



Larrabeeの全体構造は、CPUコアとL2キャッシュのペアの間をリングバスで接続する構造になっており、分散ディレクトリとMOESIプロトコルで、全コアのL2キャッシュのコヒーレンシを取っていると説明された。この部分については、SIGGRAPHやIDFでは全く触れられておらず、HOT CHIPSでの新規の発表である。
 |
Larrabee Ringのコヒーレンシメカニズム |
各コアは自分のL2キャッシュには高速でアクセスが出来、できるだけこの部分で処理できるようにプログラムを作る必要があるが、他のコアのL2キャッシュもコヒーレンシを持った形でアクセスできるようになっている。そして、リモートのキャッシュをアクセスする場合は、分散ディレクトリを参照して、目的のデータがあるL2キャッシュを判別してアクセスを行うという動作になる。ディレクトリを分散して複数にしたのは、一つのディレクトリにアクセスが集中すると捌き切れないためという。そして、コヒーレンシプロトコルにOwnステートを追加してMESIからMOESIに変更したのは、各コアのL2キャッシュ間でキャッシュラインのオーナーシップの直接の移行を可能にするためと言う。
リングバスでコアや各ユニットを接続する構造であるので、1個のリングに沢山のユニットをぶら下げてしまうとリングが長くなりレーテンシが遅くなってしまうし、バンド幅も不足になるので、SIGGRAPHの論文では最大16プロセサコア接続に限定すると書かれている。そして、これを超える場合は、複数のリング間を繋ぐXringというリングを使うという拡張方法が明らかになった。
 |
マルチリングとそれらを繋ぐXringを持つ拡張構造 |
この図では、それぞれのリングに2箇所の接続点をもつXringが描かれている。3Dグラフィックスの描画であるが、曲面を分割したトライアングル単位に各種のシェーディング処理を行ってラスタ化して、フレームバッファとなるメモリに書き込む。NVIDIAのGPUなどでは、一つのトライアングルに対しては一連のシェーディング処理を1回行うだけでフレームバッファに書き込むデータを生成する。そして、書き込むフレームバッファ領域のメモリアドレスを担当するラスタユニットが、分担して処理を行う直接方式という方式が用いられている。しかし、この場合は、最終的にはフレームバッファメモリ上でブレンディングを行うので、メモリのリードライトが頻繁に発生する。このため、NVIDIAのGPUなどでは、高速のGDDRメモリを使い、最大では512ビット幅というような構成で、大きなメモリバンド幅を実現している。
これに対して、Larrabeeでは各コアが自分のL2キャッシュに格納できる程度のサイズのタイルと呼ぶフレームバッファの小領域を担当させるBinning Renderingという方式を用いるという。この方式では、一つのトライアングルが複数のコアのタイルに跨る場合は、それぞれのコアで同じシェーディング処理を行う必要があるので、演算回数は増加する。しかし、ブレンディングのためのメモリへのリードライトが、高速なL2キャッシュのリードライトで済んでしまうので、フレームバッファメモリへのトラフィックはかなり減少する。
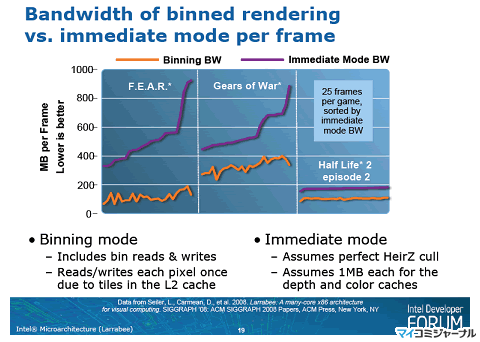 |
直接方式とIntelのビン方式の描画のメモリトラフィック量の比較 |
この図のように、ゲームによっても違うが、ビン方式の描画により、メモリトラフィックは大幅に減少している。












