NVIDIAの「ディープラーニングフォーラム2015」では国内の4つの会社がディープラーニングの開発状況を発表した。3月に米国で開催されたGTC2015ではGoogle、Baidu、Facebookという大手の発表と、エマージングテクノロジの展示で多くのベンチャー企業の発表とデモがあったが、国内では大企業の発表は無く、今回発表した各社も、まだ、完成度がいまいちという感じで、米国に追いつくための努力中という印象であった。
しかし、これらのベンチャー企業と大企業が組んでのディープラーニングの開発は行われているようであるが、企業秘密ということから、その内容は発表されないという面があり、今回の発表だけで日本のディープラーニングの状況を判断するのは早計かも知れない。
システム計画研究所のディープラーニング実験
システム計画研究所(Research Institute of Systems Planning:ISP)は、1977年の創業でありベンチャーには当たらないかもしれないが、医療情報、制御・宇宙、通信・ネットワーク、画像処理の各分野を中心領域としてソフトウェアとシステムの設計開発を行っている会社である。また、自社製品としてクロマキーの画像合成を行うRobuskeyや写真の肌の色を良くする珠肌などというソフトを持っている。

|
|
ディープラーニングを用いた手形状の認識について講演するISPの奥村氏 |
今回のディープラーニングフォーラムにおいて、同社のシニア研究員の奥村義和氏が「実践ディープラーニング」と題して、手形状の認識システムについて講演を行った。
手形状の認識は、0~5本の片手の指を立てた状態を認識するもので、実用的な価値はないが、実際にシステムを作る過程や遭遇した問題点などが発表された講演で、これからディープラーニングシステムを作ってみようという人には参考になると思われる。
同社は、会場にシステムを持ち込み、デモ展示を行っていた。

|
|
会場でデモ展示されたISPの手形状認識システム。写真には写っていないが、上にUSBカメラと照明があり、モニタの前にあるJetson TK1ボードで認識システムが作られている |
実験に当たって、先ずは、写真を撮っての入力データの収集であるが、手の大きさはどの程度とするか、角度は、照明は、背景は、などの条件を決める必要がある。そして、各写真に指の本数が何本かというラベル付けを行う。これは今回は、人海戦術で行ったという。そして、収集したデータの一部を使って学習を行い、残りで性能の検証や確認を行った。

|
|
実験では40×40ピクセルのカラー画像を、男性14名、女性6名について撮影した。0~5本の指の各形状について、約3000枚。1人につき18000枚の画像を集めた。そして、それらを学習用とテスト用に分割して使用した |
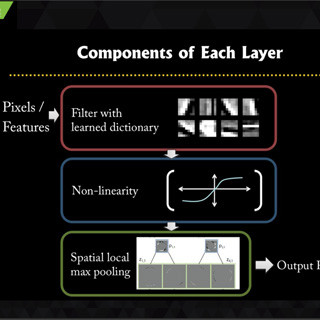
システムを作るに当たっては、どのようなネットワークにするか、層数は、Convolution(畳み込み)を行うカーネルの大きさや数、学習係数、正規化の有無などのハイパーパラメタを決める必要がある。また、画像の前処理の有無も決める必要がある。
今回の実験では、CNN(Convolutional Neural Network)を選択し、CIFAR10データセットで良い特性を示したネットワークを微変更して使用したという。元のネットワークの入力は32×32ピクセルであるが、それだと手が小さくなりすぎるので、40×40ピクセルに変更している。そして、学習係数は学習の進み方に合わせて変えるというケースが多いが、今回は0.0001固定で学習させたとのことである。

|
|
システムとしては、CNNでCIFAR10データセットで有効であったネットワークを微変更して使用した。元のネットワークは32×32であるが、40×40ピクセルに拡張した |
第1サイクルでは学習フェーズまでは順調であったが、検証フェーズで、照明条件により認識率が悪化する、人が変わると認識率が低下するという問題が見つかったという。このため、第2サイクルでは、照明条件の違いの影響を取り除く前処理を追加した。また、被験者の人数の追加と、後述のデータ拡張を行って入力画像数を増やしたとのことである。
そして、このCNNシステムと、ガウスカーネルを用いたSVM(Support Vector Machine、画像認識で標準的に使われる方式)システムとの性能比較を行っている。
次の図の棒グラフの縦軸は正答率である。3つのグループは、左から形状あたり800枚、1200枚、2100枚の画像で学習した場合。各グループの棒グラフは、左から、SVM、SVM+HoG(Histogram of Gradient、画像認識の手法)、Deep Learningで学習ループが2000回のケースと4000回のケースである。
この結果を見ると、SVM、あるいはSVM+HoGという従来の機械学習に比べて、Deep Learningの方が正答率が高いことが分かる。また、学習に用いる画像の数は正答率に大きな影響があり、高い正答率を得るためには、多くの入力が必要であることが分かる。
Deep Learningの場合、誤差をフィードバックして各入力の重みをチューニングして行くが、そのフィードバックの回数が2000回の結果と4000回の結果を比べると、若干ではあるが、4000回の方が正答率が高くなっている。

|
|
縦軸は正答率で、3つのグループは、左から形状あたり800枚、1200枚、2100枚の画像で学習した場合。各グループの棒グラフは、左から、SVM、SVM+HoG、Deep Learningで学習ループが2000回の場合ケースと4000回のケース |
さらにデータ数を増やして性能を向上させる実験を行った。新たに多数の画像を撮影するのは大変であるので、すでにある画像に、回転、微細移動、輝度変動などを加えたり、画像を引き延ばすなどの歪を加えたりしてデータを拡張した。なお、このようなデータ拡張は一般的な手段である。
次の図はデータ拡張の効果を示すもので、左端の棒グラフはデータ拡張なし、右の2本は10倍のデータ拡張を行った場合の結果で、機械的に作った入力画像でも性能改善効果があることが分かる。

|
|
データ拡張で入力画像数を10倍にした場合の結果。左端はベースラインで、右の2本がデータ拡張ありの結果である |
そして、左右反転画像を作って学習させ、右手と左手で入力した場合の結果は次の図のようになった。反転画像で学習することにより、左手で入力しても正答率の低下はわずかに抑えられている。

|
|
左右反転画像を加えて学習させ、両手で入力した場合の正答率の比較。両手対応版の性能の低下は僅かで、ほぼ同等の正答率が得られた |
そして、この認識システムの実行速度であるが、学習した結果を使うシステムをNVIDIAのJetson TK1ボードで走らせた場合、SVMでは65ms程度の認識時間であり、30fpsの半分程度の速度しか得られなかったが、cuDNN v1を使ったCaffeシステムでは24ms程度となり30fps間に合う。また、cuDNN v2を使ったISPのシステムでは8ms程度まで実行速度を向上させることができたという。

|
|
学習した重みを使う認識システムをJetson TK1で走らせたときの実行速度。SVMは65msであるのに対してCaffeでcuDNN v1では24ms、cuDNN v2を使ったISPのシステムでは8ms程度の実行速度が得られた |
結果として、ディープラーニングは性能、実行速度の点で従来のSVMよりも優れている。そして、Jetson TK1とcuDNN v2の組み合わせで、指の本数の認識ではリアルタイム処理ができることを示したと総括した。