Memory Controller
RaphaelとGenoaの違い、というかRyzenとEPYCの最大の違いがMemory Controllerである。勿論EPYC Gen 1/Gen 2はZen 1/Zen 2コアそのままだったからMemory ControllerもRyzenと差が無かったのだが、Zen 3以降でMemory ControllerがIODに移ったことで、ここの設計と実装は完全に異なるものになった。
さて、そのMemory Controllerであるが、Photo15の左下にあるように、12chのDDR Memoryを装着可能である。サポートされるのはRegistered DIMMと3DS Registered DIMMである。容量についてはちょっと次のスライドで説明したい。あとここで特徴であるが、GenoaではVirtual/Physical Addressが57bit/52bitの実装となっている。つまり仮想アドレスは128PB分、物理アドレスも4PB(4096TB)分ある事になる。実はこれ、CXL Memoryを考えた時に非常に重要なポイントである。Zen 3まではVirtual/Physical Addressが48bitで、これは最大256TBに相当する。DDR5をフル実装すると、現世代では6TB/Socket(256GB/DIMM)だが、次世代DDR5は12TB/Socket(512GB/DIMM)が視野には入っているが、それでも256TBあれば十分に見える。ただこれはCXLを考慮に入れなければ、の話である。詳しくはCXLの所で説明するが、GenoaではPCIe Gen5 x16接続のCXLデバイスを4つまで接続できる。ただGenoaはx16レーンを4つのx4レーンに分割可能で、なので最大構成だと16個のCXLデバイスが接続可能だ。ここに各々16TBのNAND Flash SSDを接続したら、もうこれだけで256TBであり、48bitアドレスだと飽和することになる。ところがGenoaでは52bitなので、この構成でもまだゆとりがある(計算上は256TBのNAND Flash SSDを繋がない限り大丈夫)訳で、このあたりはきちんとCXLを考慮した構成になっていると言える。
-

Photo15: ただAMDは2 Socketシステムでは1 DIMM/chを推奨している(1 Socketシステムは2 DIMM/ch)ので、実質ノードあたり6TBというのが上限ではある。

ちなみにReference Platformに関して言えば、1 Socketは2 DIMM/chを、2 Socketでは1 DIMM/chを推奨している(Photo16)。理由としては2 DIMM/chになるとメモリ速度をDDR5-4400まで落とす必要があるので、メモリ帯域そのものは減ること。それとmemcachedの様に搭載メモリ量がモノを言う(そしてプロセッサ性能はそこまで要らない)用途であれば1 Socket Serverで十分であり、そうした用途向けには2 DIMM/ch構成が適切であるが、通常のアプリケーションであればそもそも12TB/Socketものメモリ容量は不要で、6TB/Socket程度で十分である、という判断のためであろう。あともう一つ言えば、物理的に無理、という話もある。Photo17はAMDのGenoa向けの2 Socket Reference BoardであるTitaniteと言うボードの部品配置図である。実は良く見るとDIMM Slotが28本(DIMM AとGのみ2つ用意されている)あるが、この28本+CPU Socket×2でもうほぼ横幅一杯なのが判る。物理的にも1 DIMM/chにするのが現実的、という話である(19inchラックに収める必要が無ければ、また色々やりようはあるのだろうが)。余談だがDIMM A/Gのみ2 DIMM(実際にはパターンが来てるだけで、DIMMソケットそのものはA0/G0には装着されていない)なのはTitaniteが開発とか検証用のプラットフォームなので、2 DIMM/chでの動作を確認出来るように用意されているだけで、別にそう使う事を推奨している訳では無いとの事だった。
-

