まるで人間と会話しているかのような質の高い回答を返す対話型AI「ChatGPT」。その開発元であるOpenAIは同時期に、テキストから画像を生成することができる「DALL·E」も公開した。本稿執筆時点で提供されている最新版は「DALL·E 3」だ。
本連載では、このDALL·E 3を使った画像生成について、サンプルを交えながら解説していく。
自然言語による質の高いやり取りを実現したChatGPT
2022年11月、OpenAIはChatGPTのプロトタイプを一般公開した。ご存じの通り、インターネット上の大量のテキストデータを用いて学習した内容をベースに、対話形式で質問に応えてくれるAIチャットボットだ。まるで人間の言葉を理解しているかのような自然なやり取りが可能なことで、注目を集めた。
それ以前から「デジタルアシスタント」というジャンルで、似たようなサービスは存在している。Amazonの「Alexa」やAppleの「Siri」、Microsoftの「Cortana」、Googleの「Googleアシスタント」などだ。確かにいずれも、テキストや音声による簡単な命令を理解し、機能してくれる。
しかし、ChatGPTの精度はこれらとはレベルが違った。より複雑な自然言語を理解し、長文かつ自然な回答を返してくれる。その挙動を見て、映画「スターウォーズ」に出てくるプロトコルドロイド「C-3PO」や映画「アイアンマン」に出てくる自律型人工知能システム「J.A.R.V.I.S」を連想した方も多かったんじゃないかと思う。ChatGPTはC-3POやJ.A.R.V.I.Sほど自律的には動かないが、会話の反応はこれを想起させるものだった。
テキストから画像を生成するDALL·E
ChatGPTを公開したOpenAIは、同時期にテキストから画像を生成するモデルについても発表した。こちらも多くのユーザーに衝撃を与えた。次の画像をご覧いただきたい。
-

DALL·E 3 / ChatGPT Plusで生成した画像サンプル(その1)

-

DALL·E 3 / ChatGPT Plusで生成した画像サンプル(その2)

