
米AMDは米国時間の10月10日、サンフランシスコで第4世代EPYCの発表会を行った。この内容はオンラインでも同時配信されるが、これに先立ってこの第4世代EPYCの説明を受けたので、その内容をご紹介したいと思う。
第4世代EPYCはGenoaというコード名で知られている製品であり、昨年11月に開催されたAMD Accelerated Data Center Premiereの折にも名前が出て来ている(Photo01)。このGenoa、既にこの時点で特定顧客へのサンプル出荷が開始されていることが発表されたが、サーバー向けはどうしても検証期間が長くなりがちであり、逆に言えば1年以上を掛けてみっちりと検証が終わった、という話でもある。このGenoaは12ダイのCCD+IODという構成になることも、既に公開されている(Photo02)。ということで今回の発表に移りたい。
-

Photo01: これに後追いでZen 4cがBergamoとして2023年投入とされている。

-

Photo02: まぁこれを見ればCCDが3つづつ4組である事は明らか。

まず製品説明からご紹介する。Genoaを構成する4つの柱がこちら(Photo03)。ソケットあたり性能、コアあたり性能、ワークロード/マーケットに拠らない高性能、それとTCO削減である。そしてGenoaは、これを実現した(Photo04~06)としている。
-

Photo03: このPer-Core PerformanceとかSocket Performance、消費電力を上げれば簡単に実現できるが、それとTCO削減が両立しないのはRaphaelとかRaptor Lakeの性能と消費電力の関係を考えれば容易に理解できる。ので、どのあたりでバランスさせるかの選択が難しいところ。

-
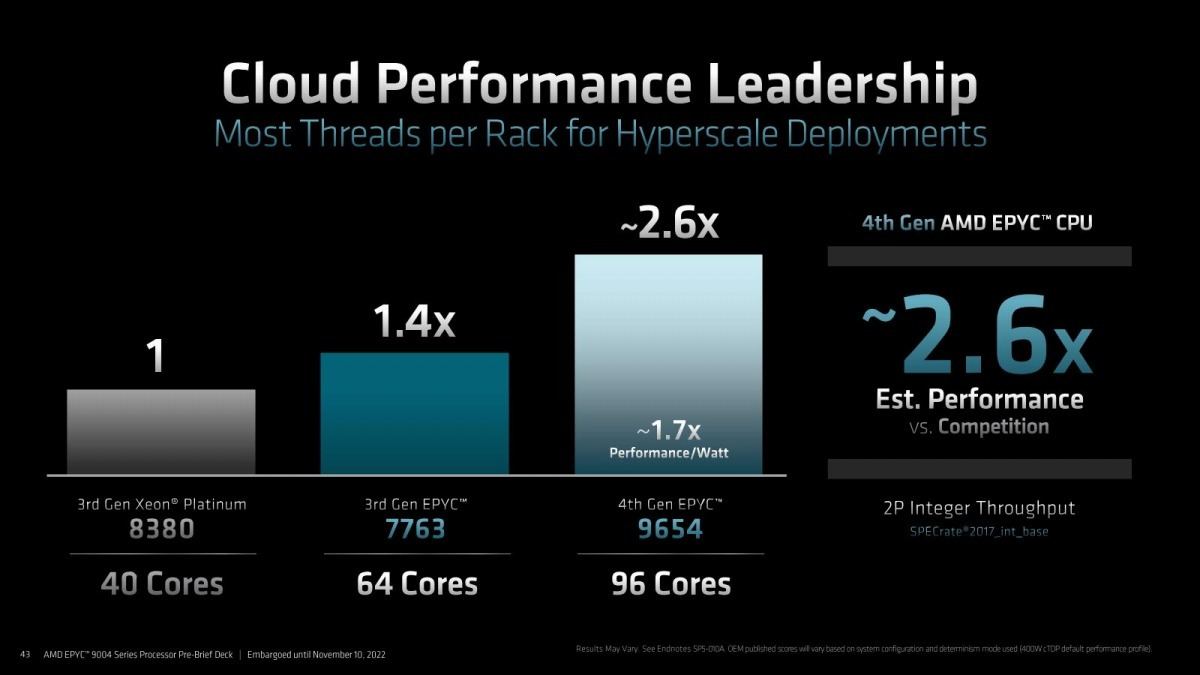
Photo04: SPECrate2017_int_baseでの比較。まだSapphire Rapidsが出てこないので、Xeon Platinum 8380との比較にならざるを得ないのはまぁ止むを得ないところ。

-
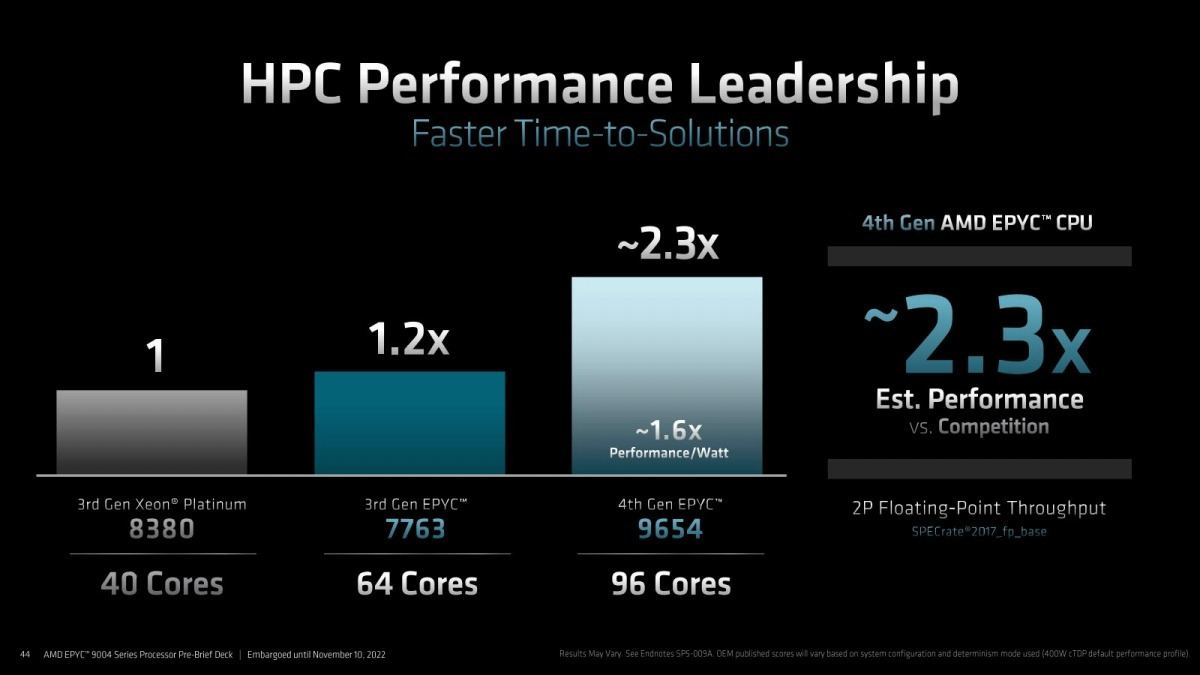
Photo05: こちらはSPECrate2017_fp_baseでの比較。とりあえずGen 3 EPYCであるEPYC 7763と比較しても圧倒的な高速化が図られているのが判る。

-
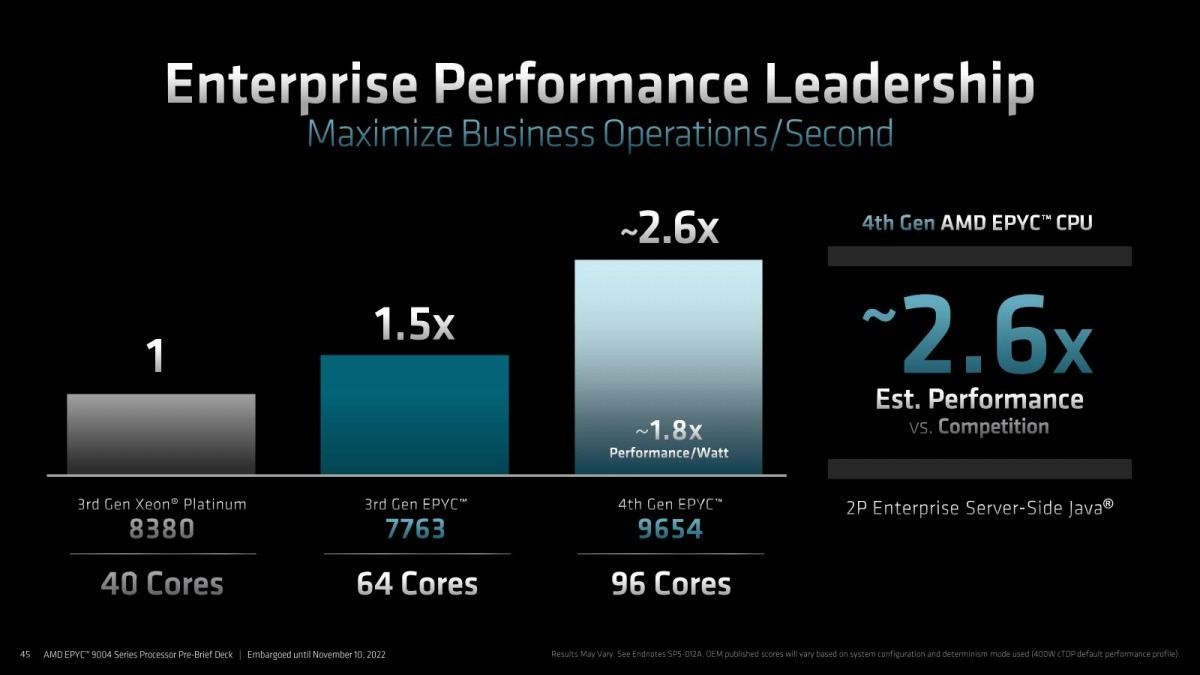
Photo06: 結果はともかくとして、この"2P Enterprise Server-Side Java"が何かが今一つ不明である。TPCではなさそうだし、SPECjEnterprise 2018辺りだろうか?

