前回は、「ChatGPTの今後 - 前編」として、ChatGPTの進化を中心に紹介しました。後編となる今回は、ChatGPTを取り巻く環境に着目し、ChatGPT以外のさまざまな生成AIサービスについて紹介します。その上で、ChatGPTが今後どのような進化を遂げていく可能性があるのかについても考察します。
→連載「ChatGPT入門 - 初めてのAIチャット活用」の過去回はこちらを参照。
ChatGPTを取り巻く環境
ChatGPTの周辺では、類似ツールや企業独自の生成AIサービスなどが次々に発表され、推進体制も強化されつつあります。順に見て行きましょう。
GAFAMなどからChatGPT類似ツールが登場
GoogleやMetaといったテック系企業から、ChatGPTの競合とも言える類似ツールが出てきています。
- Google Bard:Google検索機能との連携したチャットボット
- Amazon Bedrock:さまざまな生成AIモデル(ファウンデーションモデル)を活用可能。AWSのさまざまなクラウドサービスと組み合わせられる
- Meta LLaMa:Metaが開発した生成AIモデル(LLaMa)をオープンソースとして公開
- マイクロソフト
- 新しいBing:マイクロソフトのEdgeブラウザ標準の検索エンジンBingと連携したチャットボット
- Azure OpenAI Service:Azure上で利用でき、ChatGPTのコアエンジンであるGPT4を活用
- 百度 ERNIE Bot(文心一言):中国語版ChatGPT
企業独自の生成AIサービスが続々と発表
多くの企業が、競うように生成AIサービスを発表し始めています。ChatGPTで使われているOpen AIの言語モデル(GPT-4など)を活用しているケースや、独自の言語モデルを開発しているケースまでさまざまなものが存在します。
- KDDI、独自の生成AI「KDDI AI-Chat」を社員1万人が利用開始
- 日立製作所が独自生成AI開発へ、アイデア立案や会議などで活用
- AI inside、140億パラメータを持つ日本語LLMサービスのα版を提供開始
- サイバーエージェント、独自の日本語LLM(大規模言語モデル)を開発 ―自然な日本語の文章生成を実現―
- 通信大手、AIの開発・利用へ独自戦略
2023年6月9日に経団連が「わが国独自のAI開発能力の構築・強化」を提言しており、今後国内においても独自の生成AI技術が進展していくことが期待されています。
生成AIラボの創設など推進体制の強化
各企業が生成AIに関するラボを新設しています。GoogleがDeepMindと統合し生成AIに関する推進体制を強化するなど、今後もChatGPTの利用が各企業で加速してくことでしょう。
- Alphabet、AI開発・研究を再編、「DeepMind」と「Google Brain」を統合
- ラックが生成AIを活用するためのCoEを設立、知見を集約し顧客にも提供
- 三井住友海上、生成AIを専門的に研究・検討を進める「AIインフィニティラボ」新設
自分で作りたい場合はどうすれば良いか?
前述の通り、生成AIを使ったさまざまなサービスが登場しています。「自社でも似たようなサービスを展開したい」と思い立っても不思議はありません。以下では、そうした場合について考えてみます。
「生成AIとは何なのか」を理解しよう
日頃からChatGPTを使っていたとしても、「そもそも生成AIとは何なのか」「(活用するために)何を知っておくべきか、何から始めたら良いのか」といったことがわからない方もいらっしゃるのではないでしょうか。
以下の3点を知ることで、生成AIを活用する際のイメージの幅を広げてみましょう。
- 生成AIにはどんな大規模言語モデル(LLM)があるのか?
- LLMにおいて押さえるべき特徴は?
- PT/FT(プリトレーニングとファインチューニング)とは何か?
◆生成AIにはどんな大規模言語モデル(LLM)があるのか?