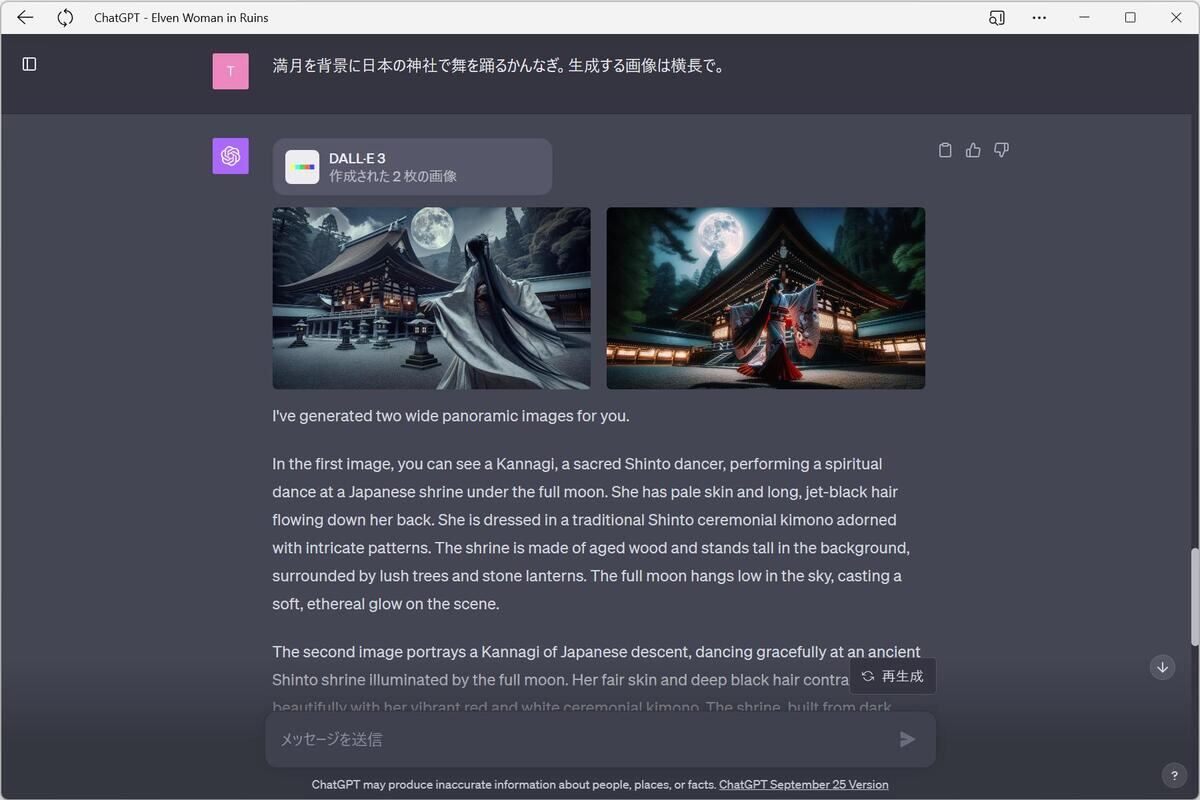
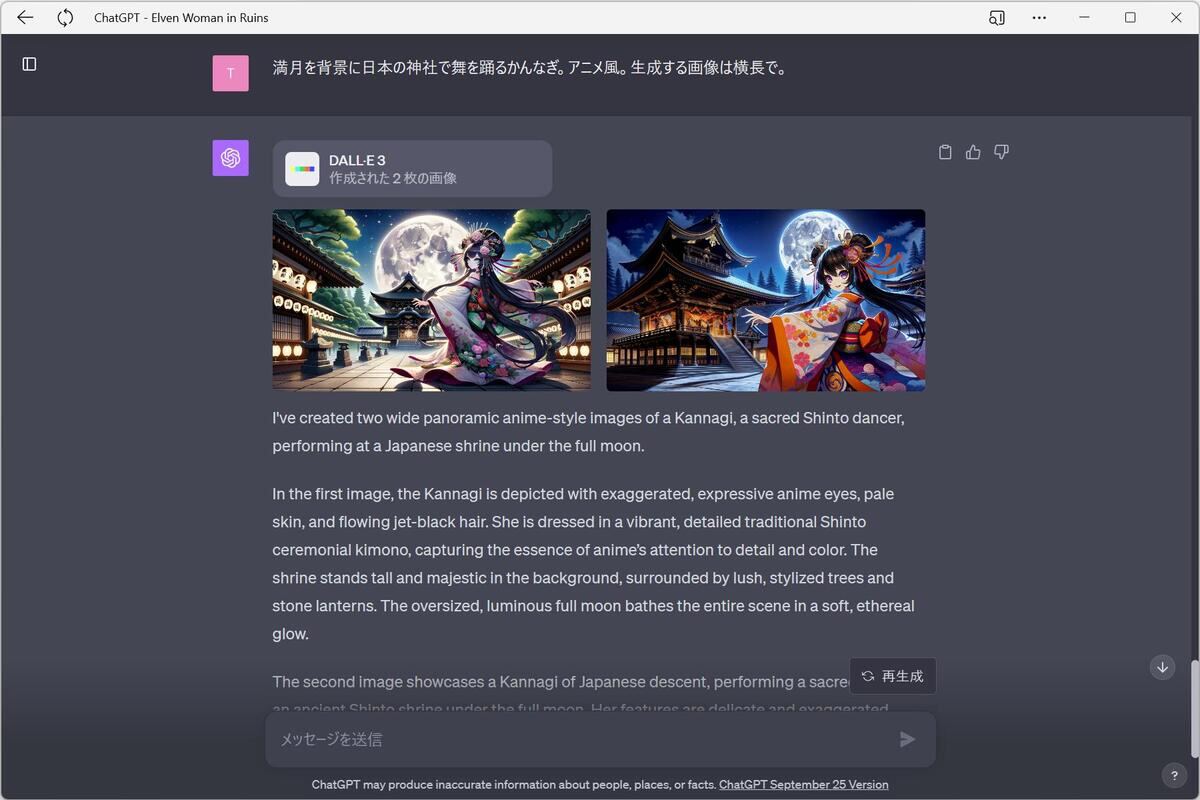
上記の画像は、OpenAIが提供するサービス「ChatGPT Plus」経由で次のように生成を指示したものだ。
-
DALL·E 3 / ChatGPT Plus 画像サンプル(その1)の生成方法

