
米国時間の11月3日に行われたRadeon RX 7000シリーズの速報はこちらでお届けしたが、もう少し深い内容の情報が解禁になったので、ご紹介して行きたいと思う。
Chiplet構造と5nm
先のレポートでも書いたが、Radeon RX 7000シリーズというかNavi 31はコンシューマ向けGPUとしては初のChiplet構成を取った製品である(Photo01)。あと細かい点であるが、これまでGPUのパッケージはほぼすべてが正方形だったが、Navi 31のパッケージは長方形になっている。実際、AMDの公開したCG(Photo02)でも、縦横比は1:1.158ほどになっている。
-

Photo01: 微妙にブレがあるのはご容赦を。一応縦横比はかなり正確になる様に補正した。

-

Photo02: まぁ長方形だから何か支障があるか? というとそういうことは無いのだが。

それはともかくとして、Chipletを利用した理由はいくつか存在する。まず1つ目がSiliconの利用率の向上である(Photo03)。Infinity Cacheを追い出したことで、GCDのレイアウトが随分効率的になった、としている。
-

Photo03: Vega 7に比べればマシだとは思うが、それでもNavi 21でも結構無駄があったらしい。

2つ目の理由は、プロセス微細化と密度の向上が連携しなくなってきたことだ。Photo04の左が判りやすいが、元々アナログ回路に関しては、それを28nm→16nmに微細化しても回路の高密度化は殆ど期待できず、ほぼそこから横ばいになっている。で、SRAMに関しては7nmあたりまでは微細化に伴ってエリアの縮小が期待できたが、7nmより微細化してももはやエリアの縮小(というか、高密度化)が期待できなくなってきた。その一方で、微細化によるコストは確実に上がっている。例えばTSMCの例で言えば、ウェハ1枚あたりの生産コストは概算値で10nmが$6,000、7nmが$10,000、5nmが$17,000と言われている。つまりSRAMを5nmで製造しても、エリアサイズは7nmと殆ど変わらず、コストだけ1.7倍に跳ね上がる計算だ。もうこの時点で、結構なエリアサイズを喰うInfinity Cacheを5nmで製造する合理性が皆無である。そこでInfinity Cacheと(PHYがアナログ回路なので、やはり物理的に面積を喰う)GDDR6のコントローラを別チップに追い出し、相対的にコストの安い6nmを使って製造。コア部は5nmにしつつ、高密度化を図った事で高密度化と高Yield、相対的に安い原価を実現した、という訳だ(Photo05)。
ちなみにMCDをN7ではなくN6にした理由については、既にN7は新規のデザインでは利用されなくなっており、N6を利用するのがリーズナブルだったとの事。またMCDではなくGCDをマルチチップにする事も検討したそうだが、配線があまりに多くなりすぎてしまって、少なくともこの世代では現実的では無いと判断したとの返答だった。
-

Photo04: これはあちこちで言われている話。CFET世代(1.Xnm~)になって、新しいSRAMの構造が実用化されると、また微細化は進むかもしれないが、GAA世代(~2nm)に関しては期待できなそう。

