


最後のポジショントークは、ローレンスバークレイ研究所に所属し、Top500委員会の一員でもあるErich Strohmaier氏である。
Top500に対する主要な批判の第1は、Top500は浮動小数点演算に偏っているというものである。HPL(High Performance Linpack)はO(n3)の計算をO(n2)のデータ移動で実行する。計算のByte/FlopはO(1/n)であり、nは歴史的に増加してきており、メモリバンド幅が軽視されることになっている。
第2の批判は、HPLは実際のワークロードを代表していないという点である。第3の批判は、HPLは直感的なランキングとは異なる順位をつけることがある。そして、第4の批判は、HPL性能は高いがそれ以外の用途にはあまり役に立たないスタントマシンを簡単に作ることができ、設計の指針として役立たない(あるいは有害である)という点である。
-

Top500とHPLに対する批判。現代のスパコンの使われ方と一致していない問題を解いており、Top500の好成績が、高性能のスパコンを意味しない

これだけの批判にも関わらず、なぜ、Linpackがこれほどうまくいっているかというと、
- 問題の規模を簡単に、連続的にスケールできる
- システム規模、問題規模ともに、最高の性能に漸近する。また、長期トレンドとも一致する
- システム規模、問題規模ともに下方に突の性能カーブになる。このため、安全な補間ができる
からである。
-

Linpackは容易にスケールができ、最高性能に漸近的な結果が得られるので、使いやすい

Linpackを補完する追加のベンチマークを選ぶ場合の基準は、
- 現実の計算を代表するものであること
- 問題規模に対するスケーリングが容易なこと
- システム規模、問題規模ともに漸近的に最適性能になること
- 主要な性質がO(n)でスケールすること
- Byte/FlopがおおよそO(1)であること
- ランキングの順序がTop500とは異なるものであること
- ただし、その順序は常識と一致するものであること(?)
- Top500と比較してかなり大きな順序の変更が起こること
- そうでなければ、新たなベンチマークを追加する意味がない
- 既存のベンチマークと強い相関を持たないこと
- ベンチマーク専用マシンを作りにくくすること
追加候補のベンチマークであるが、HPCGはHPLと同じくAx=bを解くのであるが、Aが巨大な疎行列である点が異なる。現在では4レベルのMulti-Gridのプレコンディショナーを使う。計算はByte/Flopが>~4でO(1)となる。グローバル通信はO(n2/3)となる。
そして、計算にはSparse matrix-vector multiplication、Sparse triangle solve、Vector updates、Global dot products、Local symmetric Gauss-Seidel smootherなどが使われる。HPCGベンチマークの結果を提出するシステムは約60システムになっており、ある程度、定着してきたと言える。
-

Linpackの補完ベンチマークの候補のHPCGは疎行列の係数行列を持つ巨大連立1次方程式を解く

また、可変係数のポアソン方程式を解くHigh Performance Multi Grid(HPGMG)というベンチマークも提案されている。
次のグラフはHPL、HPCG、HPGMGベンチマークの値をピーク浮動小数点演算性能に対するパーセンテージで表したものである。横軸はTop500のランキングである。
HPLはランクとあまり関係なく30%から90%くらいの範囲に分布している。一方、HPCGは1桁のパーセンテージである。HPGMGはデータが少ないが最大で32%程度になっている。
-
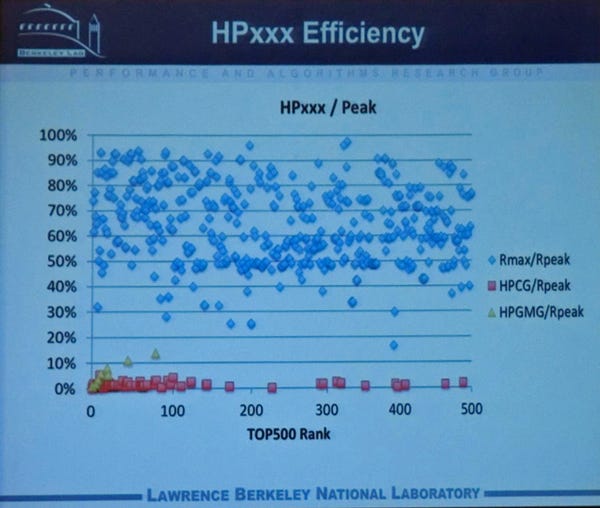
HPL、HPCG、HPGMGの性能のピーク浮動小数点演算性能に対する比率をプロットしたもの。横軸はTop500の順位

