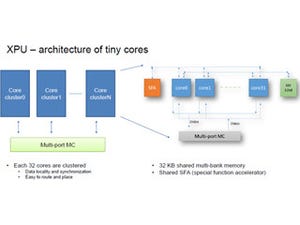
Infinity Fabricはチップ内のデータプレーンとコントロールプレーンの接続を行う。また、Infinity Fabricは、MCM上のチップ間、パッケージ間の接続にも使われる。

|
|
Infinity Fabricはチップ上のコントロールプレーンとデータプレーンを接続する。また、Infinity Fabricは、MCM上のチップ間の接続、プリント板上のパッケージ間の接続にも使われる |
また、Infinity Fabricはメモリとの接続も行う。パッケージ全体では8本のDDR4チャネルがあり、各チャネルには2枚のDIMMを接続できる。最大データ転送速度は2667MT/sであり、チャネル当たりのバンド幅は21.3GB/s、ソケット当たりでは171GB/sのバンド幅になる。

|
|
4チップ合計で8 DDR4メモリチャネルを持つ。最大2667MT/sの転送をサポートし、チャネル当たりのバンド幅は21.3GB/s。8チャネル合計では171GB/sとなる |
Infinity Fabricはキャッシュコヒーレントなネットワークであり、MCM上の4チップはどのチップにも1ホップで届くフルコネクトで接続されている。各リンクは42GB/sの双方向バンド幅を持ち、約2pJ/bitの電力で信号を伝送できる。MCM上の信号配線は短いので、シングルエンドで伝送を行っており、データを伝送していない時の消費電力を抑えている。
この構成で、メモリバンド幅を測るSTREAM TRIADで145GB/sの性能を達成している。MCM上のInfinity Fabricは171GB/sのバイセクションバンド幅を持ち、これはSTREAM TRIADの実行に必要なバンド幅の2倍と十分に余裕を持った設計になっている。

|
|
4チップはキャッシュコヒーレントなInfinity Fabricでフルコネクトで接続されている。リンクの伝送速度は双方向合計で42GB/sである。STREAM TRIADで145GB/sを実現している |
I/O接続には、1ソケットあるいは2ソケットのシステムでは、x16のリンクを8本持っている。このリンクは、Infinity Fabric、PCIe、あるいはSATAとして使用することができる。このx16のリンクをPCIeとして使う場合は、最大8本のPCIeに分割して使用することができる。ソケット間のx16リンクのバンド幅は32GB/sとなっている。MCM上のInfinity Fabricでは42GB/sのバンド幅であるが、ソケット間は配線も長くなるので、伝送速度をある程度落としていると考えられる。

|
|
I/O接続には合計8本のx16リンクが用意されている。1リンクの伝送速度は32GB/sとなっている |
1ソケットのEPYCシステムのI/O接続は、128レーンのPCI Expressを持っており、PCIeスイッチを使わなくても、十分な数のPCIe接続ができる。そして、EPYCのリンクは、Infinity Fabric、PCIe、SATAのいずれとしても使用できる。
プロセサあたり4つのI/Oハブを持ち、PCIeのPeer-to-Peer転送をサポートする。メモリ接続は8本のDRAMチャネルを持ち、最大16DIMMを接続できる。
したがって、右側の図のように、1ソケットのEPICプロセサに6台のGPUとNIC 1枚、8台のSATAドライブを接続し、16枚のDIMMを接続するというシステムを作ることができる。これは驚異的なI/O接続能力である。

|
|
EPYCは128レーンのPCIeを持ち、PCIeスイッチを使わなくとも、6台のGPU、1枚のネットワークインタフェースカードと8台のディスクを接続するシステムが作れる |
次の表はx16のPCIeのデータ伝送速度の測定結果をまとめたもので、DMAでのローカルメモリのデータ転送はReadが12.2GB/s、Writeが13.0GB/s、両者を合わせた場合は22.8GB/sのバンド幅となっている。PCIeのピークバンド幅は名目上16GB/sであるが、プロトコルオーバヘッドを考えるとその85%~95%が実用的な上限である。EPYCでは、これに近い性能が得られている。また、チップ間をInfinity Fabricで転送する場合はそれぞれ12.1GB/s、14.2GB/sと22.6GB/sが得られている。
また、1PのEPYCシステムに24台のディスクをPCIeのx4で接続することができ、32コアを使った場合、9.2MIOPsが得られている。