-
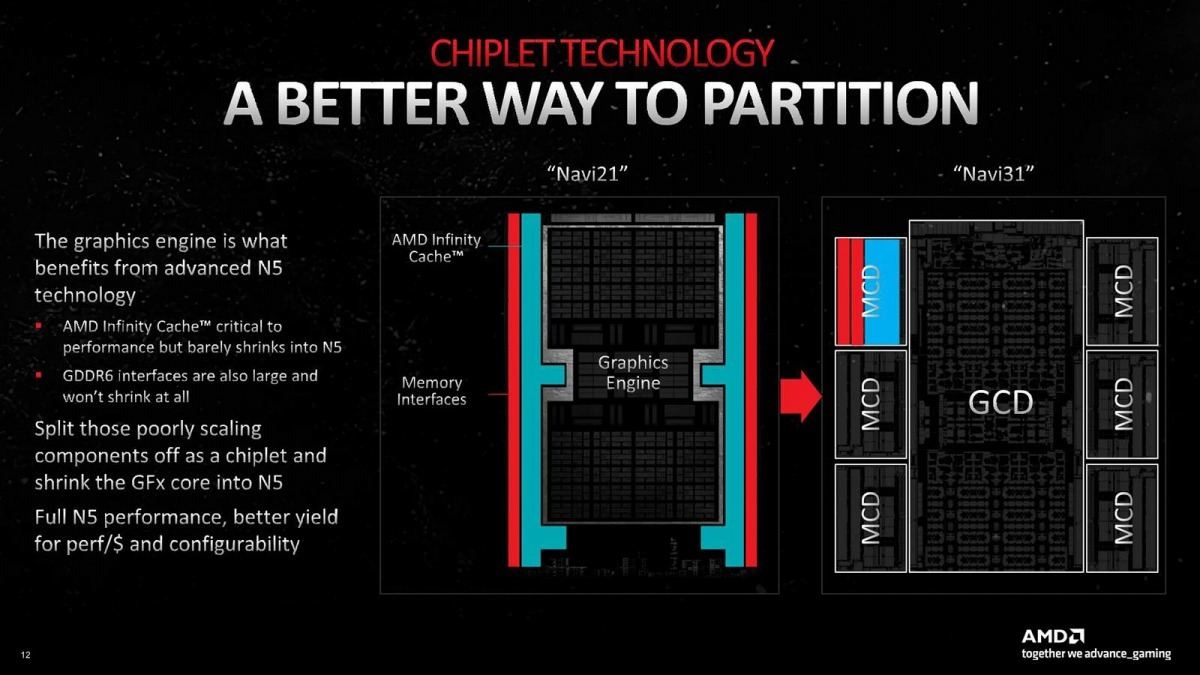
Photo05: Navi 21では、下の方に明らかに未使用のエリアが残っている。これを削減できただけでも効果があることになる。

次はその配線の話。EPYCとかRyzenの場合、CCDとIODの間の配線は数百本のオーダーであるが、Navi 21におけるCU(というかWGP)とInfinity Cacheの間の配線は数万本のオーダーで、これをどうやって配線するかが次の問題である(Photo06)。まぁそりゃそうだ、という話である。AMDはここにInfinity Link(正式にはInfinity Fanout Links)と呼ばれる新しいI/Fを導入した(Photo07)。Infinity Linkとは何か? というと、物理層は全く新しい、XSR(eXtra Short Range)に近い広帯域Interconnectだが、論理層はInfinity Fabricをそのまま流用したとしている。というか、Infinity Fabricの物理層を非常に広いパラレルバスに切り替えたのが、Infinity Linkと考えた方が正確だろうか。
-

