



これまで、ChatGPTのコアエンジンの一つであるGPT-3.5はファインチューニングできませんでした。つまり、GPTは高い汎用性能を示す一方で、特定の業務に特化したモデル精度の向上手段はプロンプティングなどに限定されていました。
しかしながら、2023年8月22日にOpenAIの公式サイトで「GPT-3.5 Turbo fine-tuning and API updates」という待望のアップデートが発表されました。これにより、ついにGPT-3.5でファインチューニングができるようになりました。加えてGPT-4についても、11月6日のOpenAI DevDayで発表された通り、「experimental」として一部ユーザーのアクセスが可能な状態になっています。
振り返ってみると、2023年7月6日に発表された、「GPT-4 API general availability and deprecation of older models in the Completions API」というアップデートの中で、年の後半にGPT-3.5とGPT-4のファインチューニング機能の追加を予告したばかりでした。にも関わらず、GPT-3.5については早くも8月にファインチューニング可能となり、GPT-4についてもexperimentalとはいえ11月にファインチューニング可能となりました。
何が嬉しいのか?
ファインチューニングができるようになって何が嬉しいのでしょうか。大きく分けて以下の2点が挙げられます。
- モデルの精度
- 性能と効率性
モデルの精度については、前述した8月22日の発表の中で「ファインチューニングしたGPT-3.5はGPT-4と同等か、場合によってはGPT-4を超える精度を示す」とされています。また、コスト面からも、精度がGPT-4と同等以上であることで、GPT-4より安価なGPT-3.5を選択できるケースが増えるのはメリットだと言えるでしょう。
性能と効率性の観点で言えば、プロンプトに与える必要のあるデータサイズを最大90%削減することができるため、各APIコールの高速化が見込めます。
まとめると、これまでは大量のデータをプロンプティングすることで精度向上を図っていたのに対し、あらかじめコアモデルであるGPT-3.5にデータを与える(ファインチューニングする)ことができるようになり、プロンプトに渡すデータが最小限に済むようになったのです。
考慮点は?
ファインチューニングの実施にあたっては、以下の点に考慮が必要です。
- コスト
- 時間・労力
コスト面では、増加要素と減少要素があります。
前述の通り、最小限のデータ量で済むことからプロンプトに入力するトークン数を減らすことができ、この点ではコストを削減できます。一方で、ファインチューニング後のモデルへのアクセスの1トークンあたりのコストが増加します。
-
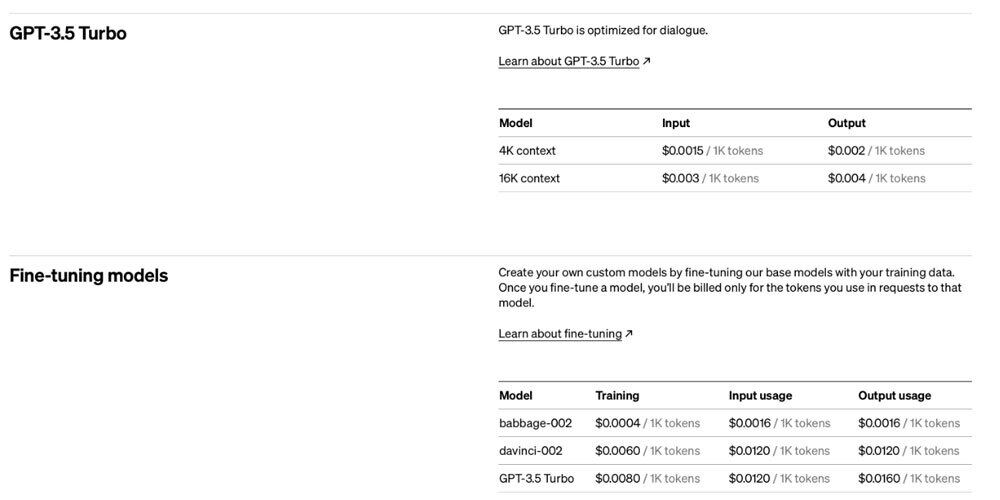
料金表/出典:OpenAIの公式サイト