-
DALL·E 3 / ChatGPT Plus 画像サンプル(その2)の生成方法

最初の画像は「満月を背景に日本の神社で舞を踊るかんなぎ。生成する画像は横長で。」という指示で生成されている。2つ目の画像は「満月を背景に日本の神社で舞を踊るかんなぎ。アニメ風。生成する画像は横長で。」という指示によって生成されたものだ。


テキストによる指示で画像をカスタマイズ
これらの画像生成において、ChatGPT Plus経由で画像生成モデルとして使用されているのがDALL·E 3だ。DALL·E 3は、それまでのモデルと比較して、言葉のニュアンスをより正確にくみ取り、ユーザーの意図に近い画像を生成すると言われている。さらに使用例を見てみよう。
「百鬼夜行をテーマにした画像を生成してください。」という指示を行った結果が次の画像だ。
-
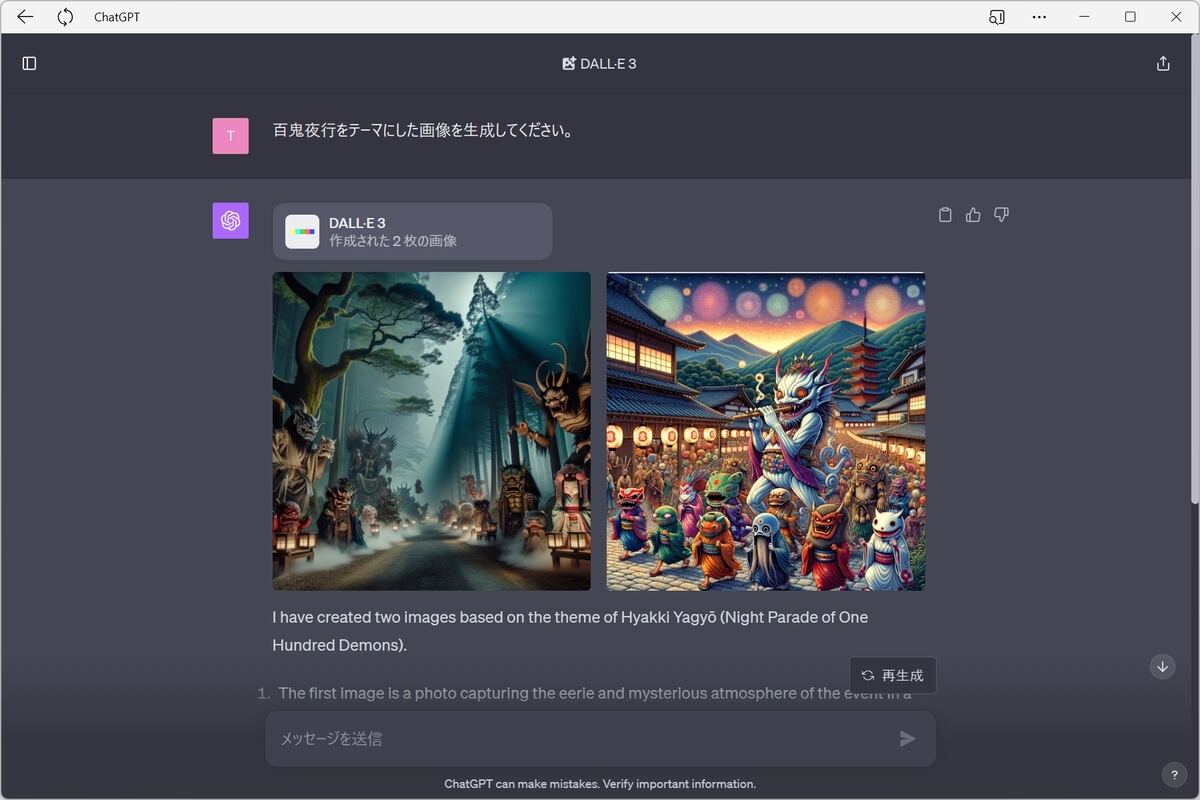
「百鬼夜行をテーマにした画像を生成してください。」と指示