Photo06: Genoa世代ではもう少しLinkは増えるが、それでも1,000本には達しない。

-
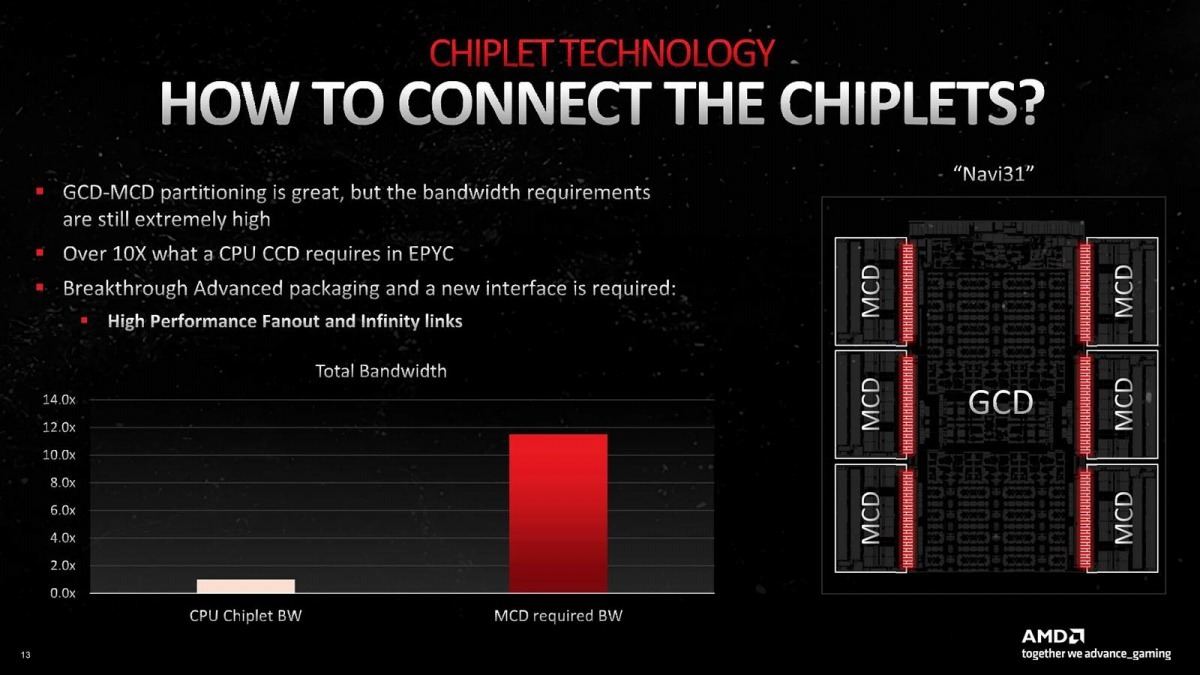
Photo07: この赤い部分がInfinity Linkである。

この配線で驚きなのは、Silicon Interposerを使わずに直接Organic Packageで配線を行った事だ(Photo08)。これに関してはSam Naffziger氏(SVP, Corporate Fellow and Product Technology Architect)曰く「Infinity Linkで必要とされる配線の密度は、Silicon Interposerで利用できる本数を上回った(!)」のだそうで、そこでむりやりOrganic Package上に数万本オーダーの配線を行ったのだそうだ。通常の配線(左側)と今回のInfinity Link(右側)を比較したのがこちら(Photo09)。Silicon Interposerを上回る配線密度を、従来型のOrganic Package上で実現してしまったわけだ。転送に要するエネルギーは従来の配線に比して0.2倍程度なのは、配線の短さもあってのことだろうが、結果として6つのMCD(と内部のL2、及びMCDの先のGDDR6)を全部合わせて5.3TB/secもの帯域を確保できたというのは十分に優秀というべきだろう。加えて、Infinity CacheへのアクセスのLatencyもNavi 21比で概ね10%削減出来たとしている(Photo11)。これによって、より高速動作が可能になったというのは性能向上に貢献する。
ただその反面、減ったのがInfinity Cacheの容量である。Navi 21では最大128MBのInfinity Cacheを搭載していたが、Navi 31では6MCD構成でも96MB(16MB per MCD)に留まる。この容量減少については、コストとか消費電力とのバーターだった、という話であった。もう少しMCDを大きくすれば容量を増やすのは不可能ではない(あるいは3D V-Cache的に縦積みする方法もある)が、その分コストが増える事になる。このあたりのバランスを狙ったのが現在の構成、ということらしい。
-

Photo08: 通常のOrganic Packageの配線の10倍の配線密度を実現したそうで。

-

Photo09: 「大体スケールはあってる」のだそうで、遥かに小さい面積に倍の配線が通っているのが判る。

-

Photo10: 配線長そのものは長くて1mm(Photo01で、MCDとGCDの間隔は1mm未満であることが見て取れる。これがPhoto08でいう所の"Die-to-die Fan out routing"の領域だから、配線は殆どが1mm未満と推定される)だから、相当電圧を下げても問題なかった&配線が短距離なので、それほどの駆動電力も必要なかったのが消費電力削減の大きな要因だろう。