さて、このPhoto04~06で判るように、Genoaでは製品名が7000シリーズから9000シリーズに変更となり、EPYC 9004となった。Photo07が製品一覧である。型番のルールは次に出てくるが、Fは動作周波数を引き上げた(その分消費電力の多い)モデル、Pは1P構成モデルとなる。その具体的なルールがこちら(Photo08)となっている。
-
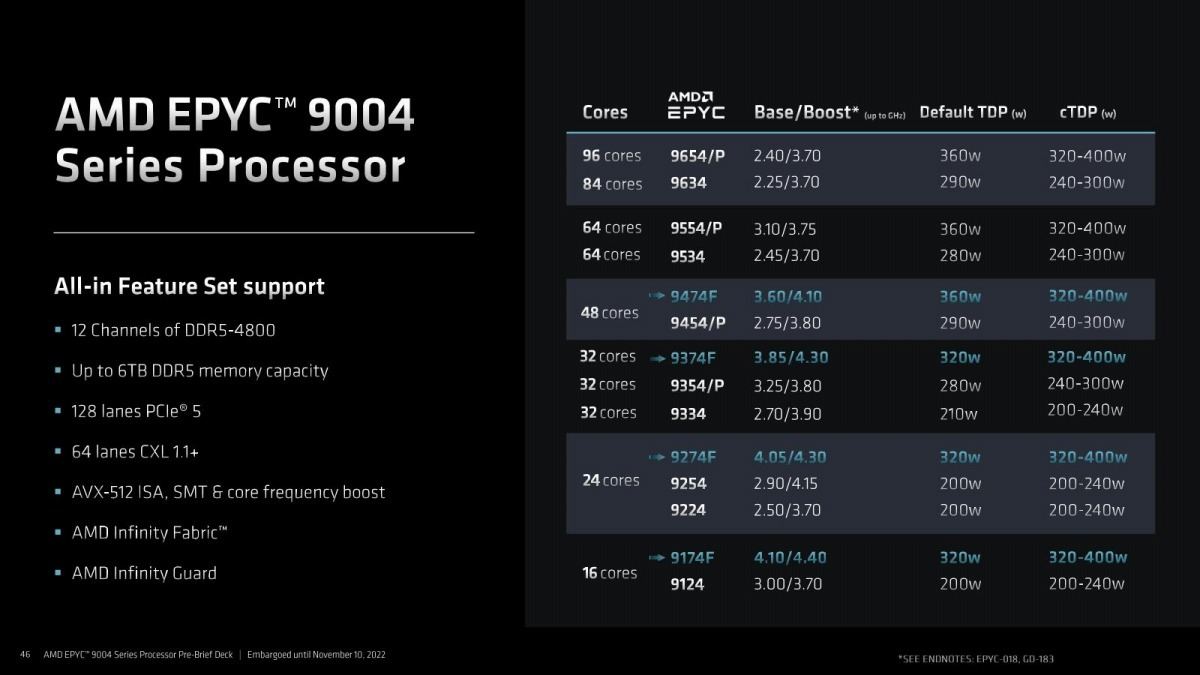
Photo07: デフォルトTDPは遂に360Wに達するが、冷静に考えると96コアで360Wだから、IODの分を無視してもコアあたり4Wかそこらであり、全体としては結構な消費電力とは言え、言うほど消費電力が増えた訳でも無い。要はコアの数が多いのが理由である。

-
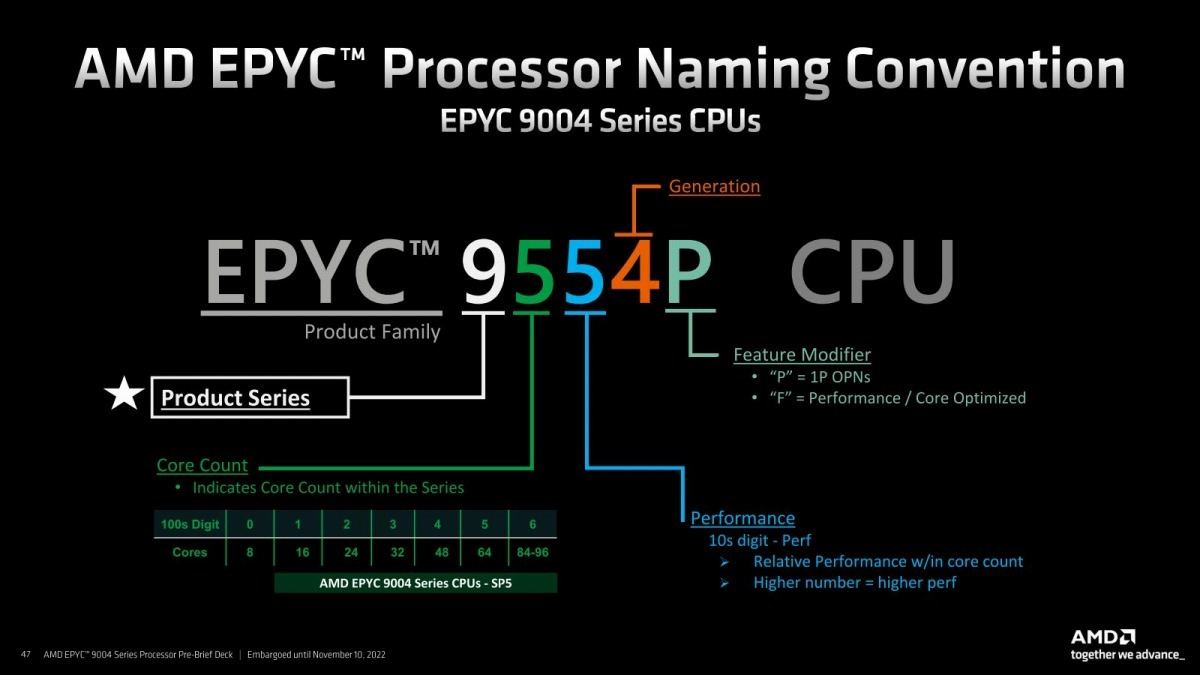
Photo08: 一応2桁目は性能に応じて変更できる事になる。まぁ今後ラインナップを増やし過ぎると、そのうちEPYC 95A4Pとかを登場させざるを得なくなりそうだが。

実はそもそも今回何故Product Familyが9000番台になったのか、明確な説明が無かった(質疑応答でもこの話題は出たのだが、「性能とポジショニングを鑑みて」という謎の回答しかなかった)。何となく思いつくのは、来年投入されるZen 4cことBergamoベースのEPYCと区別するためではないかというあたりだ。ただBergamoが7004か? というとこれもちょっと謎で、案外BergamoはEPYC 5004とか8004とかになるのかもしれない。
まぁまだ詳細が発表されていない製品の事はともかくとして、そのEPYC 9004シリーズのポジショニングがこちら(Photo09)。HPCなどにはCore Performanceグレードを、CloudなどにはCore Densityを、オンプレミスを含む汎用にはBalanced and Optimizedグレードをそれぞれ選ぶのが妥当、という説明だ。実際第3世代EPYCでも64コアをフルに使う用途は本当にクラウド向けとかVDI Service向けなど割と限られており、32コアあたりの製品のニーズが多かった。この傾向は第4世代EPYCでも継承されると見ているらしい。
-
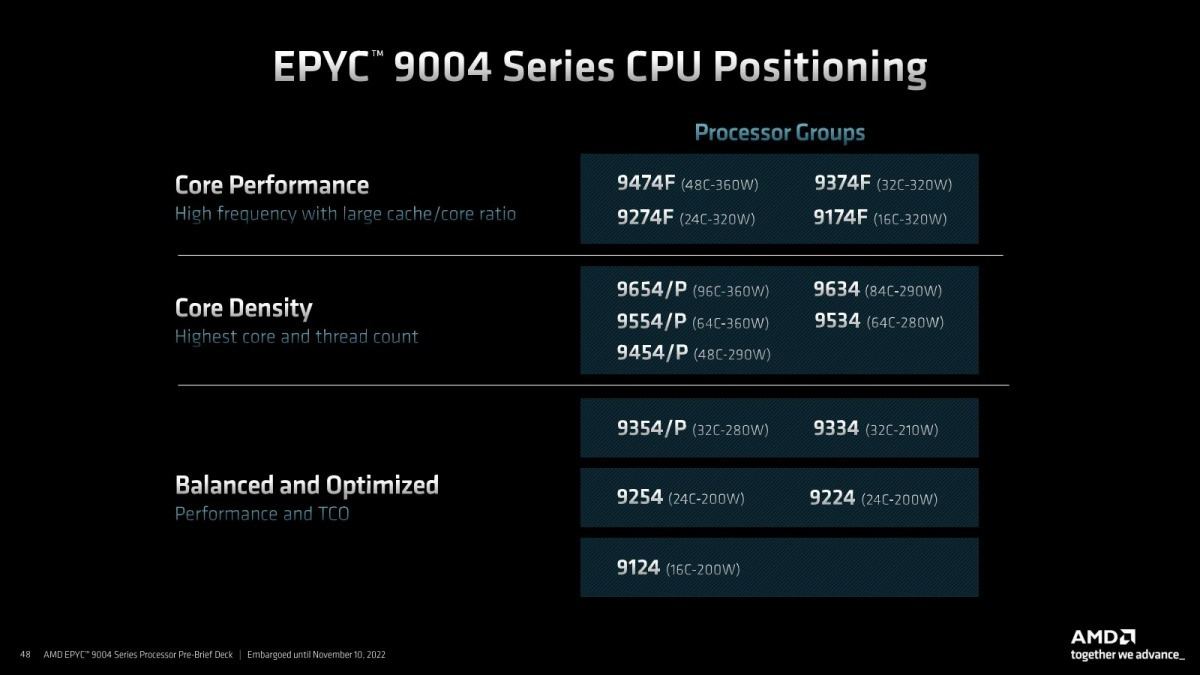
Photo09: メインストリームはBalanced and Optimizedという位置づけになる。