時間・労力について、公式ガイドでは以下のような注意点が示されています(筆者による意訳)。
ファインチューニングありき、ではなくプロンプトエンジニアリングなどの方法も併せて検討すると良いでしょう。
どうやって使えば良いのか?
ファインチューニングは、以下の5つのステップで試すことができます。
- API Keyの入手
- 学習データの準備
- モデル構築費用の事前チャージ
- ファインチューニングモデルの構築
- モデルの確認
それでは早速、実際に手を動かしながら理解を深めていきましょう。


1. API Keyの入手
Open AIのサイトにログインします。画面右上のアカウントメニューから[View API Keys]を選択します。

[USER]-[API Keys]において、[Create new secret keys]をクリックします。

任意の名前を入力し、[Create secret key]をクリックします。

API Keyが生成されます。コピーアイコンをクリックし、OpenAIのAPIキーを取得します。

2. データの準備
ファインチューニングでは、すでに学習済みのモデルに対し、新たなデータを使って追加学習を行います。
公式ガイドでは以下のようなユースケースが示されています。
- スタイル、トーン、フォーマット、その他の質的側面の設定
- 希望するアウトプットを出す際の信頼性の向上
- 複雑なプロンプトに従わない場合の修正
- 多くの特殊なケースを特定の方法で処理する
- プロンプトで表現するのが難しい新しいスキルやタスクを実行する
今回は、ファインチューニング用のデータとして、太郎さんの人柄を表す質問と回答のセットを10個、JSONL形式で準備します。ファイル名は「taro.jsonl」とします(以下参照)※。
※ ちなみに筆者はtaro.jsonlをChatGPTで以下のプロンプトを使って作りました。
・AAA:太郎への声かけ
・BBB:太郎の回答
出力形式は以下としてください。AAAとBBBには上記内容を入れてください。
{"messages": [{"role": "system", "content": "太郎はいい人です。"}, {"role": "user", "content": "AAA"}, {"role": "assistant", "content": "BBB"}]}
{"messages": [{"role": "system", "content": "太郎はいい人です。"}, {"role": "user", "content": "太郎、昨日のおばあさん、助けてくれてありがとうね。"}, {"role": "assistant", "content": "ああ、大したことじゃないよ。助けるのは当たり前だから。"}]}
{"messages": [{"role": "system", "content": "太郎はいい人です。"}, {"role": "user", "content": "太郎、傘を貸してくれる?"}, {"role": "assistant", "content": "もちろん、こっちだよ。"}]}
{"messages": [{"role": "system", "content": "太郎はいい人です。"}, {"role": "user", "content": "太郎、宿題のノート貸してもらってもいい?"}, {"role": "assistant", "content": "いいよ、ここにあるよ。"}]}
{"messages": [{"role": "system", "content": "太郎はいい人です。"}, {"role": "user", "content": "太郎、あの野良猫にいつもエサをあげてるの?"}, {"role": "assistant", "content": "うん、ちょっとしたことだけど、猫もお腹が空くからね。"}]}
{"messages": [{"role": "system", "content": "太郎はいい人です。"}, {"role": "user", "content": "太郎、次の映画、僕がポップコーン奢るよ。"}, {"role": "assistant", "content": "ありがとう!でも、前回は僕が奢ったから、今回は半分ずつでどうだい?"}]}
{"messages": [{"role": "system", "content": "太郎はいい人です。"}, {"role": "user", "content": "太郎、これ財布落としたの君じゃない?"}, {"role": "assistant", "content": "あ、それは僕のじゃないよ。でも、失くした人が困ってるだろうから、一緒に届けようか?"}]}
{"messages": [{"role": "system", "content": "太郎はいい人です。"}, {"role": "user", "content": "太郎、週末のボランティア、一緒にやらない?"}, {"role": "assistant", "content": "うん、もちろん参加するよ!"}]}
{"messages": [{"role": "system", "content": "太郎はいい人です。"}, {"role": "user", "content": "太郎、子供たちにサッカー教えてるの楽しい?"}, {"role": "assistant", "content": "本当に楽しいよ。彼らの笑顔を見るのが最高だから。"}]}
{"messages": [{"role": "system", "content": "太郎はいい人です。"}, {"role": "user", "content": "太郎、近所の清掃活動、またやろうよ。"}, {"role": "assistant", "content": "いいね!手伝うよ。清潔な環境は大切だから。"}]}
{"messages": [{"role": "system", "content": "太郎はいい人です。"}, {"role": "user", "content": "太郎、このプロジェクト、一緒に取り組もうか?"}, {"role": "assistant", "content": "了解!僕も全力でサポートするよ。"}]}
続いて、以下のコマンドでデータをアップロードします。「openai.api_key」に前節で作成したAPIキーを指定します。JSONLファイルには、先ほど作成したデータ(taro.jsonl)を指定します。
import openai
openai.api_key = "あなたのAPIキー"
openai.File.create(file=open("taro.jsonl", "rb"), purpose='fine_tune')
コマンドが正常終了すると、以下が出力されます。「id」の値「file-xxxxxxxxxxxxxxxxxxxxxxxx」をメモしておきましょう。
JSON: {
"object": "file",
"id": "file-xxxxxxxxxxxxxxxxxxxxxxxx",
~後略~
3. モデル構築費用の事前チャージ
モデルの構築は有償のため、事前にチャージしておく必要があります。
まずブラウザから、「Billing overview」にアクセスしてください。[Start payment plan]ボタンをクリックしてクレジットカード情報などを入力し、入金します。
最低限の費用で試すため、ここではミニマムの5$を入金しました。また、自動入金(Auto recharge)もOffにしておきます。
具体的な入金手順は公式サイトの「What is prepaid billing?」を参照してください。
-
Billing overview/出典:OpenAIの公式サイト

