



セントルイスで開催されたHPCに関する国際会議「SC21」においてCerebrasはウェハスケールのAIアクセラレータとそのSDKの提供を発表した。
左の写真のように300mmウェハ全面をひとつのチップとして、その上にアクセラレータを作っている。チップ面積は46,225mm2で、TSMCの7nmプロセスを使って、AI用に最適化した85万個のコアを集積している。そして、このチップに2.6 Trillion(2.6兆個)トランジスタを搭載し、40GBのオンチップメモリを集積している。メモリバンド幅は20PB/sと非常に大きい。ファブリックのバンド幅は220Pbit/sとこれも非常に大きい。
右側の写真は発表を行ったVice Presidentで製品の責任者(Head of Product)のAndy Hock氏である。
-

Cerebrasのウェハスケールエンジン。46,225mm2のウェハ全面に85万個のAIコアと40GBのメモリを集積している。使用している半導体プロセスはTSMCの7nmプロセスである (出典:このレポートのすべての図はHock氏の講演スライドの抜粋である)

CerebrasのCS-2システムは12Uの筐体に収容されており、写真の女性が上げている右手の先のところまでがCS-2の本体である。そして、その上に挿入されているプリント板やその上の装置は複数台のCS-2を接続するネットワーク(SwarmX)と、大容量のメモリ(MemoryX)などであると思われる。
-

下側に並んでいるパンチングメタルの筐体がCS-2である

CS-2はTensor FlowやPyTorchなどでプログラミングでき、Cerebrasのコンパイラを使って実行形式を作ることができる。CerebrasのコンパイラはMLネットワークをカーネルグラフに変形し、CS-2にどのようにマッピングするかを決定して実行形式のコードを生成する。
-
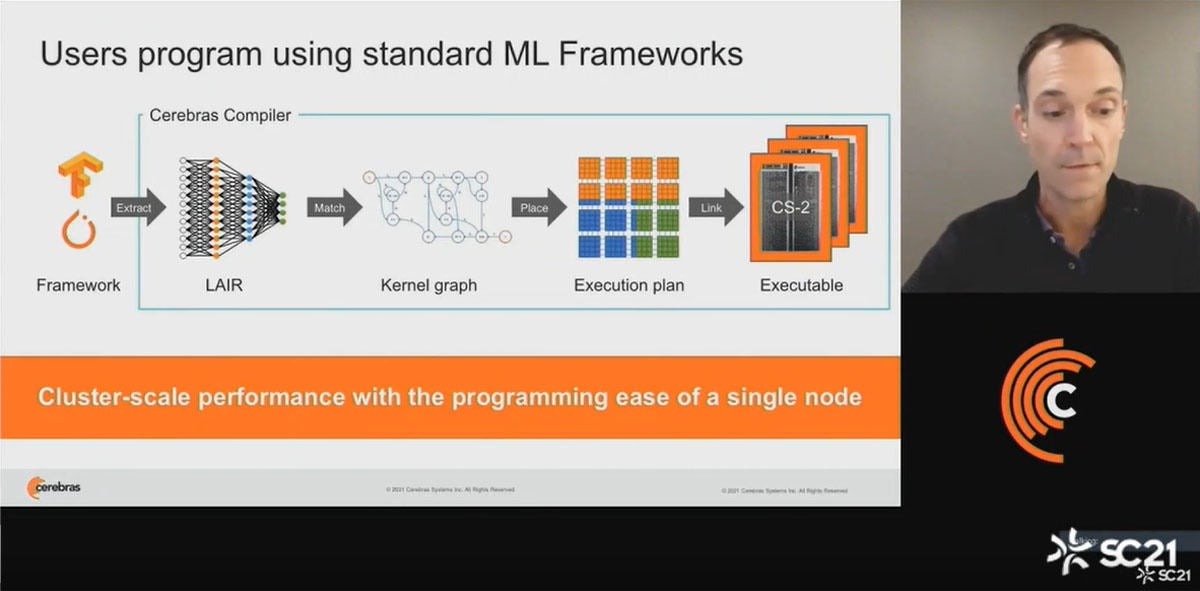
CerebrasのCS-2はTensorFlowやPyTorchでプログラムできる。CerebrasのコンパイラでAIコアに割り付けて実行形式を作る