EPYC 9004シリーズの性能比較がこちら(Photo10)。ほぼモデルナンバーの順に性能がスケールしているのが判る。流石に96コアのEPYC 9654は他と比べても飛びぬけてる感はあるが、基本的にほぼスケールする形でラインナップが用意されているのが判る。
-
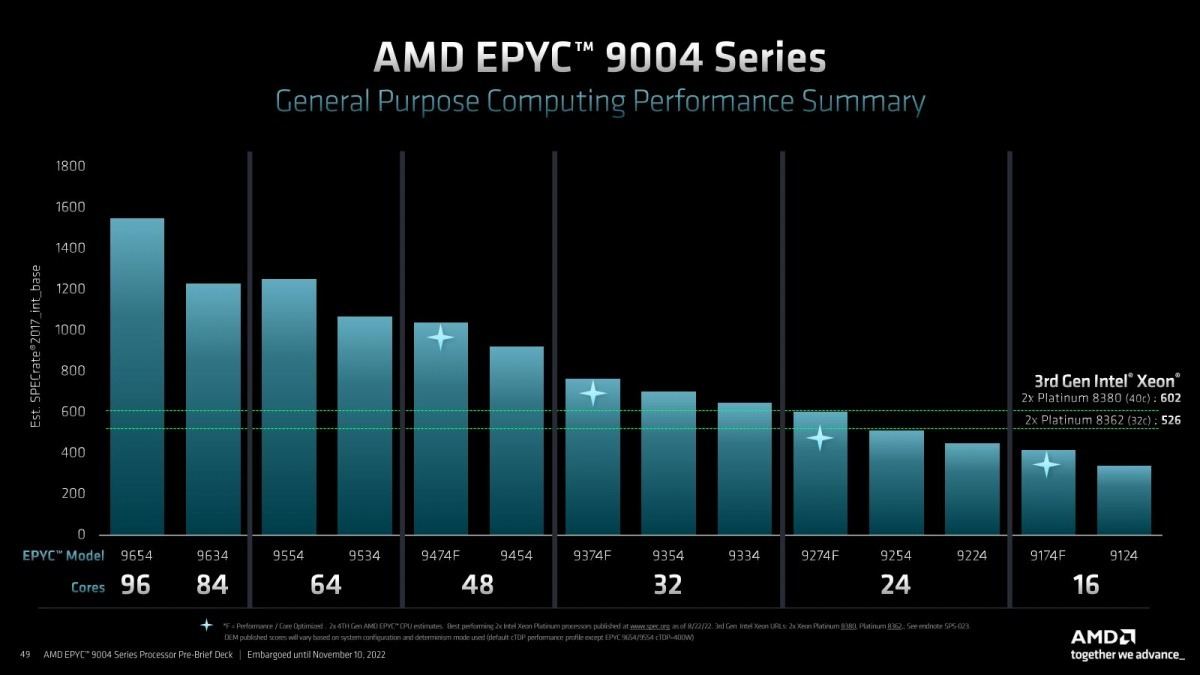
Photo10: これは素直にSPECrate2017_int_baseの性能を比較したものなので、実際のアプリケーションはまた違った傾向になると思われるが。

さて、比較対象が相変わらずXeon Platinumといのはこの際目を瞑って頂くとして、ここからは性能比較パートである(Photo11~19)。Desktop向けと異なり、割とコアの数にスケールする(≒アーキテクチャの違いによる性能の増分が少ない)結果になっているのは、性能がコアだけでなくシステム全体のパフォーマンスに依存する部分が大きいからという事でもある。とは言え、マルチソケットのスケールアップは限界があるし、スケールアウトは必ずしも全てのアプリケーションに適している訳ではない事を考えると、コア数を増やしてそれで性能がリニアにあがるのなら、それだけで十分大きな効果があると考えるべきだろう。
-
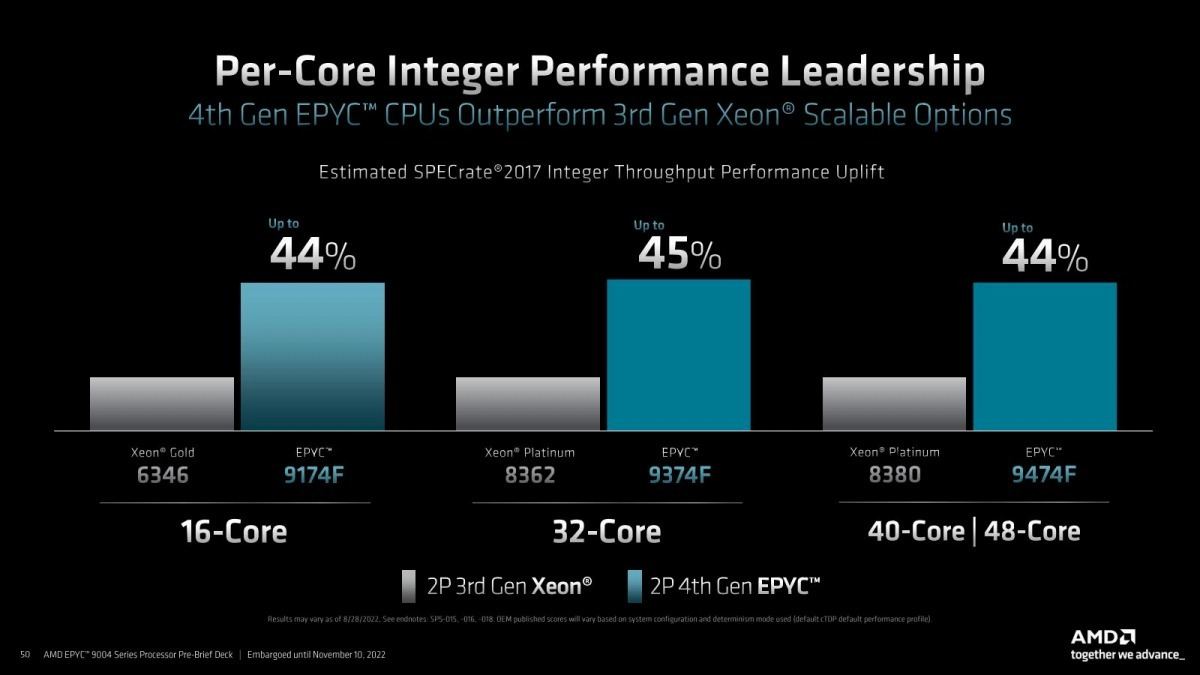
Photo11: 大体同等のコア数同士でのSPECrate_2017_int_baseでの比較。棒グラフの高さは気にせずに、数字で性能差を確認してほしい。

-
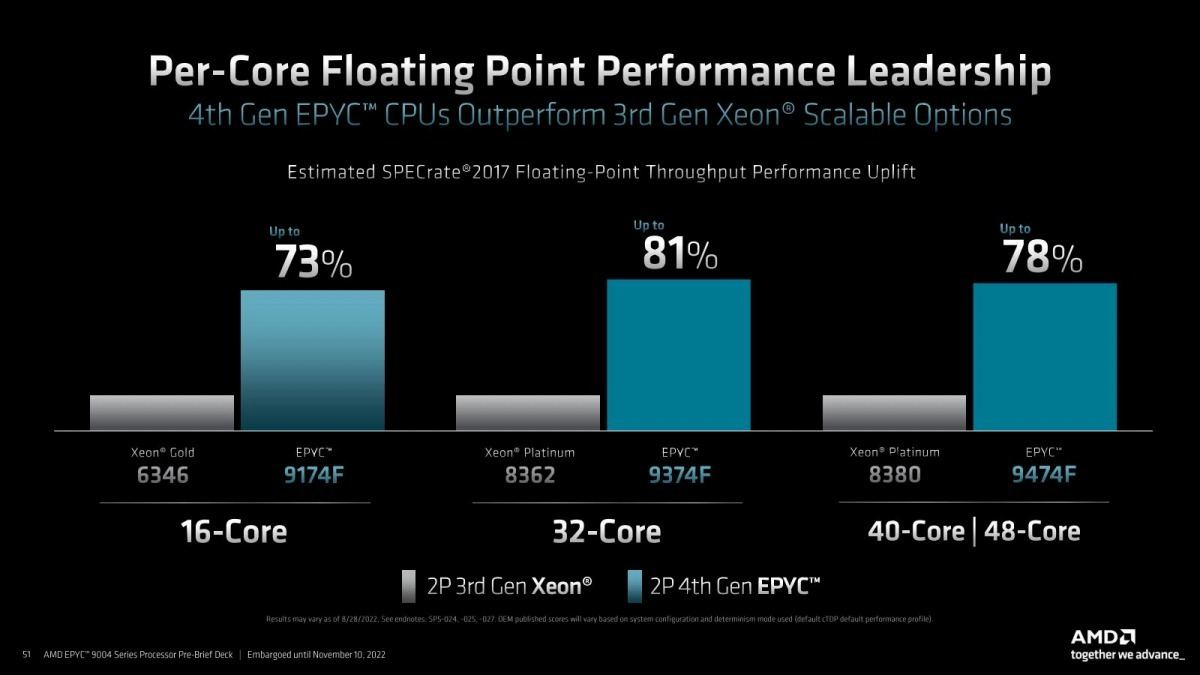
Photo12: こちらはSPECrate_2017_fp_baseでの比較。やけに性能差があるあたり、ひょっとしてAVX512は利用していないのだろうか?