どちらかと言えば左の画像が、筆者の想定していたイメージに近い。さらにイメージに近づけるために、「左の画像をベースに、より高品質で重々しい雰囲気に仕上げてください。」と指示を出す。
-
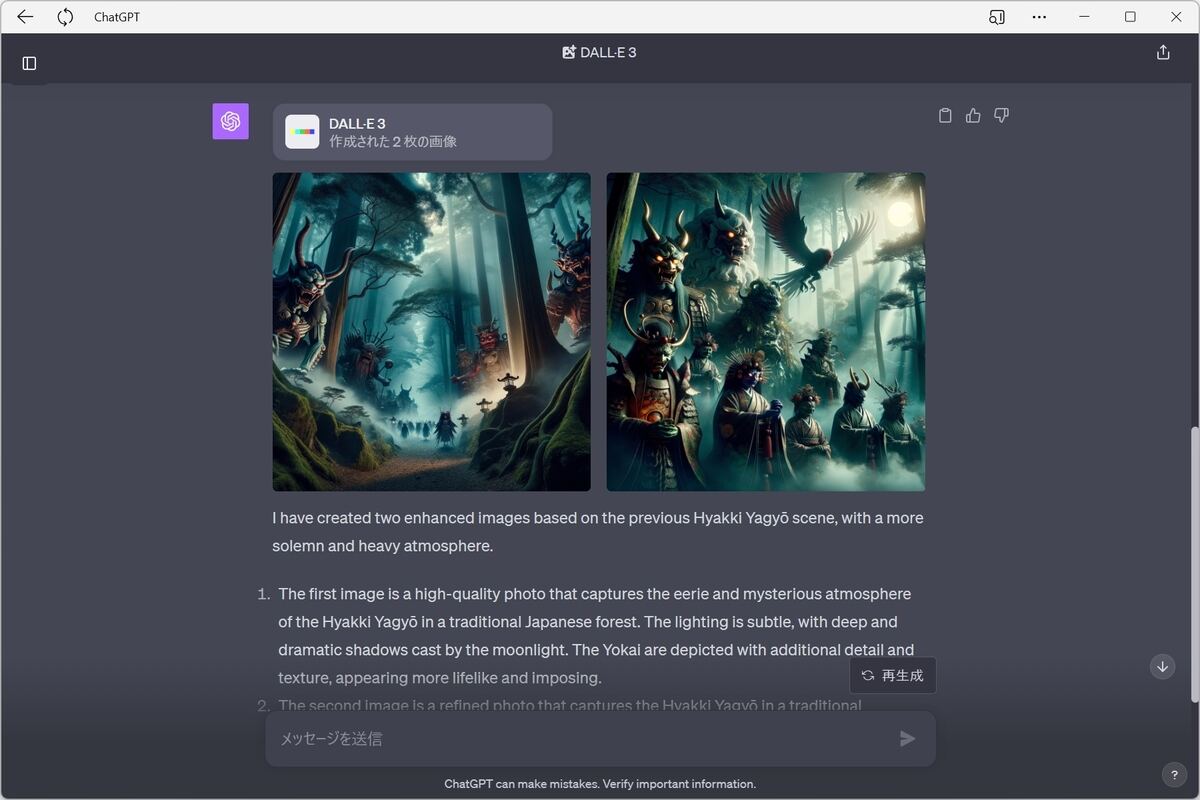
「左の画像をベースに、より高品質で重々しい雰囲気に仕上げてください。」と指示