A Survey of Large Language Modelsでは、以下のようなLLMが挙げられています。2020年7月にGPT-3が登場してからわずか3年足らずでGPT-4が登場していること、その間多くのモデルが開発されていることが分かります。
-
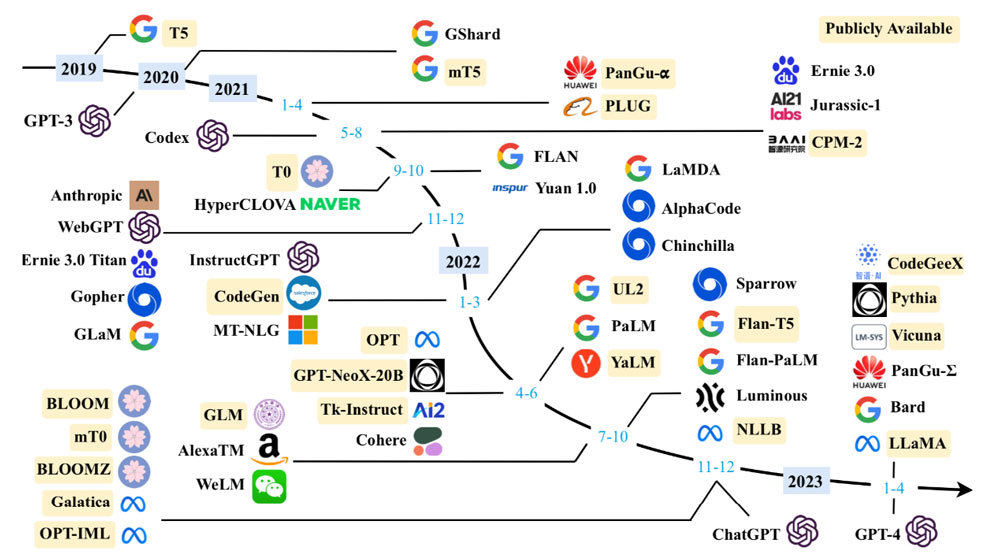
近年のLLM(A Survey of Large Language Modelsより引用)



◆LLMにおいて押さえるべき特徴は?
数百・数千億パラメータを有するLLMの学習には、数百から数千にも及ぶGPUやTPUが必要とされています。これほどまで巨大な環境を保持することは困難なため、ローカル環境で動作させるのではなく、API経由で利用するのが現実的です。実際、GPT-3、GPT-3.5、GPT-4などのモデルはパブリックなAPIが用意されています。
LLMの学習データの情報源のうち、代表的なものは以下です。
- Books:BookCorpus、Project Gutenbergといった書籍データベース
- CommonCrawl:オープンソースのウェブクローリングデータベース
- Reddit links:テキストやリンクを投稿できるソーシャルメディア。イイネ相当の機能もある
- Wikipedia:ウィキペディア
- Code:GitHubに代表されるリポジトリや、StackOverflowに代表される技術問い合わせサイト
◆PT/FT(プリトレーニングとファインチューニング)とは何か?