-
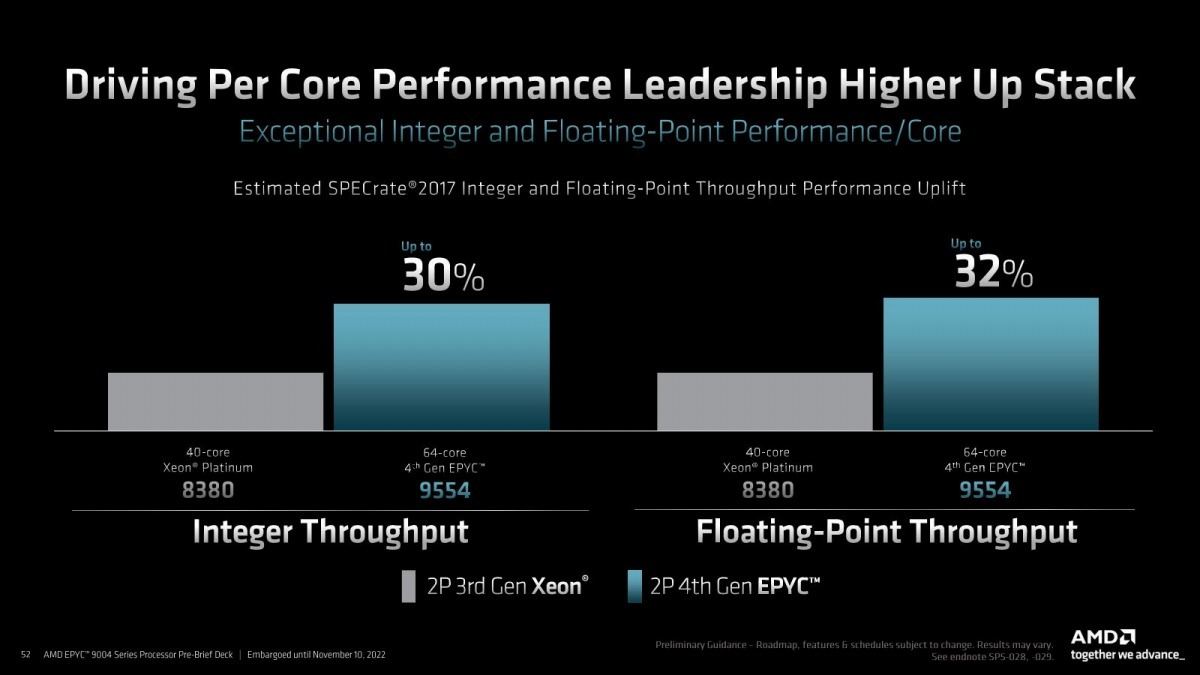
Photo13: 40core vs 64core。これはThroughputの方なので、全コア合計の性能ではなく1コアあたりの性能の比較となる。当然64coreのEPYC 9554の方が条件的に厳しいが、それでも30%前後性能が向上する、という説明。

-
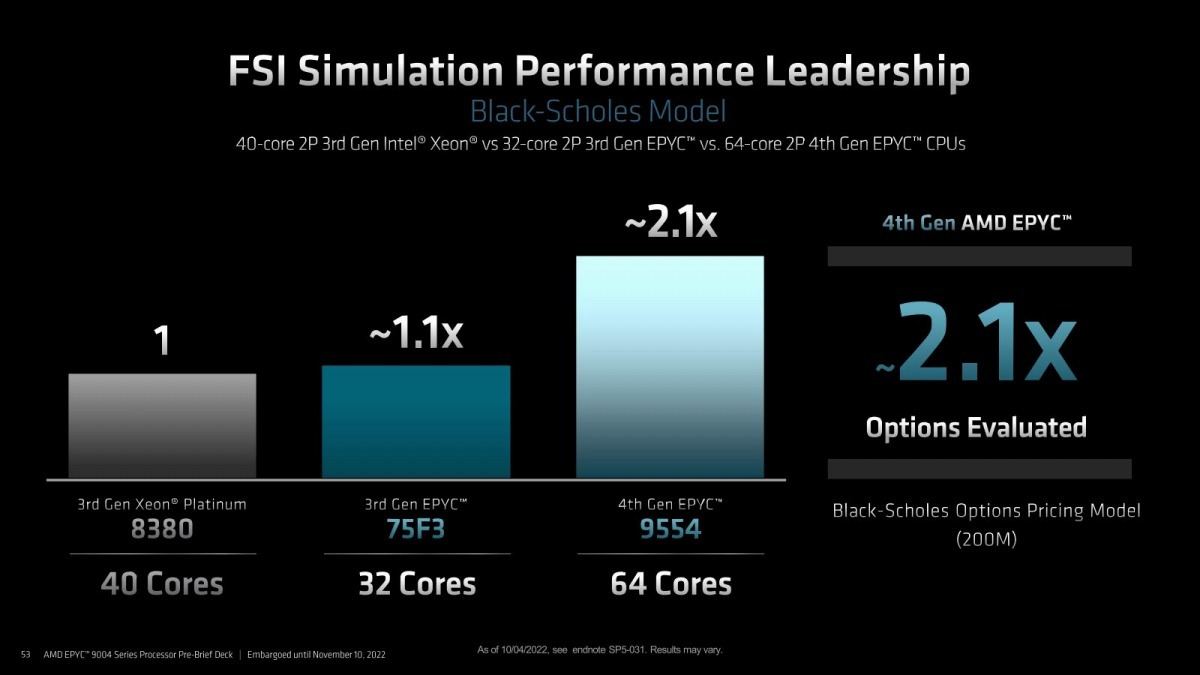
Photo14: ここからはアプリケーションに近いベンチマーク。まずはBlack-Scholesを利用したOptionの計算。EPYC 75F3と比較してもEPYC 9554は倍近い性能を叩き出す。

-
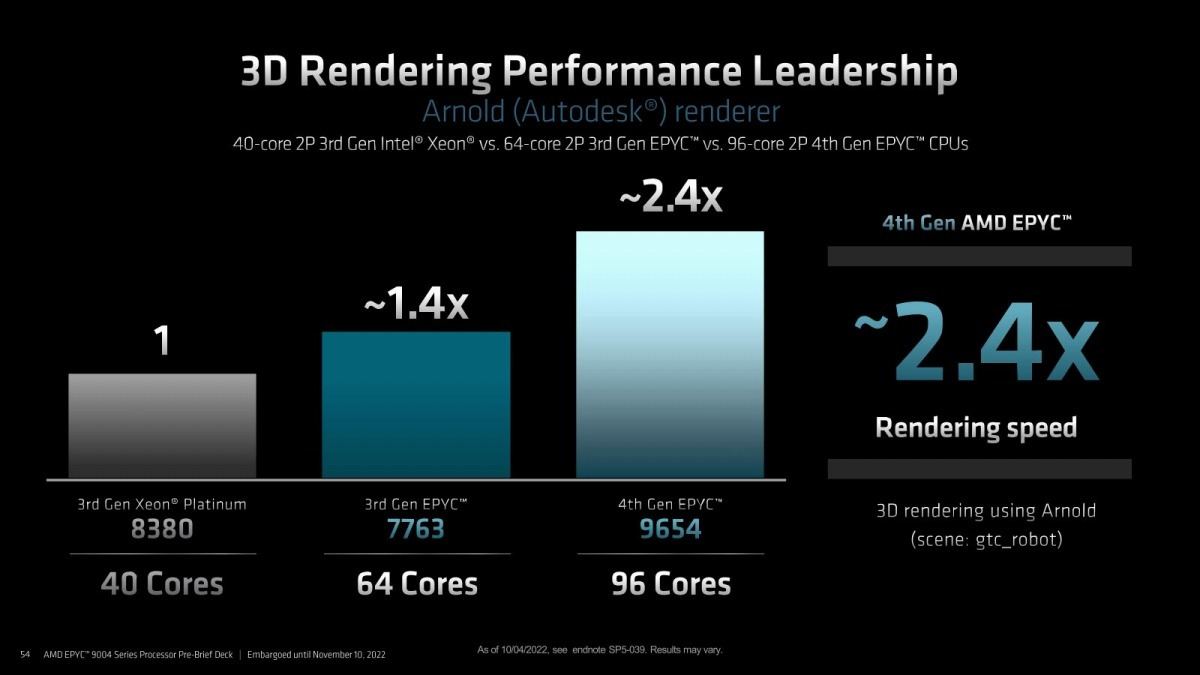
Photo15: AutodeskのArnold rendererでの性能比較。まぁXeon Platinum 8380を比較するのは可哀そうだと思う。