重々しいと言ってもフォトリアルではなく、アニメのような描写が良いので、さらに「アニメっぽく書き換えてください。」と指示する。
-
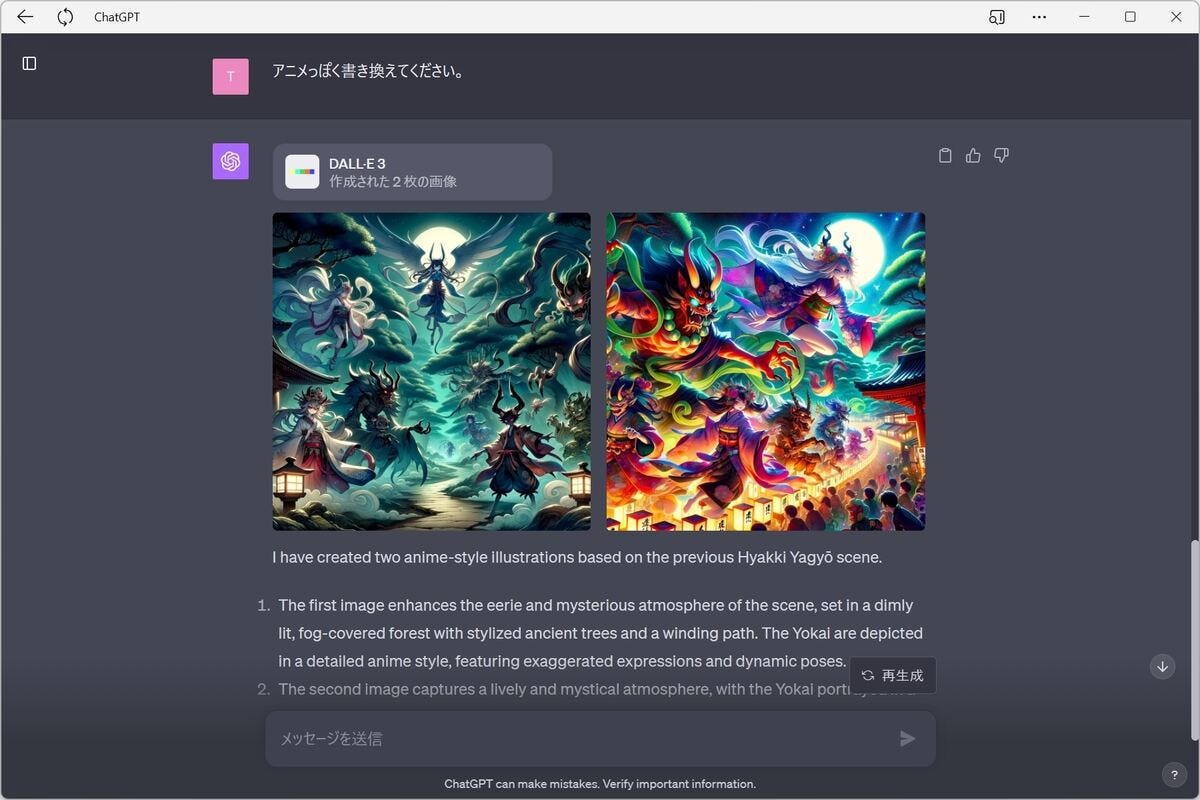
「アニメっぽく書き換えてください。」と指示

左の画像がかなり筆者のイメージに近い。こちらをベースに仕上げていくように「左の画像を横長で高品質なものに仕上げてください。」と指示を出す。
-
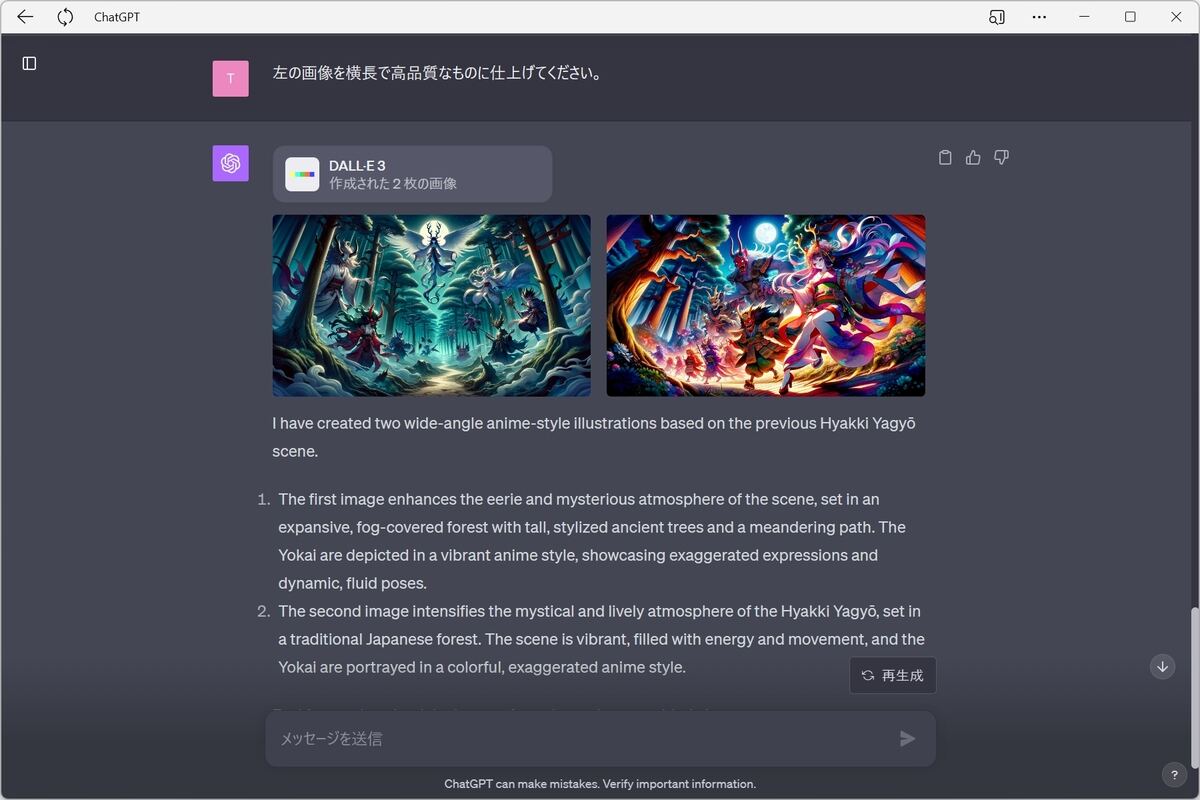
「左の画像を横長で高品質なものに仕上げてください。」と指示