PT(プリトレーニング)では、大量のデータを用いて汎用的なAIモデルを構築します。例えば、単語の意味・文法・文脈などです。一方で、FT(ファインチューニング)では、PTをベースに特定のタスク(質問応答、文章生成、感情分析など)を追加トレーニング(チューニング)します。
Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processingによると以下の技術の進化があります。
- a 教師あり学習をニューラルネットワークを用いずに構築
- b 教師あり学習をニューラルネットワークを用いて構築
- c プリトレーニングとファインチューニングを実施
- d cに加えてプロンプトエンジニアリングを実施
-
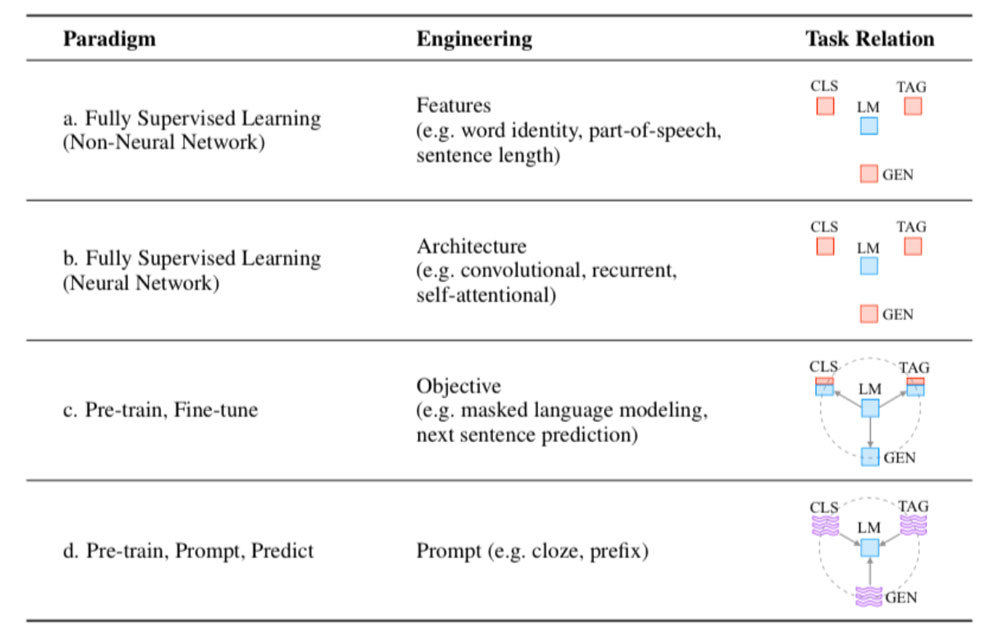
NLPのパラダイム(Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processingより引用)

自分でAIモデルを作る場合の3つの方法
GPT-4をはじめとした、いわゆるファウンデーションモデルを一から構築することは並大抵の技術力と資金力では実現できません。
したがって、多くのケースにおいては、一から構築するのではなく、既存のモデルやサービスを活用することになります。
上記を踏まえ、以下の3つのレベル感で捉えると良いでしょう。
- レベル1:ベースのモデルをAPIから利用(上図dでプロンプトエンジニアリングを中心に実施)
- レベル2:OSSを使って比較的軽量な言語モデルを作ってみる(上図cのファインチューニング部分のみ実施)
- レベル3:独自の大規模言語モデルを作る(上図cのプリトレーニング部分から作る)
◆レベル1:ベースのモデルをAPIから利用
ChatGPTは大きく以下の2つのパーツに分かれます。
- インタフェース:チャットボットの画面
- AIモデル:裏で動くAIモデル。いわゆるGPT-3.5やGPT-4の部分
ChatGPTをそのまま利用する方法の他に、API経由でAIモデルを利用する方法があります。裏で動くAIモデルは活用しつつLINEやSlackと連携したい、といった独自のインタフェースを構築するケースはこの方法を選ぶと良いでしょう。また、Open AIのGPT-4とその他のOSSのモデルなど、複数のAIモデルを組み合わせて利用するケースも考えられます。
なお、この場合は、プロンプトエンジニアリングを中心に活用することになり、固有の業務に特化したモデルにチューニングすることが難しい場合があります。例えば、一部のAPI(GPT-3)はファインチューニングまで対応していますが、ChatGPTのAIモデルであるGPT-3.5やGPT-4はファインチューニングには対応していません(2023年7月8日時点)。しかしながら、OpenAIは2023年7月6日に以下の通り、ファインチューニングを年内に使えるよう計画している旨発表しました。

◆レベル2:OSSを使って比較的軽量な言語モデルを作ってみる
超高性能GPUや超大規模なメモリは個人レベルではなかなか用意できません。一方で、OSSで公開されているモデルの中には、PCで動作する比較的軽量なモデルが存在します。AIモデルが235,426個(2023年6月24日時点)登録されているHugging Faceと呼ばれるサイトにおいて、LLM-Leaderboardで代表的なLLMが紹介されています。
ファインチューニングまで踏み込んで対応しているものもありますので、固有の業務に特化したモデルにチューニングしたい方はトライしてみてはいかがでしょうか。
- Cerebras-GPT:Cerebrasが開発したGPT-3ベースのモデル