-
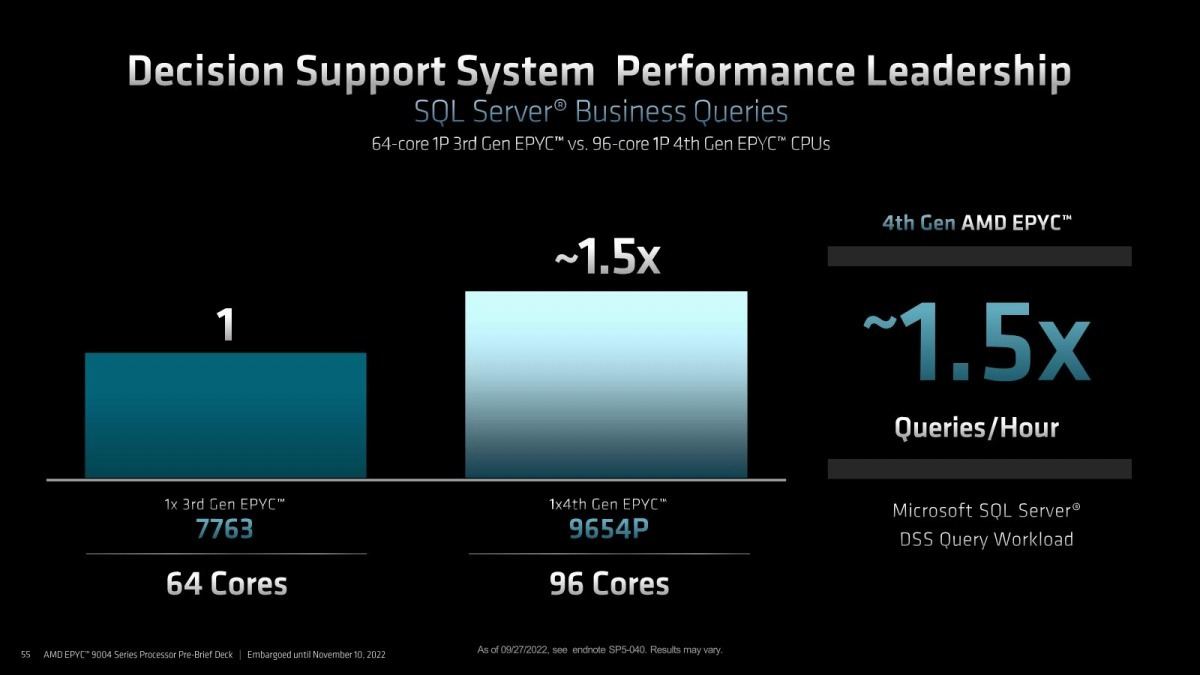
Photo16: SQL Serverでの比較。こちらはコア数が効くのでEPYC 7763 vs EPYC 9654Pで比べている。ただ1.5倍ということは単にコア数でスケールしている様にも見える。

-
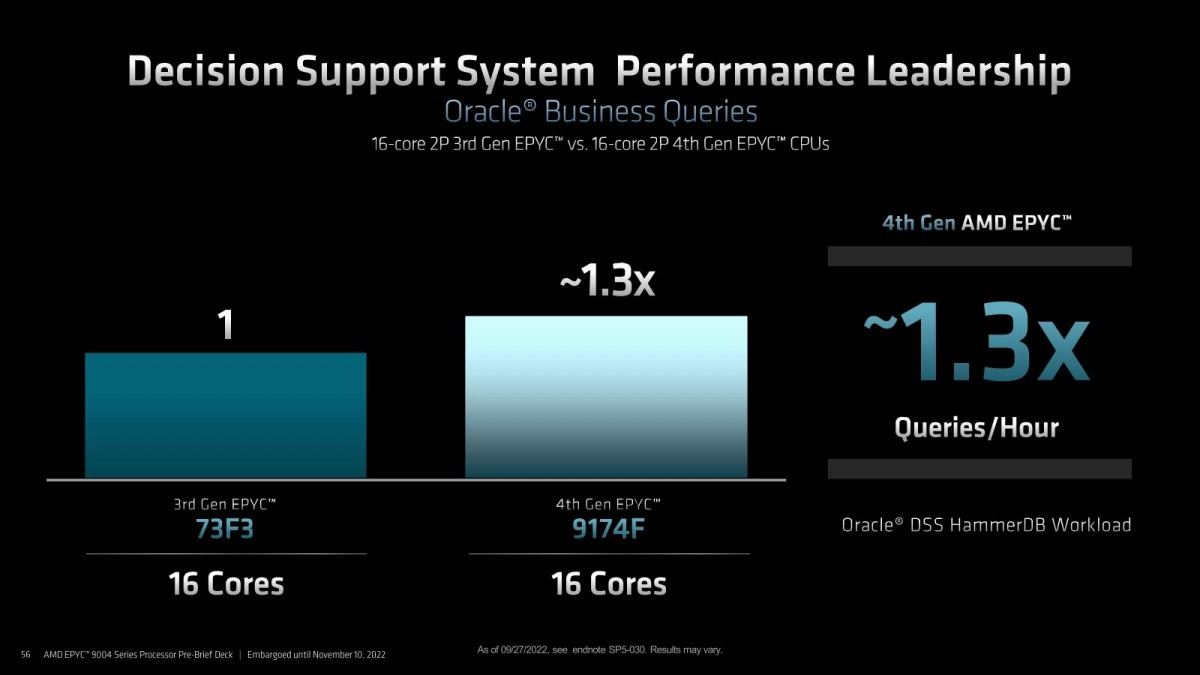
Photo17: 同じデータベースでも今度はOracle。EPYC 73F3(3.5/4.0GHz、240W)と9174F(4.1/4.4GHz、320W)で性能差が1.3倍というのは、消費電力の増分を考えると効率的にはほぼ同等ということになる。

-
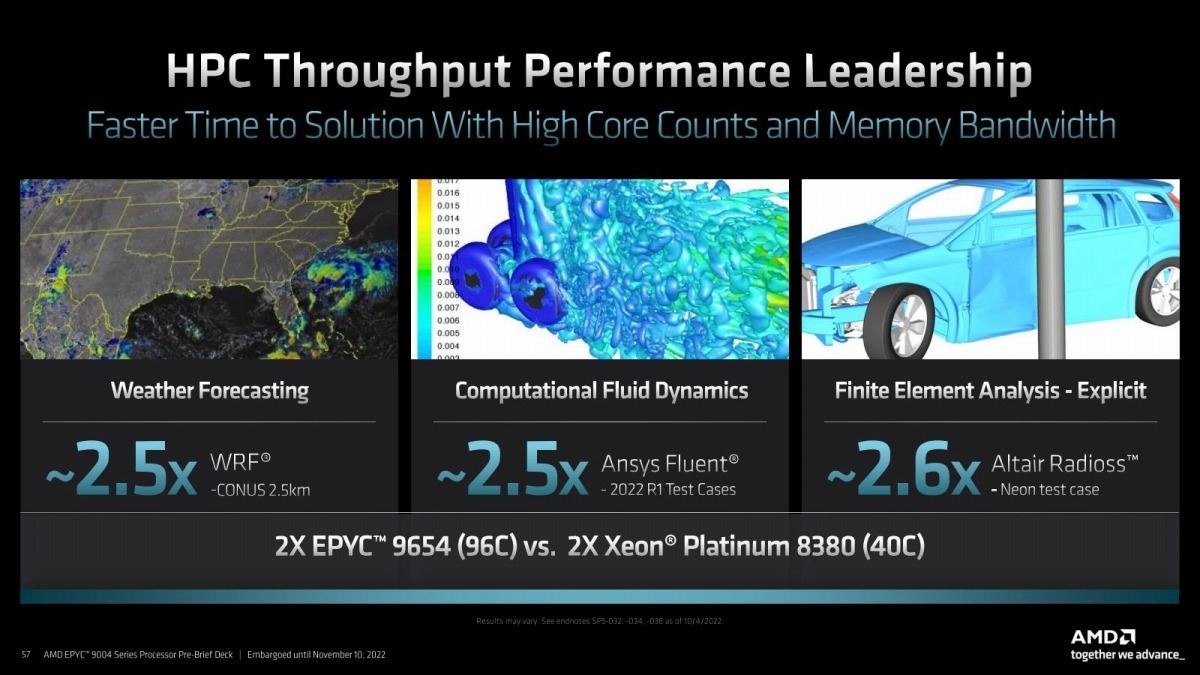
Photo18: HPC向けアプリケーションの比較。96core EPYCと40core Xeon Platinumだから、この程度の性能差はあって当然という気もする。