-

Photo11: DRAM Accessに関してはI/Fがちょっと離れた場所に移動した半面、GDDR6そのものの速度向上もあってかほぼ同等に収まっている。

最後になったが、勿論TSMC N7からTSMC N5に移行した事の意味は大きい。もともとTSMCの説明では、最大80%ロジック密度が向上する他、最大15%の速度向上と30%の消費電力削減が実現できるとしていた。まずロジック。Navi 21は520平方mmのダイサイズで、80CUを実現していた。Infinity CacheもCUの一部と無理やり仮定して計算すると、エリアサイズは1CUあたり6.5平方mmとなる。一方Navi 31、GCD+MCD×6のダイサイズの合計は522平方mm。96CU構成だから1CUあたり5.44平方mmとなるが、Navi 21換算で言えば192CU相当になる事を考えると、実質的なエリアサイズはその半分の2.72平方mmほどになる。つまり2.4倍近い密度向上が実現できたわけだ。
これに加えて速度向上と省電力化がある(Photo12)。このスライドでは平均30%ほど動作周波数が引きあがった、としている。もっとも実装を見ると、Radeon RX 6950 XTがGame Clock 2.1GHz/Boost Clock 2.3GHzなのに対し、Radeon RX 7900 XTXはGame Clock 2.3GHz/Boost Clock 2.5GHzとなっており、どちらも1割程度の向上に留まっているのは、そこまで簡単に動作周波数を上げられる訳でもないという裏返しでもある。もっともCU数が倍以上になった事を考えると、動作周波数が変わらないだけでも儲けものであって、むしろ1割も上がったのだから凄いというべきかもしれない。
-
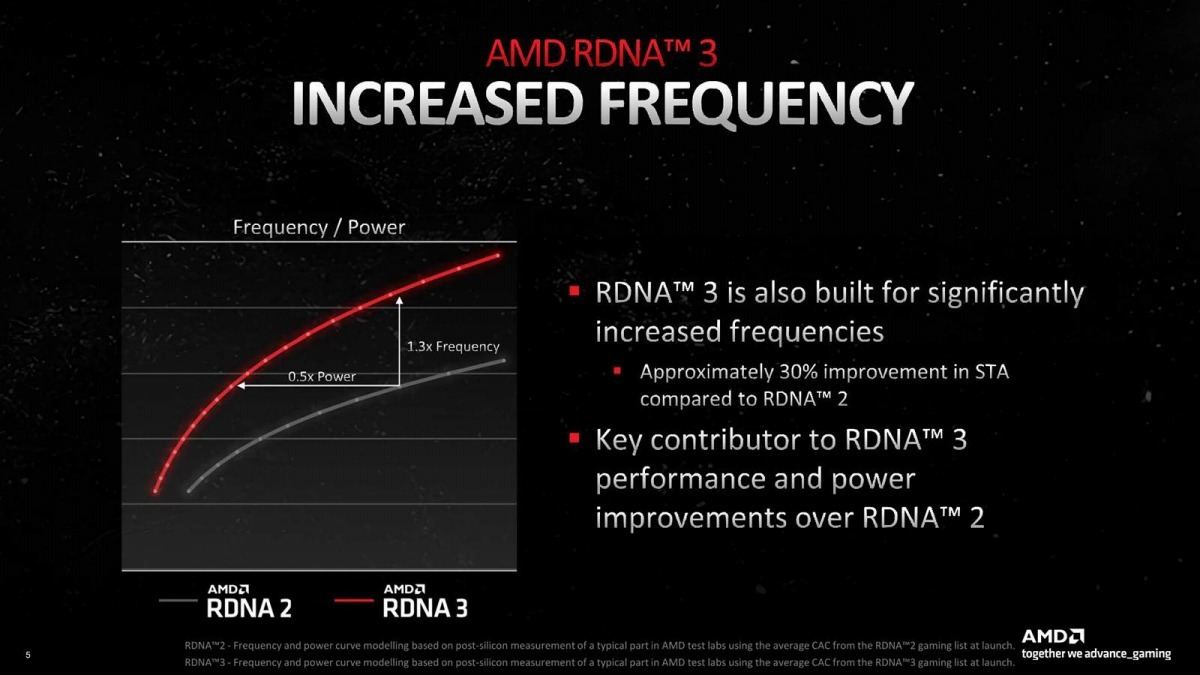
Photo12: 同じ動作周波数なら消費電力半分、あるいは同じ消費電力なら動作周波数1.3倍という話だが、当然これはどこで比較するかで変わってくる。まぁほぼ同じ消費電力で、1.3倍動作周波数を引き上げるという方向で利用するのは当然であろう。