HPCGとHPGMGの性能のグラフの横軸をByte/Flopにしたのが次のグラフである。HPCGのグラフは傾きが0.3242、HPCGのグラフの傾きは0.0926である。
-
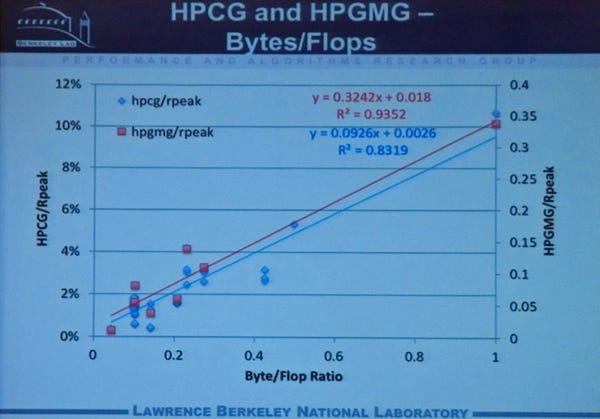
HPCGとHPGMGの性能のピーク浮動小数点演算性能に対する比率。HPCGは左の目盛、HPGMGは右の目盛であるので注意。横軸はByte/Flopになっている

これにHPLも加えたグラフは次のようになり、これはRooflineのグラフである。HPLの場合はすべてのシステムが演算性能リミットの領域での測定になっている。一方、 HPCGとHPGMGではByte/Flopが1以下の領域では、メモリバンド幅で性能が制約されている。
-
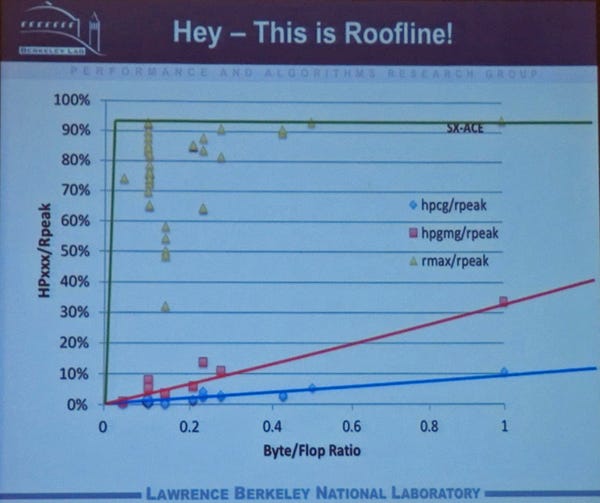
HPLも加えた図で、これはRooflineの図である。HPLは演算性能リミットの領域での測定であるが、HPCG、HPGMGはメモリバンド幅リミットの領域での測定になっている

結論であるが、HPLの必要とするメモリバンド幅はO(1/n)であり、これは現実のアプリケーションとはかけ離れている。一方、HPCGとHPGMGはO(1)であり、グラフでもB/Fに比例した性能になっていることが分かる。これはメモリバンド幅が大きな影響をあたえるという点で、HPLに比べて実アプリケーションに近く、改善されている。
しかし、例えばネットワークレーテンシやネットワークバンド幅など、浮動小数点演算性能とメモリバンド幅以外のアーキテクチャ的な性能がどのような影響を及ぼしているかについてはより多くのデータを集めて分析する必要がある。
-

HPLのメモリバンド幅の必要性は現実のアプリケーションとはかけ離れている。HPCGとHPGMGは問題規模に比例して必要メモリバンド幅が大きくなっており、現実に近い。ネットワークのレーテンシやバンド幅など他のアーキテクチャ要素がどのように影響するかについてもっとデータを集める必要がある

これらのポジショントークの後、質疑が行われた。平木先生は、Strohmaier氏の資料がrpeak(ピーク浮動小数点演算性能)で正規化されているが、浮動小数点演算器の面積はそれほど大きくないので、rpeakはある程度自由に選べるパラメタであり、これで正規化するのは妥当でないのではないかと質問していた。
この指摘は正しいが、システムの規模の違いを吸収する何らかの正規化は必要である。チップ面積で言えば、キャッシュの容量で正規化すべきかもしれないが、それも適当とは思われない。ことほど左様に公平な比較は難しい。
そして、最初に平木先生が掲げたZetta Flopsマシンの設計や量子コンピュータのベンチマークについての議論は行われず、次回以降のBoFに持ち越しとなった。
筆者の私見であるが、浮動小数点演算性能とメモリバンド幅が、性能を決める2つの重要な要素であるというのは正しいと思われる。しかし、牧野先生が指摘されたように、京コンピュータやポスト京では、これら以外の要素が性能制約になるケースが多かったとすると、その要素が何であるかを明らかにして、それを測定するベンチマークを含める必要がある。その結果、見通しが良く、スケーラブルなベンチマークが作れるかどうかは、別問題である。
このように考えてくると、主要な性能制約要素をカバーして、スケーラブルでZetta Flopsマシンの設計に使えるベンチマークを作るのは至難の業であるという気がする。
HPLのように、実アプリの性質とは離れてきてしまったが、スケーラブルで長期の傾向が追跡できるベンチマークとか、スケーラブルではないが、実際に使用するアプリケーション群の性能に近い各種の測定を行うシステム調達用ベンチマークとか、用途ごとに区別してベンチマークを作るということも必要ではないかと思う。