CerebrasのアーリーユーザであるPittsburgh Supercomputing CenterではCS-1を2台運用しており、これを使って17のプロジェクトを推進しているという。
-
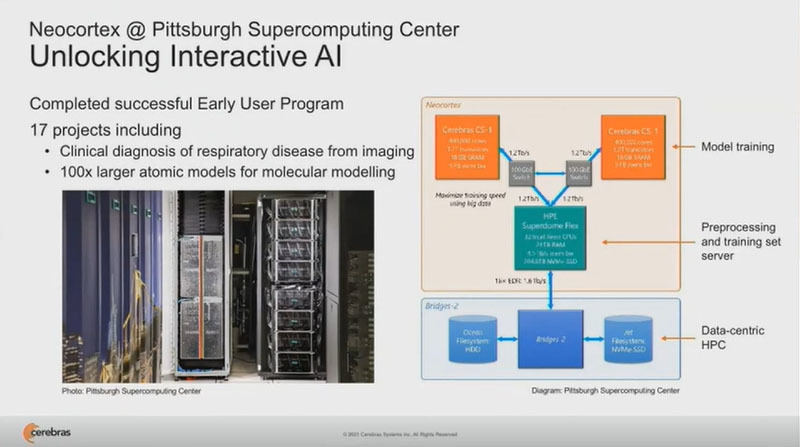
Pittsburgh Supercomputer Centerでは2台のCS-1を使って17個のプロジェクトを推進している

Lawrence Livermore国立研究所ではCPU 794個とGPUを3168個使用する大型のLassenスパコンとCS-1を接続して使い、CS-1はAutoencoderと推論を処理している。推論の処理性能は18M/sで、これはLassenと比べて37倍高速という。
-

Lawrence Livermore国立研究所ではGPUベースのLassenスパコンとCS-1をつなぐヘテロな接続を行っている。CS-1は推論の実行では18M/sの性能を持ち、これはLassenと比べて37倍速い。CS-1は搬入開始から20時間で稼働を開始した

国立Energy Technology Laboratoryでは、CS-1は疎な係数の連立1次方程式の解の計算を、Joule 2.0スパコン(ピーク6.7PFlops)より200倍速く実行し、リアルタイムの流体解析を追い越す性能になって来ている。これはCS-1の巨大なメモリバンド幅に負うところが大きい。
-

NETLのシステムは高性能でCFDをリアルタイムで計算できる。これはCS-1の巨大なメモリバンド幅が効いている

自然言語処理を行うBERTは3年前には110Mパラメタであったが、この2年で、モデルは1000倍大きくなり、学習に必要とされる計算量も1000倍大きくなった。
175BillionパラメタのGPT-3を1024GPUのシステムで学習させるには4カ月かかる。しかし、近い将来にも数兆個のパラメタやそれ以上のパラメタのモデルが出てくると考えられる。
-

BERTは2018年には110Mパラメタであったが、1024GPUを使っても学習に4か月かかった。今では、これの1000倍のモデルができており、計算量も1000倍になっている

より大きなモデルの学習に複数のGPUを使っても、次の図に見られるように、1000個のGPUを使えば60倍の性能になるところが、実際には10倍程度にしかならず、分散学習ではあまりうまくスケーリングは行えない。
-
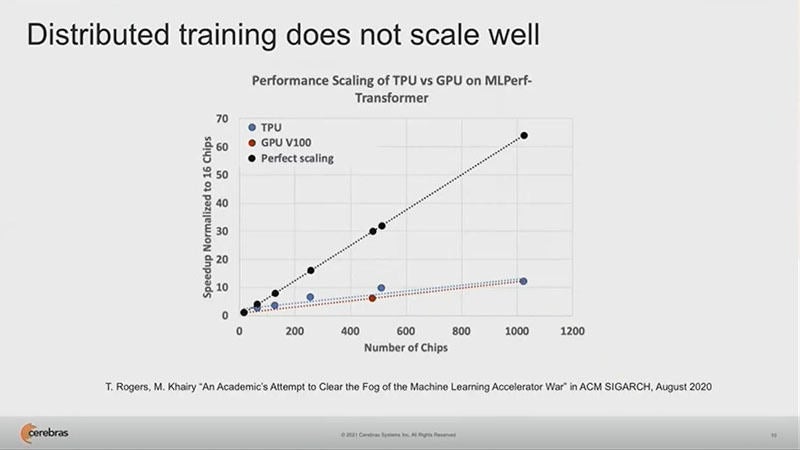
TPUやV100 GPUを使う分散学習では、理想的なスケーリングの1/6程度の性能しか得られない