Photo16: このスライドは以前も使った。

-
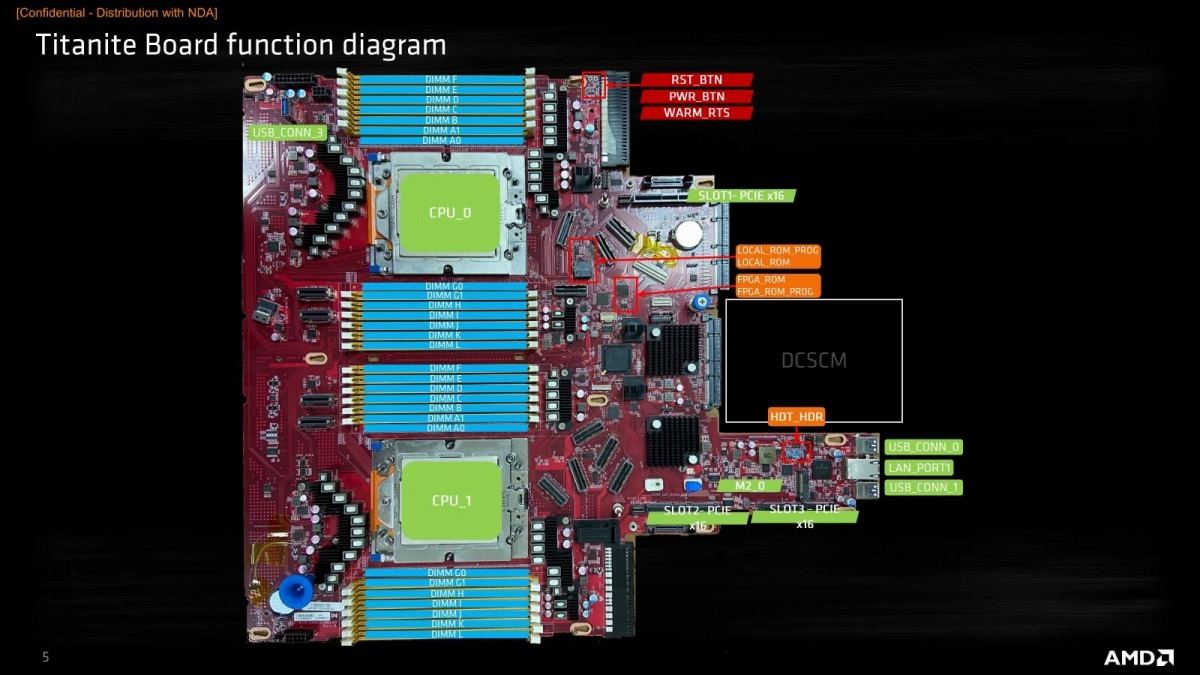
Photo17: ちなみに横幅はこれで19inchラック一杯である。どう考えても48本ものDIMM Slotを配する場所がない。無理にやるとしたら、CPU Socketを前後にずらすか、DIMM SlotをRiser Card経由にするしかないだろう。

それとメモリ容量であるが、今回説明している最大12TB/Socketというのは、256GB 3DS Registered DIMMを前提にした話である。256GB×24=12TBな訳だが、例えばSamsungは2021年3月に512GB DDR5 Moduleの量産を発表しており、おそらく現在IntelやAMDと評価を行っている最中とみられる。こちらを使った場合、メモリ容量は2倍になる計算である。もっともハイエンドのEPYC 9654(96core/192thread)の2 Socketシステムでも同時実行数は384thread。12TBという容量はthreadあたり32GBを占有できる計算になる訳で、これをさらに増やすニーズがどの程度あるか? と言われると、相当巨大な科学技術計算など以外は想像が付かない。その意味でも割とWell balancedな容量と考えて良いかと思う。
話をMemory Controllerに戻す。Genoaでは72bitと80bitの2種類のRDIMMに対応している(Photo18)。元々DDR5の世代では、64bit幅のデータバスを2つの32bit幅に分けてそれぞれ独立に動作する様になっているが、このためECCはそれぞれ個別に必要になる。従来だと64bit幅のデータに対して8bitのECCが付加される格好だったが、DDR5世代のRDIMMでは32bit幅のデータに対して4bit ECC(ECC4)と8bit ECC(ECC8)の2種類のECCの付加の選択が可能になっている。ECC4を使う場合は36bit×2で72bit、ECC8なら40bit×2で80bitになるが、例えばx8構成のDRAMチップを使う場合、ECC4なら9チップで構成できるのに対してECC8では10チップ構成になり、コストが上がる。その一方でECC8の方が強力な保護が可能ということで、後はニーズとコストを勘案して選ぶ格好だ。先に書いたように、どちらでもGenoaでは利用可能である。
-