RDNA 3の内部構造
RDNA 3では色々と内部構造の変更がある。具体的には
- CU構造の変更
- Matrix Accelerationの搭載
- Ray Tracing Engineの改良
3つが大きな項目である。ということで順に説明して行きたい。
Photo13がRDNA 3というかNavi 31全体の構造である。比較対象のためにRDNA 2(というかNavi 21)の構造を示したのがこちら(Photo14)。基本的な構成はあまり違わない。強いて言えば
- Shader Engineの数が6つに増えた一方、1つのShader Engineに属するCUの数は20→16に減った。
- L0/L1/L2の容量が大幅に増えた。
- GDDR I/Fが256bit→384bitになった。 という程度で、基本的には既存のRDNAの延長にある。
-

Photo13: 今後出てくるNavi 32とか33(あるのかな?)は、多分Shader Engineの数が4とか2になってるのだろうと想像される。

-

Photo14: 発表当時は恐ろしく高性能なGPUに見えたのだが、今ではメインストリーム向けにしか見えないのがちょっと怖い。

ただし細かいところは随分変わった。最大のものが個々のCUの演算性能倍増である(Photo15)。先のレポートにも書いたが、1 CUあたり32 SIMD×2だった構成を32 SIMD×4に増強した訳で、これだけでも倍の演算性能になる計算だ。そのCUだが、単に演算性能を増やしただけでなく、細かな改良も多く追加されており、17.4%の効率改善が実現したとしている(Photo16)。
-

Photo15: AI Matrix Acceleratorも新しく追加された内容である。

-
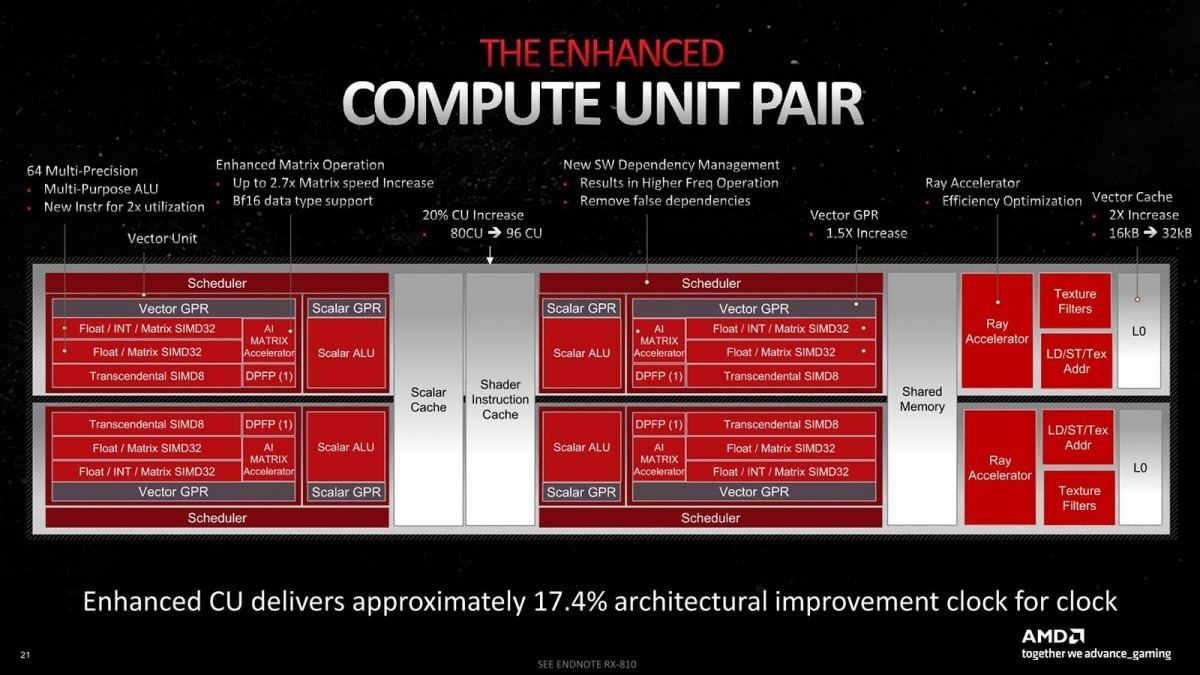
Photo16: L0/L1に関しては、SIMDユニットの増分以上に増やされており、これも性能改善の一因であろうと考えられる。またVector GPR(General Purpose Register)もSIMDエンジンあたり1.5倍になっているのも大きそうだ。