この指示で生成された画像の一つが、次の画像だ。
-

今回生成された画像サンプル

ChatGPT PlusでDALL·E 3を使うと、こんな感じで画像を生成・変更していくことができる。
ここで、こうした画像生成を可能としている「DALL·E」というモデルについて、簡単に整理しておこう。
DALL·E :2021年に登場した最初のモデル
現在OpenAIが提供している「自然言語からの画像生成技術」が世間に知られるようになったきっかけは、2021年1月、OpenAIがDALL·Eの存在を明らかにしたことだろう。DALL·EはChatGPTで使われている「GPT-3 (120億パラメータバージョン)」でトレーニングされた画像生成モデルだ。テキストと画像をペアにしたデータセットで学習が行われており、自然言語による指示から“それらしい画像”を生成することができる。
-
DALL·E: Creating images from text

物体や動物を擬人化した画像を生成したり、無関係な概念を組み合わせてもっともらしい画像を生成したりといったことも可能だ。
DALL·Eが生成する画像はときにユーモアがあり、ときに不正確で誤っている。いずれにせよ、DALL·Eを使ってみたユーザーの多くは、自然言語による指示だけでそれらしい画像が自動生成されることに驚いた。AIが、まるで人間の言葉を理解しているかのように振る舞うことに衝撃を受けたのである。
DALL·E 2:2022年に登場した次のバージョン
翌2022年、OpenAIはDALL·Eの後継バージョンとなる「DALL·E 2」の提供を開始した。
-
DALL·E 2 - OpenAI

DALL·E 2は、DALL·Eの4倍の解像度によって、よりリアルで正確な画像を生成できる点が特徴だ。
DALL·E 3:2023年に登場した最新バージョン
OpenAIは2023年9月、DALL·Eシリーズの最新版となるDALL·E 3を発表した。この最新版は、それまでのバージョンよりもアイデアを正確に画像に反映できるようになったと評価されている。
-
DALL·E 3 - OpenAI

現状、DALL·E 3は有償のChatGPT Plusと「ChatGPT Enterprise」で利用できるようになっている。ChatGPTを使った対話により、生成した画像を基に、さらに指示を追加していくことで画像を書き換え、意図する画像を生成しやすい点が特徴だ。今後は、APIおよびLabs経由での提供も予定されている。
この技術をどう活用していくか?
DALL·E 3を使えば、従来、画像生成スキルを持たないユーザーでは作ることができなかったような画像を、テキストによる指示で生成できるようになる。しかし、頭の中に思い描いた画像を生成させるには、適切な言葉で指示する技術が必要だ。
ChatGPT同様、DALL·E 3のビジネス活用に関心を持つ企業は少なくない。反面、著作権に関する懸念などもあり、二の足を踏んでいる企業が多いのも事実だ。登場してから日が浅く、誰もが模索する段階にある今こそ、ある程度の失敗を前提にしてでも活用に向けて動き始める良いタイミングではないだろうか。本連載がその一助になれば幸いだ。