Photo18: DDR5世代ではDRAMチップ側にもECC(On die ECC)が搭載されており、こちらとAMD-Cを併用する事が可能である。

またサーバー向けということでAMD-C(Advanced Memory Device Correction)も搭載されている。AMD-Cは初代EPYCから実装されているアルゴリズムで、一つのDRAMチップ内のSingle Bit Errorだけでなく列/行/バンク/複数バンクに跨る障害に対応できるように設計されている。このあたりの実装はConsumer向けのRyzenと全く違う部分である。
Ryzenと異なる部分という意味ではMemory Populationの考え方も異なる。Photo15にもちょっと出ているが、Genoaではフル構成(12chに全てDIMMを実装)以外に2/4/6/8/10chでの構成もサポートしている。そもそもGenoaではNPS(Nodes Per Socket)という考え方がある。これは要するにNUMA分割に絡む話で、CPU全体を一つのNUMAノードとする場合、NPS1が利用される。一方で2 NUMAノードに分割するのであればNPS2、4 NUMAノードならNPS4が利用される格好だ(Photo19)。12chすべてにDIMMを実装している場合は、NPS1/2/4のどの構成も可能であるが、2~10枚の場合はこの辺に多少制約が入る(Photo20~22)。ちなみに1枚のみの構成も一応可能となっている(Photo23)。このあたりは構成の自由度を最大限に確保できるように工夫されている格好だ。実際のところ、例えば最大構成のEPYC 9654なら12CCDに対してDDR5が12chだから、CCDが1個あたりDDR5が1chというバランスになる。なので64core(8CCD)のEPYC 9554ならDDR5は8chでEPYC 8654と同じ帯域だし、32coreのEPYC 9354なら4chで同じ帯域になる訳で、あとは性能と価格のバランスで考えれば良いからだ。
-

Photo19: 1/2/4分割までしかサポートしていないのは従来のEPYCと同様。

-

Photo20: 10chの場合は、NPS1/2のみ。

-

Photo21: 8chだとNPS1/2/4が可能だが6chだとNPS1/2のみ。

-

Photo22: 4chだとNPS1/2/4が可能だが2chだとNPS1/2のみ。

-

Photo23: この場合はNPS1のみ。

ところで一つ気になるのはMemory Controllerそのものの性能である。と言うのは、Desktop向けのRyzenシリーズの場合、Memory Controllerの特性がDesktop向けに最適化され過ぎていたからだ。判りやすいのは、以前Ryzen 7000シリーズを試した際のRMMT Readの結果だろうか。これはWindows環境で、Threadあたり40MBのRead Requestを出し、その際のトータルのRead Bandwidthを計測するテストである。この際Ryzen 7000系のメモリ設定はDDR5-5200 CL44の2ch構成で、理論上のBandwidthは83.2GB/secになる。実際の性能はグラフからも示されるように、Ryzen 9 7950Xはピークで95.5GB/secを叩き出している。これは32MB×2のL3キャッシュにHitしている部分では当然帯域が増えるためでおかしくは無いのだが、おかしいのはこれが5 Thread動作時の性能であり、8 Threadでは67.7GB/secとかなり低めに推移していることだ。これはZen 3世代のRyzen 9 5950Xも同じである。DDR4-3200の2chなので理論帯域は51.2GB/secに対してピークは64.1GB/secと上回っているが、これは5 Threadの場合。8 Threadだと54.3GB/secと10GB/sec以上下回る値になっている。そもそもDesktopの場合、全てのThreadから同時にMemory Access Requestが出る事は非常に稀であり、むしろ全体のなかで少数のコア(というか、Thread)が集中してMemory Accessするようなパターンの方が多いだろう。恐らくRyzenのIODに搭載されたMemory Controllerはこうしたニーズに対応する様に設計されており、なので多数のCore/Threadから一斉にMemory Requestが殺到するような構成ではQueueが長くなるというか溢れる事になり、Core側のLoad Requestに対して迅速に反応ができなくなる(RequestへのAckを送らない事でFlow Controlを行っている)と思われる。実際Desktop向けに、膨大なI/O Request Queueを用意するのはリソースの観点から見ても無駄が多い。
ただこれはServer用途に向いた設計とは言えない。そこで、実際のところどうか? というのをちょっと確認してみる事にした。実は今回AMDのLabに設置されたEPYC 9654の2 Socket Systemをリモートで利用する機会に恵まれた。生憎競合製品とかMilanベースのシステムとの比較を行う事は出来なかったし、リモート(設置場所は米テキサス州オースチンだったので、物理的に10000Km彼方である)ということでOSの入れ替えなどは不可能だったしアプリケーションのインストールも難しかったのだが、とりあえずメモリ帯域の測定の為にStreamを実施することが可能だったので、この結果をご紹介したい。
プラットフォームは先ほどPhoto17でご紹介したTitanite Boardで、ここにEPYC 9654×2と64GB DDR5-4800 RDIMM×24(合計容量1.5TB)が搭載されている。OSはLinux(Kernel 5.15.0-52-generic)がインストールされている状態だ。
ベンチマークだが、スタンダードなところでstreamを利用した。テスト方法だが、このstreamをOpenMP Enableな状態(gcc -O -fopenmpでコンパイル)にしたうえで、
- 同時実行スレッドを1~384まで可変
- streamのArray Size(テストに利用する配列数)を1億個~13億個まで1億個ずつ増加(ArrayはDouble:8byteなので、アクセスするメモリ量としては76.3MB~534.1MBになる(13億個までなのは、それ以上増やすとコンパイルエラーが起きるためである)。
という条件で実施し、その際のTriadのBandwidthをプロットしてみたのがグラフ3である。スレッド数が最大384といっても実際はメモリ共有をする関係で、最大構成(384 Thread/13億個)でも消費メモリ量は2.9GBに過ぎないので、1.5TBのシステムで確認するには十分である。
-

