マイクロベンチマーク
通常のベンチマークプログラムは、アプリケーションの使用状態の性能を調べ、他のプロセサと性能を比較できるようにするのが目的である。しかし、この研究では、プロセサのマイクロアーキテクチャを調べるためにその目的に合わせたプログラムを専用に作っており、マイクロアーキテクチャを調べるプログラムをマイクロベンチマークと呼んでいる。
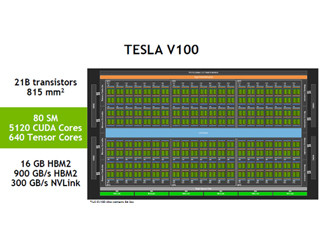
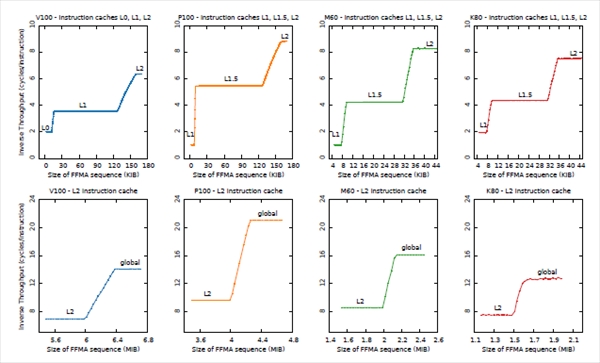
次の図は4世代のGPUの命令キャッシュのスループットを測定した結果で、グラフの縦軸はスループットの逆数で、1命令のアクセスに平均何サイクルかかるかという値になっている。
左上のグラフはV100の測定結果で、L0キャッシュがヒットしている範囲では2サイクル/命令となっている。しかし、測定のために作ったFFMA命令の列の長さが12KiBを超えるとサイクル/命令が増加し始めている。このことからL0命令キャッシュの容量は12KiBであることが分かる。
さらに、L1命令キャッシュがヒットしている領域では4サイクル/命令より少し小さい値であり、この領域が128KiB程度まで続く。これを超えると、サイクル/命令は上昇し始め6サイクル/命令を超える値になる。
左端の下の段のグラフはFFMA命令の列が6MiBを超えるとL2キャッシュのミスが発生し始め、グローバルメモリがアクセスされてサイクル/命令が増加し始める。そして14サイクル/命令程度になる。
このグラフを見ると各レベルの命令キャッシュの容量とバンド幅を知ることができる。
これは一例であるが、キャッシュをヒットする条件、容量不足でミスが発生する条件などを明示的に作ることが重要で、マイクロアーキテクチャを知らないと適当なマイクロベンチマークは作れず、鶏と卵で、試行錯誤の開発になる場合もある。
-
4世代のGPUの命令キャッシュの容量とバンド幅を調べるマイクロベンチマークを作って測定した結果

Voltaのレジスタファイルはバンク化されていた
次の図は、積和演算の実行時間を測定した結果で、R97×R99にRxを加算するコードを、Rxを100から120まで変えて実行させた場合の計算時間を測定している。次の図の右下の折れ線グラフに示すように、Rxが偶数番号のレジスタの場合は4μs程度で計算できているが、Rxが奇数になると実行時間が4.6μs程度に増加している。
これは、レジスタファイルが2バンク構成になっており、バンク0には偶数番号のレジスタ、バンク1には奇数番号のレジスタが割り付けられているが、各バンクから同時に読み出せるのは最大2つのオペランドという制限があるからであるという。
この例ではR97とR99のアクセスのためにバンク0から2つのオペランドの読み出しが行われている。Rxもバンク1の奇数番号のレジスタとすると、バンク1から3つのオペランドを同時には読めないので、次のサイクルにバンク1からRxを読み出すことが必要になり、計算時間が長くなってしまう。一方、Rxをバンク0側のレジスタとすると、3つのオペランドを同時に読み出せるので、2回目の読み出しサイクルは必要なく、計算時間を短くすることができる。
なお、このようなマルチバンク構成のレジスタファイルはこれまでのKepler、Maxwell、Pascal GPUでも使われていたという。ただし、これらのGPUでは4バンク構成と自由度が高かったという。
-
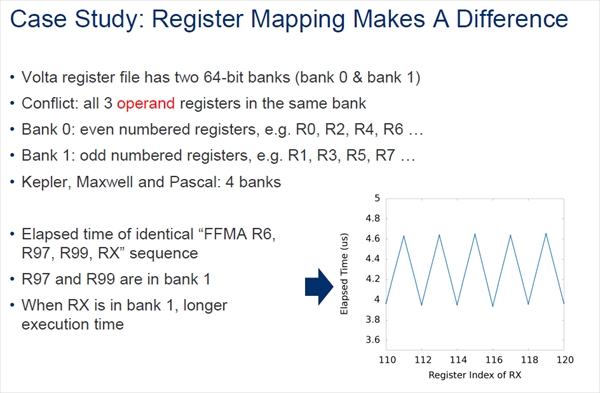
右下のグラフは、Rxのレジスタ番号を100~120まで変化させたときの計算時間をプロットしたもので、Rxが偶数の場合は約4μs。奇数の場合は約4.6μsとなっている。レジスタファイルが2バンク構成になっており、バンク衝突が起こると、レジスタファイルを2回読み出す必要があり、約0.6μs計算時間が長くなっている

レジスタファイルにはリユーズキャッシュが付いている
また、VoltaにはReuse Cacheというメカニズムがあるという。Reuse Cacheは4エントリと小容量であるが、レジスタファイルと同列にオペランドのアクセスを行うことできる。前の例でR97とR99をバンク1から読んでいる場合でもR101をバンク1から読むのではなく、この値がReuse Cacheに入っていれば、R101.reuseから読み出せば、1つのバンクからは最大2つの読み出しという制約には引っかからない。
なお、命令は最大4つのオペランドを持つが、各オペランドに対応するフラグを持ち、フラグがセットされていると、そのオペランドレジスタの値をReuse Cacheに格納する。
次の図の左側のアセンブラコードはNVCCが生成した最適化前のコードで、右側は最適化を行ってReuse Cacheの使用を増やしたコードである。左のコードでは少数であるがReuseを使ってない命令があるのに対して、右のコードでは半分の命令が2つのオペランドでReuse Cacheを使っており、レジスタファイルのバンクコンフリクトで計算時間が延びるケースを減らしている。
この結果、左のコードと比較して、右のコードの性能は15.4%向上したという。
-
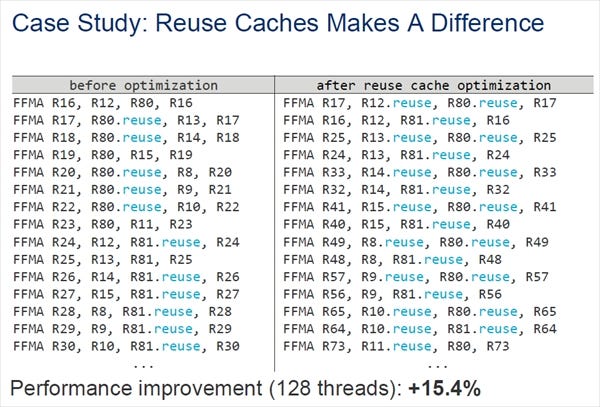
左はNVCCでコンパイルしただけのコード。半分のFFMA命令で1つのreuse付きのオペランドがあるだけ。一方、右のレジスタの割り付けを最適化したコードではreuse付きのオペランドが多く、レジスタファイルのバンクコンフリクトによる性能低下が少なくなっている

(次回は5月29日に掲載します)