-
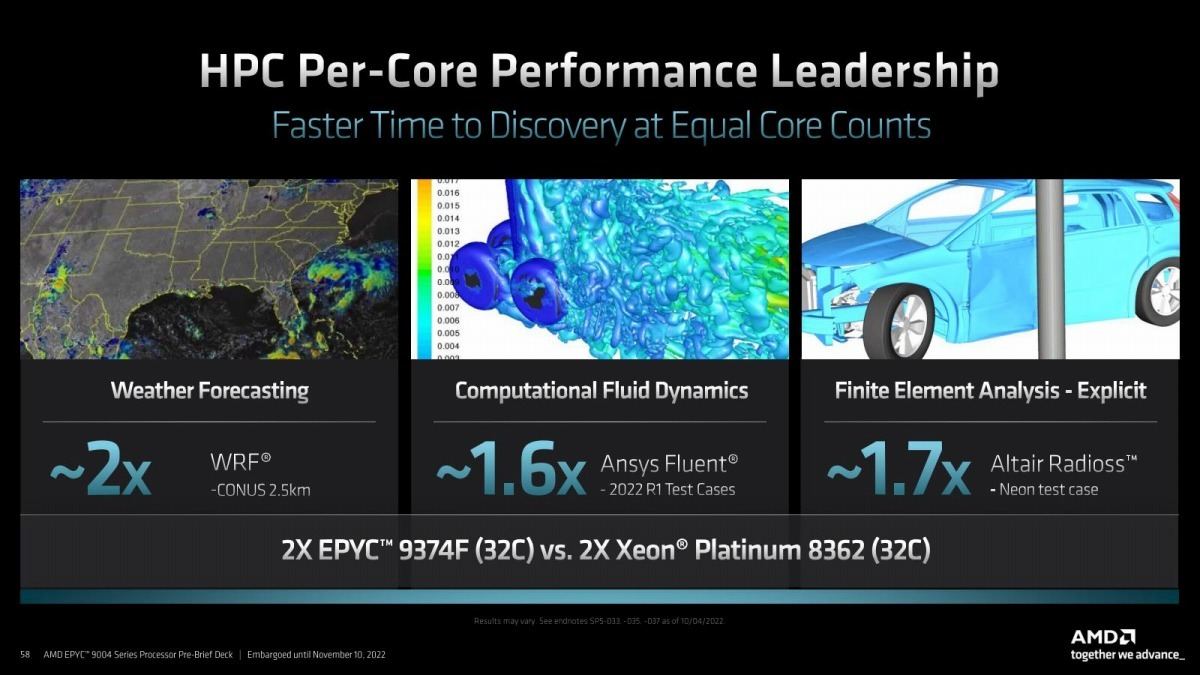
Photo19: こちらは32core同士での対決。1.6~2倍の高速化が可能としている。

この結果として、例えば同じ計算処理を行わせるならEPYCのTCOはほぼXeon Platinumの半分(Photo20)だし、何なら2 Socketサーバーを1 Socketサーバーに置き換えてもいける(Photo21)、というのがPhoto04に出て来た4本の柱の最後の要素に対するAMDの回答である。
-
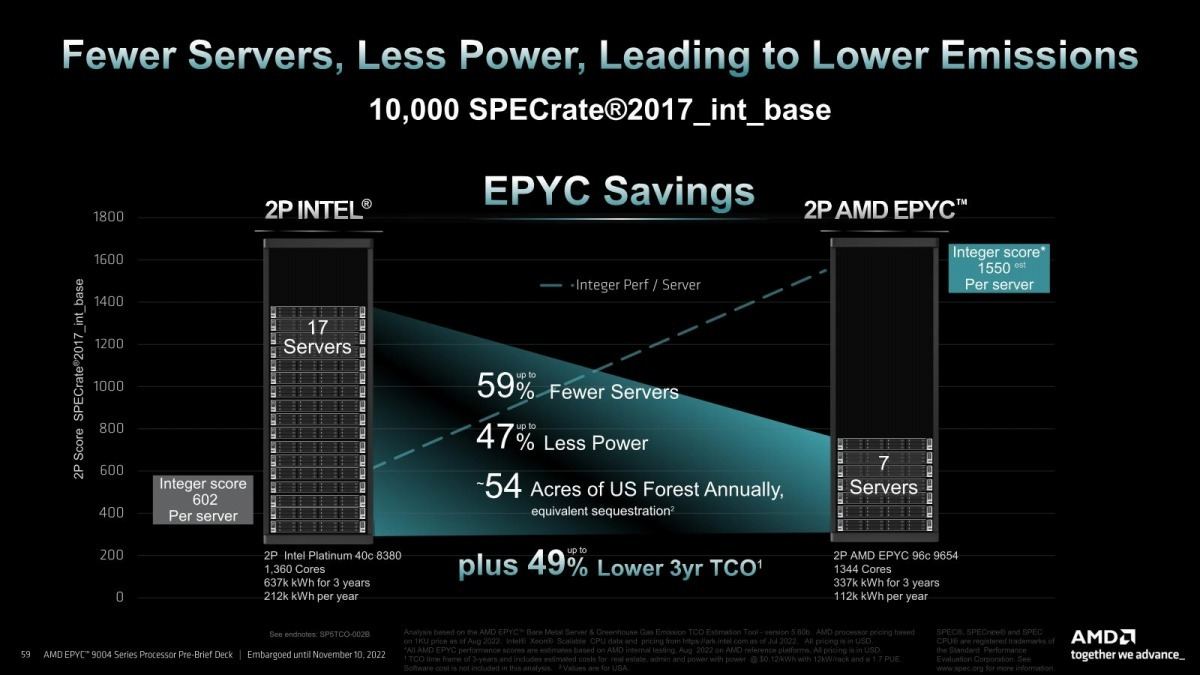
Photo20: 問題はこれをSPECrate2017intbaseで論じるのが妥当か? というあたりではある。

-

Photo21: Xeon 2PをEPYC 1Pで代替できる、という話は初代EPYCから出ていた話題であり、第4世代でも依然として通用するという主張。問題はSapphire Rapids相手にもこれが通用するかだが、何しろ製品が出てないので何とも言い難い。

さてここまでは製品構成とか性能を説明してきたわけだが、ここからもう少し内部構造についてご紹介したい。Genoaは基本的にはRaphaelことRyzen 7000シリーズと同じCCDに、EPYC専用のIODを組み合わせた形となる。「基本的に」というのは、CCDのダイそのものはRyzen 7000と全く同一であるが、Ryzen 7000では無効化されているオプションがGenoaでは有効化されるからだ。要するにAMD Proなどとして提供されてきたセキュリティとかRAS関係の機能である。一方でIODの方は完全に新設計である。
そのGenoaの構造の特徴はこんな感じ(Photo22)である。CCDは最大12個、各々が8コアなのでトータル96コアという形になる。このCCDとIOD、及びIOD同士の接続は、第3世代のInfinity Fabricが利用されている。まずCCDに関して言えば、最大12個と書いたがバリエーションとしては4個(Photo23)・8個(Photo24)・12個(Photo25)の3パターンが用意される。32コアの製品までは4個、48/64コアの製品は8個、84/96コアの製品には12個CCDが搭載されるという形だ。このInfinity FabricのLinkをはGMI3と称されているが、そのGMI3の特徴がこちら(Photo26)。最大1.8GHz駆動で36Gbpsまでのスケールが可能である。転送の消費電力は2pJ/bitを切っており、これは初代EPYCを下回っている(初代EPYCが大体2pJ/bitとされていた)。配線長はともかく転送速度を大幅に引き上げながら、転送時消費電力を2pJ/bitに留めているのは流石である。また新たに2組のLinkで同期して転送するGMI3-Wideが新たに追加され、Photo23で示すように4 CCD構成で利用できるようになっている。
-

Photo22: 青字が第2世代EPYCからの変更点。メモリチャネルが12になったので、最大搭載メモリ量は遂に12TBに。

-
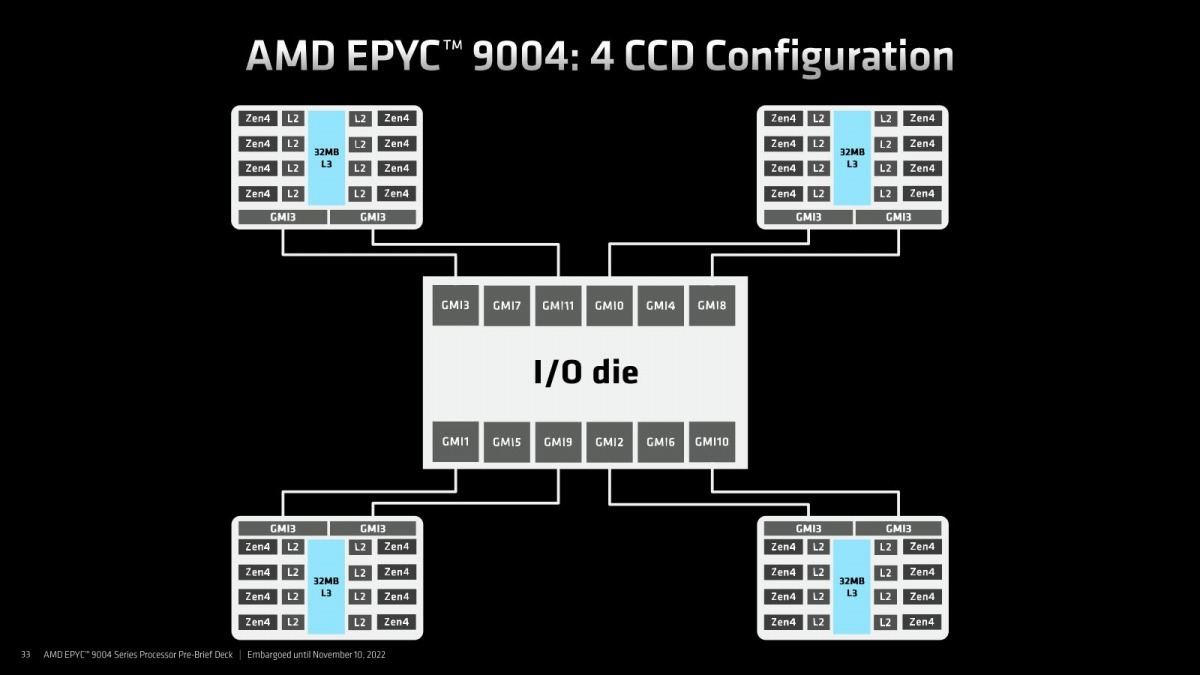
Photo23: 各々のCCDには2つのInfinity FabricのI/Fがあり、4ダイ構成では各々2本のInfinity FabricでIODと接続する構成になる。