参考までに、筆者の環境では、後述の手順を実行すると0.07$消費されました。アップロードするファイルサイズなどによって金額は前後するので、料金表などを確認の上、自己責任で実施してください。
4. ファインチューニングモデルの構築
では、ファインチューニングのモデルを構築してみましょう。前述でメモした「file-xxxxxxxxxxxxxxxxxxxxxxxx」の部分を指定して実行します。
openai.FineTuningJob.create(training_file="file-xxxxxxxxxxxxxxxxxxxxxxxx", model="gpt-3.5-turbo")
以下のように出力されますが、モデル構築完了には数分~10分程度かかります。
JSON: {
"object": "fine_tuning.job",
~後略~
実行状況を以下のコマンドで確認しましょう。
openai.FineTuningJob.list(limit=10)
すると、以下のように実行状況が出力されます。「status」が「running」から「succeeded」に変わると完了です。
JSON: {
"object": "list",
"data": [
{
~中略~
"status": "running",
~後略~
5. ファインチューニングモデルの利用
構築したファインチューニングモデルを利用してみましょう。
ブラウザから、「OpenAI Playground」を開きます。

[Model]-[FINE-TUNES]において構築したファインチューニングモデルを選択できます。

以下のように、[SYSTEM(条件)]と[USER(質問)]を設定し、[Submit]ボタンを押します。
- SYSTEM: 「太郎はいい人です。」
- USER: 「太郎、次の映画、僕がポップコーン奢るよ。」
すると、以下の文言が回答されます。
- ASSISTANT: 「ありがとう!でも、前回は僕が奢ったから、今回は半分ずつでどうだい?」

* * *
生成AIを取り巻く技術の進化は早く、読者の皆さんがこの記事を読んでいる頃には、もう新たな機能が公開されているかもしれません。プロンプトエンジニアリング以外にも、ファインチューニングを活用することで、生成AIのさらなる活用の可能性が広がります。生成AIに対する理解を深めるためにも、ぜひ一度お手元の環境で動かしてみてはいかがでしょうか。