- OpenFlamingo:LAIONが開発したDeepMindのFlamingoベースの、画像と文字を扱うマルチモーダルなモデル
- GPT4all:Nomic AIが開発したGPT-Jベースのモデル
- Dolly 2.0:Databricksが開発したpythiaベースのモデル
- Vicuna:Nomic AIが開発したLLaMAベースのモデル
なお、BrainPadのPlatinum Data BlogにGPT-4登場以降に出てきたChatGPT/LLMに関する論文や技術の振り返りが紹介されています。LLMの動向や利用シーンなどについて気になる方は参照されると良いでしょう。
◆レベル3:独自の大規模言語モデル(LLM)を作る
軽量なOSSでは物足りず、超高性能GPUや超大規模なメモリを使い、企業レベルでの開発を行うケースが見られます。
これは、医療、法律、保険などの業界特化の内容や、ITにおけるソフトウエア開発の業務プロセスなど、特定の業務用途に深く入り込んだAIモデルを必要とする場合に有効な手段となる可能性があります。また、そもそも多くのモデルは英語の精度に比べて、日本語の精度が低い傾向にあります。日本語に最適化されたAIモデルの活用も必要となる場合があるでしょう。
ここまで、レベル1(APIベース)~レベル3(独自LLM)までを紹介しました。どのレベルを採用して、どんなことに挑戦するのかは、読者の皆さまがやりたいことに合わせて検討してみると良いでしょう。
ChatGPTの今後の展開
最後に、ChatGPTの今後の展開について、いくつかの観点から見ていきたいと思います。
コパイロット
まずは、昨今注目を集めている「コパイロット(副操縦士)」に着目してみましょう。
◆ソフトウエア開発におけるコパイロット
ChatGPTや生成AIはコパイロットと表現されることがあります。プログラミング中に、副操縦士であるChatGPTや生成AIと相談しながらプログラムを作るようなイメージです。
2023年3月に「GitHub Copilot X」がリリースされました。実現したい機能を指示すると、必要なプログラムを提案してくれるなど、これまでのソフトウエア開発自動化とは異なるレベルまで到達してきています。
こういった革新的な変化はプログラミングのみが対象なのでしょうか? 以下のように、設計やテスト、プロジェクト管理など、より広範にChatGPTの技術が活用されていくことでしょう。
- 設計情報を投入するとプログラムが生成される
- 要件を投入すると必要な設計書が生成される
- 設計やプログラムや基盤の不備を自動摘出
- プロジェクト管理上の進捗・品質などのリスクを検出
◆OA作業におけるコパイロット
Copilot系の製品の登場により、Windowsの基本的な作業、ExcelやPowerPointなど、あらゆるPC作業に生成AIを組み込むことが考えられます。
- Windows Copilot
- Microsoft 365 Copilot
例えば、Excelでの作業中に、必要な関数や操作手順の提案をもらえたり、ChatGPTのような使用感で質問できたりします。つまり、横にコパイロットとして、家庭教師やトレーナーがついているような感覚で作業ができるのです。
プロンプティング
プロンプティングの世界はまだまだ発展途上です。代表的な課題を紹介します。
◆長い入力に関する課題
OpenAIのCookbookの中の Techniques to improve reliabilityには、複雑な内容はある程度複数の内容に分割するように記載されています。
◆入力単語数の制限