-
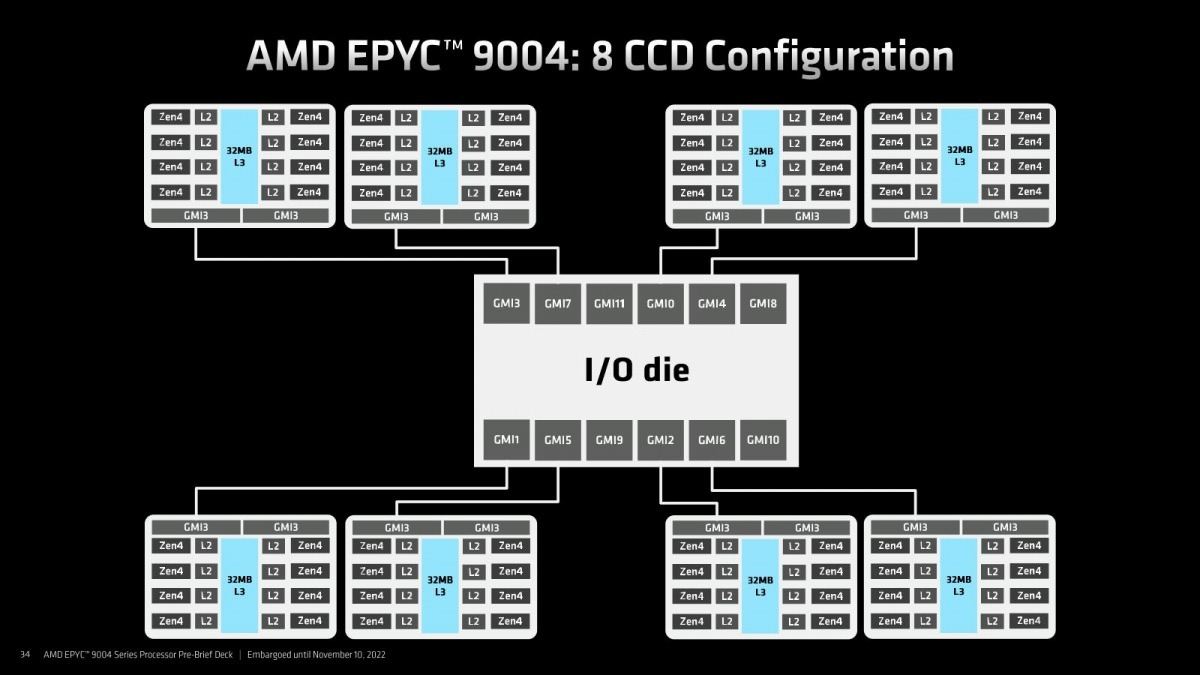
Photo24: こちらは各CCDとIODは1本のInfinity Fabricで接続される。IODの側は4本分のI/Fを余らせている格好。

-
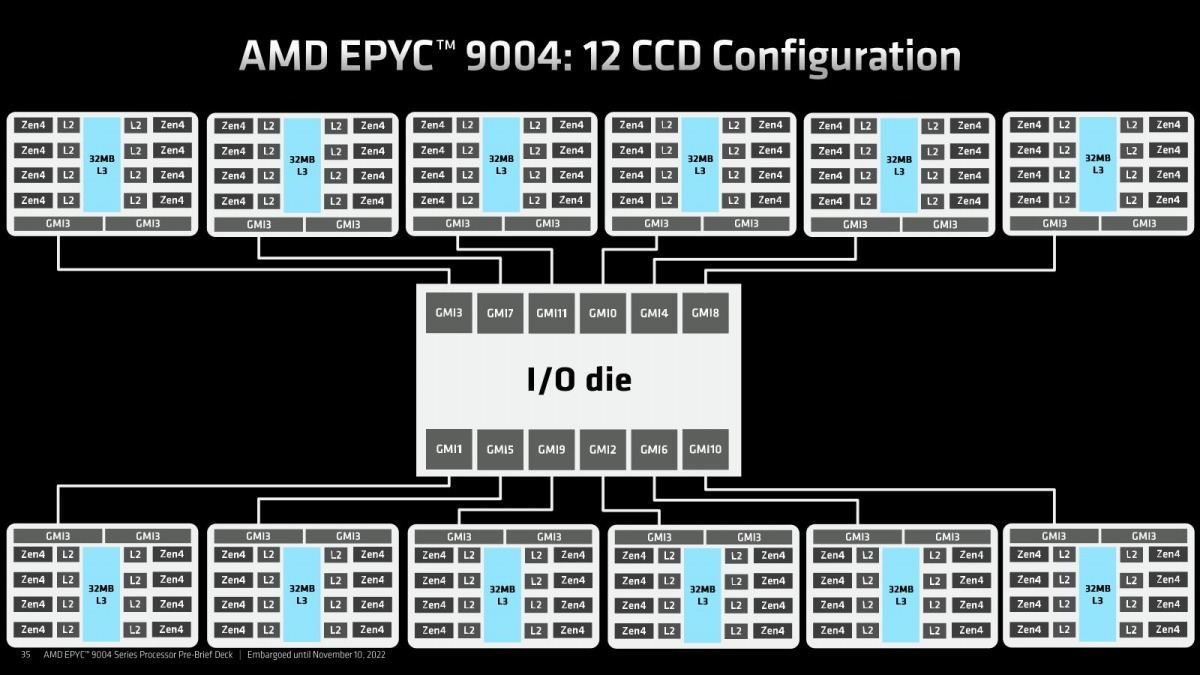
Photo25: フル構成。しかしこうなると、BergamoはIODも変更になるのだろうか?

-

Photo26: IODの構成。どうせならもう少しIODの内部接続用GMI3のポートを増やしても良かった気がするのだが(Bergamoとの絡みで)。ProbeのThroughputの高速化は、単にLink速度の高速化だけで実現できた訳ではなさそうである。

そのGMI3を利用しての構成だが、EPYC 9004では従来同様2 Socketと1 Socketの構成が選べる様になっている。で、PCI ExpressとInfinity Fabric(というかGMI)は同じポートを利用する格好になっているのだが、従来のプラットフォームとの違いの一つは2 SocketにおけるGMIの接続を3 Linkと4 Linkで選べる点である(Photo27)。4 Linkはオプション扱いで、普通は3 LinkにPCIe x160を外部接続に出す格好になるのが一般的らしい。
-
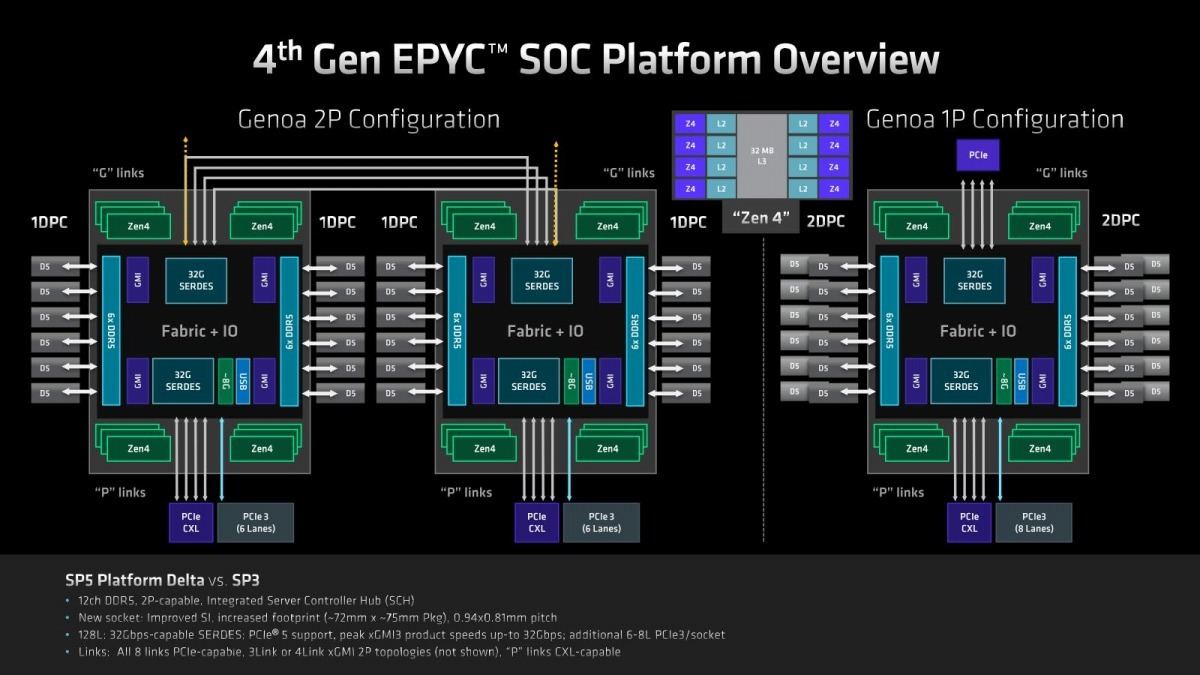
Photo27: 1本のGMI3 LinkはPCIe Gen5 x16に相当するので、GMI3がx3だとそれだけ外部接続用のPCIeを多く利用できる事になる。後はマザーボードベンダーやシステムベンダーが、PCIeを増やすのと2 Socket間のスループットを引き上げるののどちらが好ましいか、をターゲットに合わせて勘案する格好になる。