|
|
1ソケットのEPYCシステムのPCIeのバンド幅測定結果。ローカルDRAMとのDMAはReadで名目ピークの76%、writeで81%の性能が得られている。PCIeのプロトコルオーバヘッドがあるので、最大でも85%~95%の性能が上限であり、この測定ではそれに近い、かなり高い値が得られている |
EPYCは性能優先、あるいは電力優先という電源設定ができるようになっている。製造されたシリコンチップにはバラつきがあり、速度は速いが漏れ電流が大きいもの、速度は遅いが漏れ電流が小さいものなどができる。結果として製品のTDPが180Wの場合、最低では165Wから最大では200Wまで電力がバラつく。
また、どのような環境でも一定の性能が得られることを要求するユーザと消費電力一定で最大の性能を望むユーザがある。EPYC CPUでは、どちらの設定にするかをブート時に選択することができる。
性能一定の設定では、右の上側の図のように、システムやシリコンのマージンが大きいチップでは電源電圧を下げるので、消費電力が減少する。一方、電力一定で性能を最大にする設定では、右の下側の図のようにシステムやシリコンのマージンが大きいチップではクロックを上げて、最大50%程度高い性能が得られる。

|
|
EPYCでは、性能一定と電力一定という2つの電源制御モードがあり、ブート時に選ぶことができるようになっている |
すべてのチップに、最も遅いチップが必要とする電圧の電源を供給するのは、電力を浪費することになる。そのため、EPYCでは各コアにLDO(Low Drop Out)レギュレータを持たせて、コアごとに最適な電圧を供給している。これにより、コア電力を削減し、バラつきの影響を減らすことができる。
CMOSチップの消費電力は電源電圧の2乗に比例するが、LDOレギュレータの場合はレギュレータ自体のロスがあるので、2乗ではなく1乗にしか比例しないが、それでも高速のチップの供給電圧を指定の速度で動かせる限界までLDOで下げることにより、チップの消費電力を減らすことができる。

|
|
EPYCではコアごとにLDOレギュレータを持ち、電源電圧を最適な値に調整し、消費電力を減らしている |
次の右上の図はSTREAM TRIADの性能で、左側の棒グラフがXeon E5-2690 v4、右側の棒グラフがEPYC 7601の性能を表す。2ソケットのXeon E5-2690 v4と比べて1ソケットのEPYC 7601は24%高いSTREAM性能を持っている。また、2ソケットのEPYC 7601はスコアが97%上がっており、ほぼ完全なスケーラビリティを示している。この結果、2ソケット同士で比べるとEPYCはXeonより146% STREAM性能が高い。下の表はSPECINTとSPECFPの性能を比較したもので、EPYCは、2PではSPECINTでは25%、SPECFPでは59%高い性能を示している。そして、1Pでは、この差はもう少し大きくなっている。
EPYCは、メモリバンド幅が大きく、コア数も多いので、これは理解できる結果である。
なお、この比較はEPYCではOpen64コンパイラ、XeonはICCコンパイラを使った結果であるが、表の一番下のGCCでコンパイルした場合は、スコアは半減するが、EPICとXeonの性能比率は同じ傾向である。

|
|
EPYC 7601とXeon E5-2690 v4のSTREAM TRIADとSPECINT、SPECFP性能の比較 |
ということで、AMDのEPYC 7000プロセサは、エンタープライズやデータセンターのTCOを下げることを狙ったアーキテクチャのプロセサである。EPYCは最大32個のZenコアを搭載し、8本のDDR4メモリチャネルを持ち、最大2TBのDRAMを接続できる。また、128レーンのPCIeをサポートしている。
また、専用のセキュリティサブシステムを備えている。そして、次世代のEPYCともソケット互換であるとアナウンスされた。

|
|
EPYCはエンタープライズやデータセンター向けに設計されたプロセサであり、最大32 Zenコアを搭載し、8本のDDR4 DIMMチャネルと128レーンのPCIeを持つ。そして、次世代のEPYCでもソケット互換が維持される |
AMDのEPYCプロセサはMCM上に4チップ搭載し、それらをInfinity Fabricで接続するという方法で、IntelのXeonチップより多くの資源を持つ強力なプロセサをより安いコストで実現している。結果として、EPYCプロセサはIntelのXeonより高性能なプロセサをより安価に提供することができている。そのため、Xeonキラーの強力な競争相手になると思われる。