そこで、Cerebrasは、Weight streamingという方法を考案した。Weight streamingではパラメタメモリをコンピュートから分離する。CS-2ではこの最大120兆パラメタを格納できるMemoryXという装置を接続する。次の図のようにSwarmXというボックスで複数のCS-2とMemoryXの間をつなぎ、WeightsとGradientsの転送データのルーティングを行う。
このようにすることで、192台のCS-2を接続した構成まで、ほぼリニアにスケールするシステムが作れるようになるとのことである。
これで、GPT-3の学習が1日でできるようになり、1兆パラメタのモデルが長めの週末で学習ができるようになることを想像して欲しい。
-
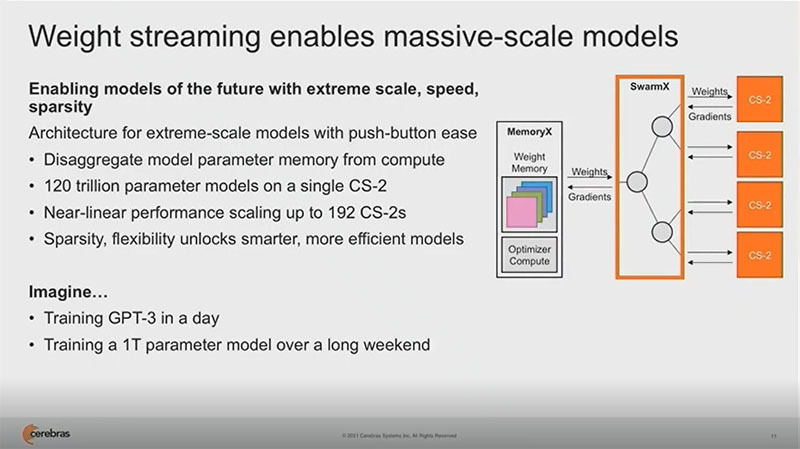
Cerebrasは重みを格納するMemoryXと、重みと傾きを転送するSwarmXというボックスを開発した。これで192台のCS-2をほぼリニアにスケールする接続ができる

Cerebrasは2021年の12月にCerebras SDKをリリースする計画である。このSDKには、開発中のC言語ベースの新しいDomain specificな言語を含む予定である。
-
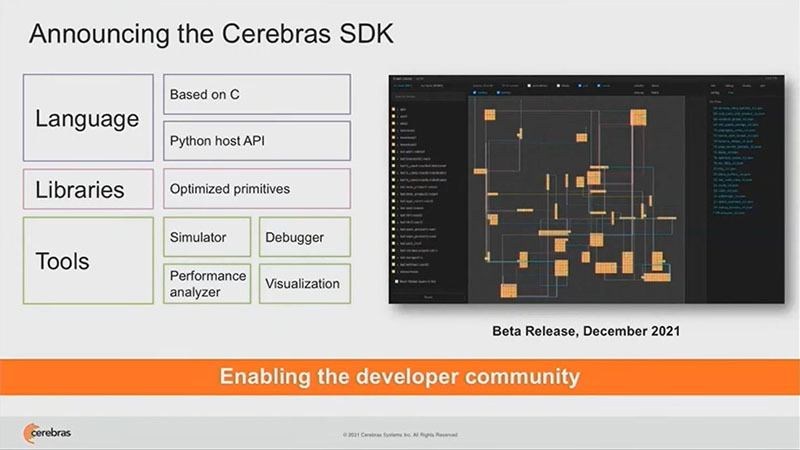
Cerebrasは12月にSDKの提供を開始する予定である。それには新しいDomain Specific言語を含む

なお、Cerebrasのシステムは、CS-2を購入しなくても、Cirrascale社のクラウドで使うことができるようになっている。











