



グラフィックプロセシングのカナメは、32ビットの演算を16並列で実行するベクタユニットである。このベクタユニットは32ビット整数、32ビットの単精度浮動小数点数、64ビットの倍精度浮動小数点数を扱うことができる。
何故、32ビット×16並列の512ビット幅のベクタ演算器なのか、256ビット幅にしてNehalemの次世代のSandyBridgeで実装予定のAVX(Advanced Vector Extension)との機能の共通化をしないのは何故か、また、1024ビット幅にして、コアあたりの演算性能を2倍にして、一定性能ではコア数を半減するというアプローチを取らなかったのかという会場からの質問に対しては、256ビットから512ビットにするとかなり性能が上がり、そこから1024ビット化しても性能の向上が少ない。このため、512ビット幅を選んだという答えであった。また、AVXは汎用的な計算処理を目指しているが、Larrabeeのベクタユニットはグラフィックス処理をメインに考えており、最適化のポイントが違うと述べていた。
 |
 |
|
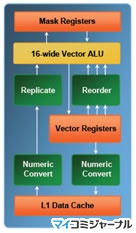
IDF(左)とHOT CHIPS(右)で示されたベクタユニットの図 |
|
ベクタユニットの構造であるが、IDFで示された図とは多少、異なる構造が示された。IDFの図では、ベクタレジスタからベクタALUの間にReorderというブロック、L1データキャッシュからベクタALUのパスにReplicateというブロックが入っているが、HOT CHIPSの図ではこれが無くなっている。しかし、右側の説明文からは、これらのブロックが無くなっているとは考え難いので、多分、 Carmean氏の意識ではこれらはベクタALUに含むのではないかと思われる。また、もう一つの違いはベクタレジスタの1本の出力がConvertと書かれた数値表現形式の変換ユニットを通っている点である。そして、HOT CHIPSの図は、ベクタALUの出力はマスクレジスタを経由してベクタレジスタに格納される構造となっており、マスクレジスタの出力がベクタALUとなっているIDFの図とは異なっている。