さてそのCU内のSIMD Engineであるが、これまでとちょっと違った話になっている。前回の記事でもちょっとだけ触れたが
RNDA 1 16way SIMD×4/CU=1 Wave64/cycle
RDNA 2 32way SIMD×2/CU=2 Wave32/cycle
RDNA 3 32way SIMD×4/CU=2 Wave64/cycle or 4 Wave32/cycle
という事になっている。元々初代RDNAでは内部のThreadの管理単位であるWaveは64Threadを束ねたWave 64を利用していた。このWave 64を4つのSIMD 16で処理することで、1cycleあたりWave 64を1個分処理していた訳だ。これがRDNA 2ではWaveが32 ThreadのWave 32になり、1つのWave 32を1つのSIMD 32で処理する形になった。SIMD 32ユニットは2つだから、1cycleあたり2つのWave 32を処理する形だ。筆者としては、この変更はGranularityを高める事で効率を上げたいのだろう、と考えたのだがRDNA 3では再びWave 64が復活している(Photo18)。ただ完全にWave 64に戻った訳ではなく、Wave 32の処理も可能になっている。なんでWave 64が再び復活したのか、は今一つ判らない(説明もなかった)のだが、Wave 32ではむしろ不効率になるシーンもあったため、どちらも選べる様にした、という辺りが正解に近いのかもしれない。
-

Photo17: ちなみにSIMD 32なのはALUだけで、Dot2/Dot4に関しては64wayだし、Wave 32/64に関わらない汎用ALUも64way動作ということを考えると、本来はSIMD 64で、特定モードのみこれを2×SIMD 32として扱える、と考えた方が良いのかもしれない。

-

Photo18: Dot4はINT4のみとなっている。

さてそのCUに今回追加されたのがDot2/Dot4の演算ユニットである。要するにドット積の演算で、AI処理ではしばしば利用される。Dot2/Dot4演算の定義はPhoto18に示す通りで、これにより畳み込み演算の高速化が図れる形だ。このDot2を、連続して実行できるのがWMMA Matrix Multiplication(Photo19)である。Dot2/Dot4そのものは1つの命令で64個までしかできないから、大量の畳み込み演算を行うためには頻繁に命令を出す必要がある。ところがWMMA Matrix Multiplicationを使うと、これを1回の命令発行で連続して32cycle行ってくれる。これにより、効率的に畳み込み演算の処理が行えると言う訳だ。
この仕組みそのものはNVIDIAのTensor Coreに非常に似ているし、もっと言えばIntelが間もなく投入するAMX(Advanced Matrix Extension)も原理そのものは同じである。
-

Photo19: 1cycleあたりだと64 Dot2/cycleであるが、連続して32cycle実施することができる。これにより、まとめて畳み込み演算を行えるわけだ。

ちなみにこのWMMA Matrix Multiplicationであるが、AI処理としてこれを使うためのフレームワークは、将来的にはRoCmでカバーされる(というか、XDNAでカバーされる)予定だが、現時点では独自フレームワークに限られるとの事。まぁ今はソフトウェアの側も、これを利用する予定のものが無い(IntelやNVIDIAと異なり、FSR 3を含むSuper SamplingにAIを使う予定はないとの事)ので、とりあえずはまずはハードウェアを実装、ついでこれを使うためのソフトウェアの充実を図る事でエコシステムパートナーに対応をお願いするという格好になるのだろう。
ちなみにWGPであるが、これは引き続き2CU/1WGPの関係を維持していることが確認できた。ところで、今回何故CU内部のSIMDを倍増したのか(CUの構成を変えずにCUの数を192にしても良かったのでは?)という質問を投げたところ、返答はバランスの問題という事だった。実際、そういう構成も検討はしたそうだが、トータルバランス及び従来のRDNAとの互換性を考えると、現状の構成が一番性能が出るという結果に落ち着いたそうだ。
高速化した演算部を支えるのがキャッシュサブシステムであるが、こちらも色々変更がある。一言で言えば広帯域化であり、容量の増加だけでなくL1/L2間は1.5倍、L2/InfinityCache間も2.25倍と大幅に帯域が増えている(Photo20)。
-