グラフ3

さて結果であるが、必要メモリ量が少ない範囲(1~4億個)位までは結構L3キャッシュ(2 Socketで合計768MB)にHitする確率が高い(というか、3億個だと全体で686.6MBしか必要としないので、完全にL3でHitする)事もあってかなり広めの帯域になっているが、5億個以降ではL3が飽和する事もあり、実際にメモリアクセスが発生する事もあって、Thread数が増えるにつれて実効帯域が減ってゆく(それだけメモリアクセスの頻度が上がるため)。10~13億個になると、もうL3の効果が殆ど無くなるので、ほぼ生のメモリアクセス性能が示されていると考えて良いかと思う。ちなみに1~3億個で192 Threadの時に大きなギャップがあるのは、このタイミングで1 Socketの有効Thread数を使い切り、2 Socket目に移るためと考えられる。残念ながらStreamのOpenMPの実装は、2つのCPUを均等に使うのではなく、まず1つ目を使いつくしたら2つ目に移る感じになっているようだ。ただ同一CPUの中では、12個のコアを均等に使う様にスケジュールされている様に見える(96 Threadあたりから、24 Thread周期で三角波の様な傾向が示されているのがその傍証だ)。
まぁそうした特徴はともかくとして、384 Threadをフルに動かした際のBandwidthを見ると
| 10億個 | 688.2GB/sec |
|---|---|
| 11億個 | 669.2GB/sec |
| 12億個 | 652.5GB/sec |
| 13億個 | 640.4GB/sec |
といったところで、概ねこの640GB/secあたりがStreamを使った場合のピーク性能と考えて良さそうだ。理論帯域はDDR5-4800×12ch×2 Socketで921.6GB/secだから、効率は69.4%とかなり高い(通常streamだと60%程度になるのが普通)。