ChatGPTにはプロンプトの入力単語数には制限があり、例えばリポジトリ全体を読み込むといった用途には不向きです。2023年6月6日に発表されたLTM-1は500万トークンを扱うことができ、ChatGPT(GPT-4)の3.2万トークンを大きく上回っています。
◆思考プロセスの重要性 - ICL(In-Context Learning)とCoT(Chain of Thought)
Chain-of-Thought Prompting Elicits Reasoning in Large Language Modelsによると、CoT(思考プロセス)を学習させることで精度が向上することが示されています。
以下の例は、通常のICLにより例示を与えるプロンプト(下図左)に対して、思考プロセス(下図右)についても与えています。この例では計算結果を与えるだけでなく、なぜこの計算になったかを与えています。
-
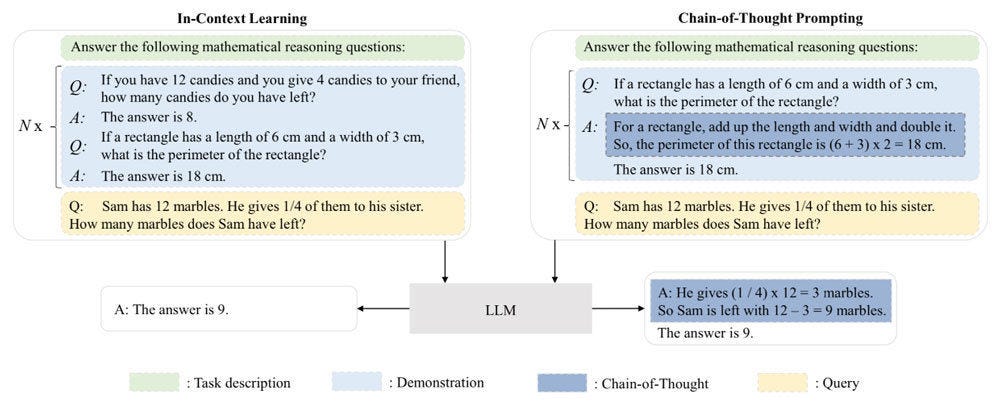
ICL(In-Context Learning)とCoT(Chain of Thought)(A Survey of Large Language Modelsより抜粋)

AIモデル
AIモデルの代表的な課題は以下の通りです。
- AIモデルの原理・理論には不明な内容が多い
- 例えば、LLMの特徴として、Emergent Abilities of Large Language Modelsで示される通り、言語モデルのパラメータ数が臨界サイズ(例えば10B)まで増加すると、いくつかの創発的な能力が予期せぬ形で発生する
- AIモデルの進化はまだまだ途上
- マルチヘッドアテンション、スパースアテンションなど、AIモデルの精度を上げる仕組みが続々と登場している
- 一方で、「壊滅的な忘却」はニューラルネットワークの長年の課題。例えば、ある特定のタスクに従ってLLMを微調整すると、LLMの一般的な能力に影響を与える
- 安全なAI
- 攻撃的な応答や、倫理に反する応答などが無いようにすることが求められる。ChatGPTはかなり高いレベルで実現されている。一方で、ChatGPTがより広範かつ深く利用されていくにつれて、より高い安全性に関する要望が高まることが想定される
- Chat Model:HumanMessageなどのモジュールによりOpenAIのAPIをラップする
- Prompt Templates:あらかじめ用意したプロンプトテンプレートにユーザーの入力を当てはめる
LLMを使ったアプリを構築するためのフレームワーク
LLMを活用したシステム構築では、LLM単独でAPIを叩くだけでなく、外部データと繋げたり、エージェントとして相互作用させたりといったことが必要となってきます。そんな中、LangChainやSemantic Kernelやguidanceなどの、LLMを使ったアプリを構築するためのフレームワークがトレンドになってきています。
例えば、LangChainには以下のような機能が用意されており、LLMを使ったアプリを効率的に構築できるようになります。
* * *
今回はChatGPTを取り巻く環境に着目し、ChatGPT以外のさまざまな生成AIサービスについて紹介した上で、「LLMとはそもそもどういうものなのか」「実際に作りたい場合はどういうアプローチが考えられるのか」について解説しました。
「ChatGPTは、これからどのように進化していくのか」――これに関しても、コパイロット・プロンプティング・AIモデル・LLM活用フレームワークの観点から可能性をお伝えできたかと思います。
今後、ChatGPTはさらに機能が追加され、活用シーンも広がりを見せていくことでしょう。読者の皆さまも、ぜひ普段の作業にChatGPTを取り入れてみてはいかがでしょうか。