ちなみにPhoto28に出て来た32G SerDesだが、片方はxGMI+PCIe、もう片方はxGMI+PCIe+CXL+SATAでポートを共有する格好になる(Photo29)。Socketあたりの合計レーン数は136で、2 Socket構成の場合はこのうち3×16 or 4×16をSocket同士の接続(GMI3)に利用するので、トータルでは128ないし160 LaneがPCIe x16として利用できる計算となる。
-
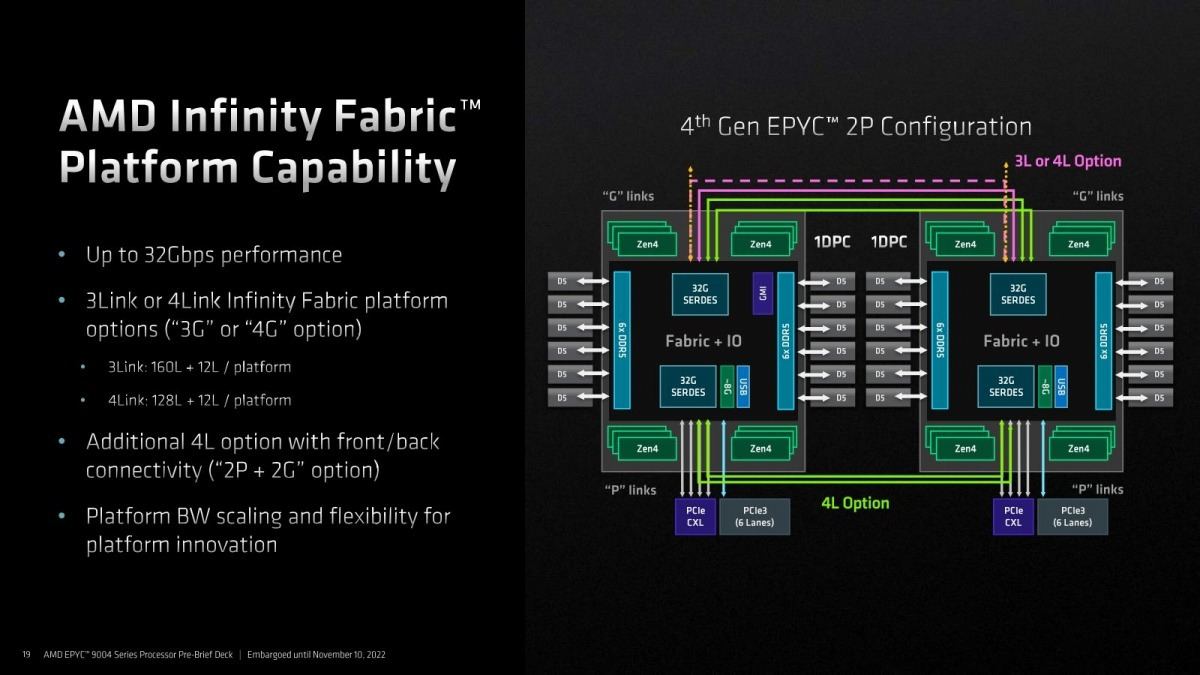
Photo28: GMI3 4Link構成の場合、片方の32G SerDesに4Linkまとめて繋ぐのと、2つのSerDesの両方で2Linkづつ繋ぐ、2種類の構成が許されるらしい。この辺はPCIe/CXLをどの程度外部に用意するか次第の模様。

-

Photo29: SATAのニーズは大分薄れてきたが、高速なEthernet接続のためのxGMIやNVMeストレージ接続用のPCIeや外部アクセラレータ/拡張メモリ接続のためのCXLのニーズはむしろ高まっており、これでも足りるのか? という感じである。

あとIODの新機能として説明されたものに、Advanced VIC(Virtual Interrupt Controller)がある。要は仮想化環境でより割り込みの処理を高速化できるようにした、というもので、90%以上の効率を実現したとしている(Photo30)。
-

Photo30: Out of Boxに拘るのは、ちゃんと最適化すると割り込み処理が遅くてもそれなりに性能が出るからで、デフォルト(MTU=1500)パラメータで200Gbpsの限界に近い速度で通信が出来る(それもIOMMUの有効無効に係わらず)あたりでその性能の高さが見える。

次にメモリについて。第3世代EPYCではDDR4×8chだったメモリは、第4世代ではDDR5×12chと大幅に強化された(Photo31)。ピークスループットは460GB/secで、通常のDDR5としてはかなりのものである。
-

Photo31: 速度的には、少なくとも現時点ではDDR5-4800が上限である。コンシューマ向けはともかく、サーバー向けの、それもRDIMMとかLRDIMMの場合は、現状これ以上の速度の製品が存在しない(より高速な製品の検証は一部で始まっているらしい)から、まぁ妥当な制限と言える。

ところでちょっとPhoto27に戻るのだが、第4世代EPYCの場合
- 1 Socket:最大2 DIMM/ch
- 2 Socket:最大1 DIMM/ch
という構成がデフォルトになっている。勿論技術的には2 Socketでも2 DIMM/chの構成は可能だが、2 DIMM/chにすると速度はDDR5-4800を下回る事になる。これはRaphaelことRyzen 7000シリーズも同じで、1 DIMM/chだと最大DDR5-5200まで可能なのが、2 DIMM/chだとDDR5-3600まで速度が落ちる(というか落とさないと動作保証がなされない)。現時点でEPYC 9004シリーズを2 DIMM/ch構成で利用した場合の最大速度は発表されていないが、DDR5-3600かそれ以下になるだろう。これもあって、1 Socketでは2 DIMM/ch構成を許す(別に推奨している訳ではない)が、2 Socketでは最初からDIMM Slotを1本/chにするのが標準的なデザインになっている。まぁこの場合でも1 Socketあたり6TB、2 Socketで12TBまで容量を確保できるから、問題ないという判断らしい。
このEPYC 9004シリーズのメモリコントローラであるが、従来よりも帯域が広い(まぁこれはch数の増加と速度の増加の両方が効いている)事に加え、特に2 Rankのメモリを利用した場合の性能低下を低く抑える事やLatencyを最小限に抑えることなど、多くの性能向上の策が取られているとする(Photo32)。またNUMAノードに合わせて物理的にメモリコントローラをパーティショニングする事も可能になった(Photo33)。あとこれはメモリ(というかIOD)なのかCCDなのか微妙なところだが、新たにAES-256でのメモリ暗号化にも対応した(従来はAES-128)。これによるペナルティ(Latency増加)は数%のオーダー、との事だった。
-

Photo32: DRAMアクセスのトータルのLatencyがDDR4で105ns、DDR5で118nsだから、これは十分高速と言えよう。

-

Photo33: NPS(Node Per Socket)1はSocket全体で1つのNUMAノードの場合。NPS2は2 NUMAノード、NPS4は4 NUMAノードの場合である。

次にCXL周りについて。EPYC 9004シリーズではCXL 1.1+に対応した(Photo34)。CXL 1.1"+"とは何ぞや? という話だが、CXL 1.1の全機能に加え、CXL 2.0で定義されたType 3(Memory Expansion)の機能も先行して実装を行ったという話である。CXL 2.0の全機能な訳ではないので、例えばCXL Switchなどには未対応だが、既にいくつかのベンダーから出荷が始まっているCXL Memory Moduleは利用可能ということになる。実際デモではMicronのCXL 2.0 Memory Moduleを装着し、Streamを実施して正しく動作していることが示された。Sapphire Rapidsを差し置いて、Genoaが最初のCXL Memoryのプラットフォームになりそうという予測が現実のものになってしまった形だ。
-

Photo34: デモの内容は原稿執筆時点では未公開だが、そのうち公開されるのではないかと思う。

ところで先ほどBergamoというかZen 4cについて少し言及した。現状発表されているのは、昨年のAMD Accelerated Data Center Premiereの中のこのスライド(Photo35,36)が全てなのだが、このBergamoのヒントが今回事前説明の中で紹介された。Photo37はZen 3とZen 4の違いを紹介したものだが、Zen 4cは「L3キャッシュ以外、全くZen 4と一緒」という話であった。要するにZen 4のCCDの32MBのL3キャッシュを削り(どの位削るか、はまだ不明)、その分コアを増やした格好になる。ただCCXの構造を変えるとは思えないので、1CCDあたり8コアという構成そのものは変わらず、
- 1ダイあたり2CCX、16コアとし、これを8ダイ並べて128コアとする。IODはGenoaと共通。
- 1ダイあたり1CCX、8コアのままでダイサイズだけ縮小する。これを16個並べて128コアとする。ただIODはGenoaのものは最大12ダイまでのサポートなので、Bergamo用の新しいIODを用意する。
のどちらかになると思われる。可能性として高いのは前者の方である。先にPhoto25とか26の脚注でごちゃごちゃ言っていたのは、仮にIODが16ポートあれば、後者の構成も可能だからだ。まぁ配線を考えると、8ダイの公算の方が高そうに思える。
実際にはBergamoはL3を削るのみならず動作周波数も相当下げて、性能/消費電力比の向上を目指すと思われる。実際にどんな構成で登場するのか、ちょっと楽しみである。
-

Photo35: "Optimized for scale out"にちょっと騙された感もある。

-

Photo36: 128コアをどう割り振るかが謎。

-

Photo37: これそのものは、Ryzen 7000の発表の際のスライドと全く同一。