また、RyzenのRMMTの時の様な、Thread数による変動もそれほど大きくない。なにより、3GBほどのアクセスを連続して行っても殆ど性能に変化が無い辺りは、Ryzenとは全く異なるメモリコントローラの実装になっていることの証明ともいえる。実は筆者、このメモリコントローラ周りの癖が一番気になっていただけに、ちょっと安心である。
ちなみに検証のために、Ryzen 7 7700XとRyzen 9 7950Xでも同じように実施してみた結果がグラフ4と5である。こちらはUbuntu Desktop 22.04(Kernel 5.15.0-58-generic)で実施している。メモリはDDR5-4800構成だ。Thread数はそれぞれの製品に合わせて最大16 Thread/32 Threadにしている。
-
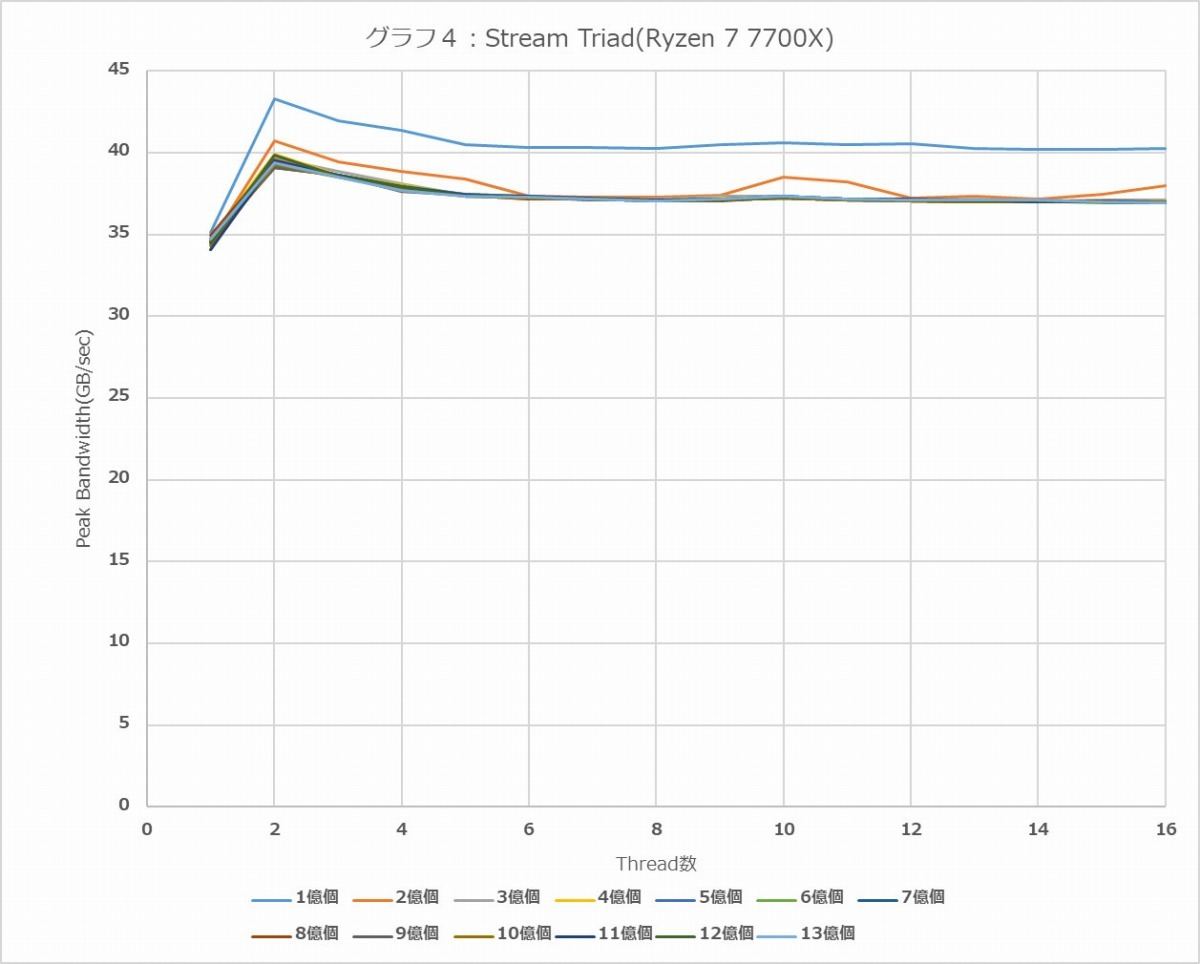
グラフ4

-

グラフ5

こちらでも1億個だと76.3MBしか使わない関係でかなりL3が効果的に作用する関係でやや高い帯域を示すが、13億個あたりになると最早Ryzen 9 7950XでもL3が飽和するので、ほぼ地のメモリ帯域が示される格好だ。で、13億個の数字で言うと、
| Ryzen 7 7700X | 36.8GB/sec |
|---|---|
| Ryzen 9 7950X | 36.3GB/sec |
といったところで、どちらも理論帯域(DDR5-4800×2chで76.8GB/sec)の47~48%程度の効率でしかない事を考えると、Genoaのメモリコントローラの効率が実に良い事が伺い知れる。ついでに言えば、グラフ4・5共に2 Threadの時にピークがあり、そこからじわじわと性能が下がってゆく、というあたりがRyzen 7000シリーズのIOD内蔵Memory Controllerの癖であり、これをRMMTだけでなくStreamでも確認できた格好だ。