログラマー。くじらはんどにて、プログラミングの楽しさを伝える活動をしている。代表作に、日本語プログラミング言語「なでしこ」 、テキスト音楽「サクラ」など。2001年オンラインソフト大賞入賞、2004年度未踏ユース スーパークリエータ認定、2010年 OSS貢献者章受賞。技術書も多く執筆している。