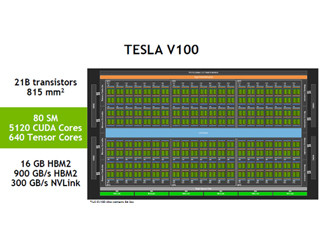
GTC 2018において「Dissecting the Volta GPU Architecture through Microbenchmarking」という論文が発表された。注目されるのは、発表を行ったZhe Jia氏ら4名の著者の所属で、次の図に見られるように、Citadel Securitiesという会社のHigh Performance Computing Groupに所属している。
Citadelは米国有数のマーケットメーカーで、株式オプション(将来のある時点で、決められた値段で株を売る権利:Put Optionや買う権利:Call Option)の取り扱いシェアを拡大しているフィンテックで最先端を行く会社である。ということで、GPUをより深く理解して、最大限、性能を引き出そうという努力を行っているようである。
-

GTC 2018でのCitadelのZhe Jia氏の発表のタイトルスライド

なお、Jia氏らは、このGTC 2018での発表の後、詳しい論文をarXiv:1804.06826v1として発表している。この連載の図は、GTCでの発表スライドとarXivの論文に掲載された図表のコピーである。
GPUの内部動作を解析した理由
性能を引き出すという点では、GPUのマイクロアーキテクチャの知識が必要である。しかし、GPUのマイクロアーキテクチャは世代ごとに変わり、複雑さも上がっていくので、マイクロアーキテクチャの変遷を追いかけていくのは容易ではない。
この論文では、
- 命令のエンコード
- メモリ階層の各レベルのキャシュなどのサイズ、性質、性能
- 命令のレーテンシ
- アトミックオペレーションの性能
- テンソルコアの性能と動作
- 精度ごとの浮動小数点演算のスループット
- ホストCPUとGPU、GPU同士の通信性能
- これらの項目に関するVoltaとPascal、Maxwell、Keplerの比較
など、知りたいことすべてを明らかにする。
-

この発表は、Volta内部の動作について、あなたが知りたがっていたことすべてを明らかにすると書いてある

なぜ、マイクロアーキテクチャの詳細を知る必要があるのか? その一例であるが、まず、簡単なマトリクスの乗算をCUDA Cで記述し、NVCCでコンパイルして性能を計測した。次に、マイクロアーキテクチャの知識を使ってNVCCの出力のコードのレジスタマッピングやレジスタ・リユーズ・キャッシュ(Register Reuse Cache)の利用率を高める修正を行った。その結果、マトリクス乗算の性能を15.4%向上することができた。
このような性能改善は、どのように命令がエンコードされているか、レジスタファイルの構造はどうなっているかなどの知識が無ければ不可能である。
ただし、このような深いレベルの最適化には手間がかかり、非常に実行頻度が高い部分でないとペイしない。また、マイクロアーキテクチャは世代ごとに変わるので、このような改善はポータブルではない。その点では、NVIDIAが提供するNVCCの改良とライブラリの改善だけを利用する方が安全である。
-

なぜ、GPUのマイクロアーキテクチャの詳細を知る必要があるのか。行列乗算の例では、NVCCでコンパイルしただけのコードに比べて、アーキテクチャの知識を使って最適化したコードでは15.4%性能を向上させることができた。詳細を知らなければ、このような性能改善はできない

8行512列の行列Aと512行8列の行列Bを掛ける場合、まず、k=0として、内側のjとiのループを回ってk=0の行列Cの各要素の値を計算する。そして、外側のkのループを回ってK=0~511の行列Cの値を順に加えていく。
なお、この図のコードは1枚のスライドに収めるために省略されているので、完全なコードが必要な場合はarXiveの論文を参照して欲しい。
-

例題として使った8行512列の行列と512行8列の行列の積の計算

(次回は5月28日に掲載します)