Photo20: プラス、GDDR6のバス幅拡張(256bit→384bit)も貢献している。ちなみにL1/L2のway数は変更なく、容量だけが増えている。

最後がRay Tracing Engine。Radeon RX 6000シリーズ、素の描画性能と言う意味ではNVIDIAのGeForce RTX 3000シリーズと良い勝負であったが、Ray Tracingに関してはまだ互角とは言い難いものだった。これを改良すべく、いくつかの変更が行われている。まずはCulling(Photo21)。要するに影面処理のRay Tracing版であるが、あるポリゴンの陰に隠れたポリゴンは(光源計算を行ったところで最終的に表示されないから)計算を省くという処理であるが、RDNA 2とやり方を変える事で、大幅にCullingに要する手間を省いたとする(Photo21)。また処理の仕方についても、従来のClosest Firstに加えてLargest First/Closest Midpointを追加、画面構成に応じて最適な処理が可能になったとする(Photo22)。他にも細かな変更が追加されており、トータルとしてRDNA 2比で1.8倍の処理性能が実現できた、とする(Photo23)。
-

Photo21: Cullingを早い段階で実施することで判断を高速化すると共に、Geometry Flagをハードウェアで管理できるようにすることで、必要になる命令数を15%程度節約できたとする。

-

Photo22: 全体(赤)と大きなオブジェクト(青)、小さなオブジェクト(緑)について、どの順番で計算を行うかを選べる事になる。

-

Photo23: レジスタとかキャッシュの大容量化も性能向上に貢献したそうだ。

製品ラインナップ
製品ラインナップそのものは以前のレポートで説明した通り、Radeon RX 7900 XTXとRadeon RX 7900 XTの2つが現在発表されている。で、製品の狙いであるがAMDとしてはGeForce RTX 4090グレードではなく、RTX 4080グレードが競合である、と位置付けている(Photo24)。
-

Photo24: 1 CUあたりのStream Processorの数は64個、という定義は変わらないのだが、RDNA 2比で言うならこの倍(つまりRX 7900 XTXは12288個、RX 7900 XTは10752個相当)になる。

実際のところ、TDP 450WクラスのGPUを利用できる環境は必ずしも多くない。Radeon RX 7900 XTXの355Wは「既存の環境からのアップグレードが容易」と言うAMDのメッセージも「いやそれはどうだろう?」と思わなくも無いのだが、450WのGeForce RTX 4090より容易であることそのものは間違いない。価格的にも$999(Radeon RX 7900 XTX)と$899(Radeon RX 7900 XT)で、丁度GeForce RTX 4080とRadeon RX 7900 XTが互角、そこから+$100で上位のRadeon RX 7900 XTXが購入できるという、割とリーズナブルな位置づけになっている。もっともベンチマークの方は、当然ながらまだGeForce RTX 4080の発売前ということで比較対象はRadeon RX 690 XTになる訳だが、追加で示されたものがこちら(Photo25,26)。基本的には4K Gaming向けという位置づけであり、Ray TracingもFSRと併用すると十分現実的という説明になっている。
-
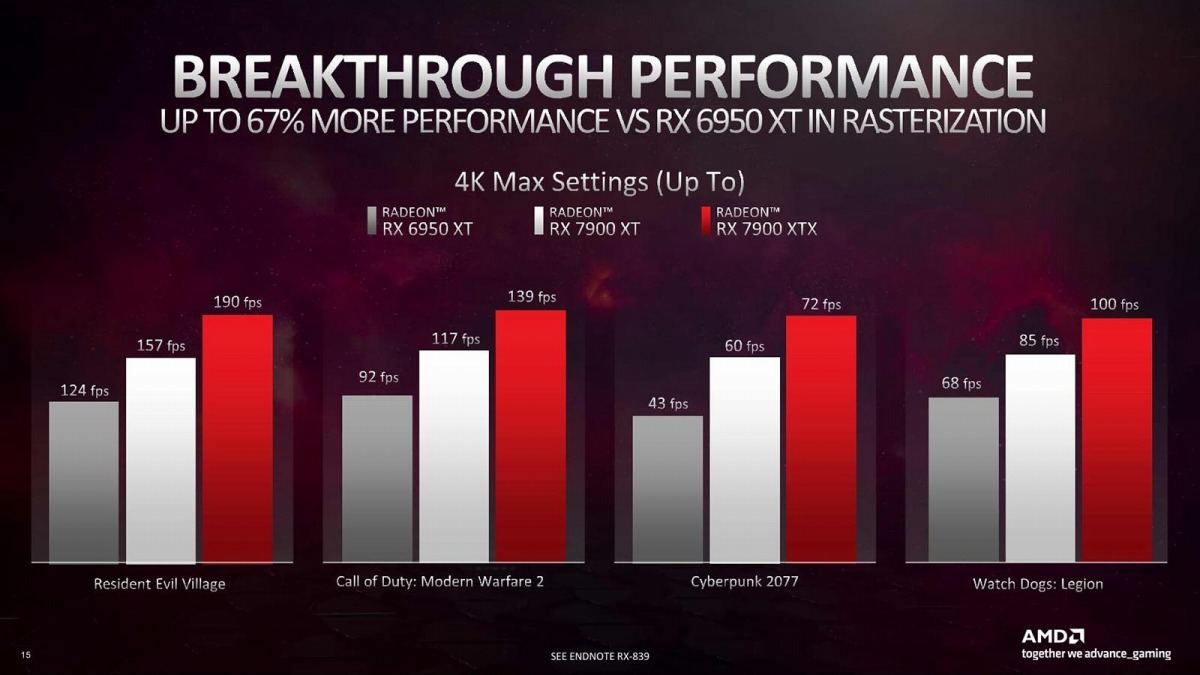
Photo25: 比較的重めのCyberpubk 2077で60~72fpsは見事。

-

Photo26: 逆に言えばRay TracingはFSR無しだとまだ厳しい、という言い方も出来る。80%高性能化といっても、元が低いからやはりまだ十分とは言えない気がする。

ちなみに内部構造のパートでは触れなかったが、出力部が大幅に強化され、12bit Colot(Photo27)とか4K 480Hz/8K 165Hzまでの出力(Photo28)も可能になったのも従来と異なる部分だ。8KでもFSRを併用する事でそれなりのフレームレートでの描画が出来る(Photo29)、とする。いやそんなに出せても対応するモニターが無いのでは?と突っ込みを入れたくなるが、AMDによればSamsungのOdyssey Neo G9がこれに対応するという話であった。
-

Photo27: REC2020(正式にはITU-R Recommendation BT.2020)に完全対応、というのは大きいといえば大きいのだが、業務用はともかくコンシューマ向けではちょっと持て余すような(プロの人には喜ばしいだろうが)。

-

Photo28: USB Type-C経由でDP Alt Modeを利用する事でDPの3画面出力も可能。逆に言えばHDMIまで併用しての4画面出力は不可能である(そもそも出力が3ポート分しかない)。

-

Photo29: Call of DutyはFSRを組み合わせると190fps出るそうだが、8Kは165fpsでクランプされる気がする。

-

Photo30: [現在発売中のもの](https://www.samsung.com/us/computing/monitors/gaming/49--odyssey-g95na-gaming-dqhd-led-monitor-ls49ag952nnxza/)とはスペックが異なるらしい(現状のOdyssey Neo G9は5120×1440pixel)。こちらは2023年のCESで発表予定との事。

-
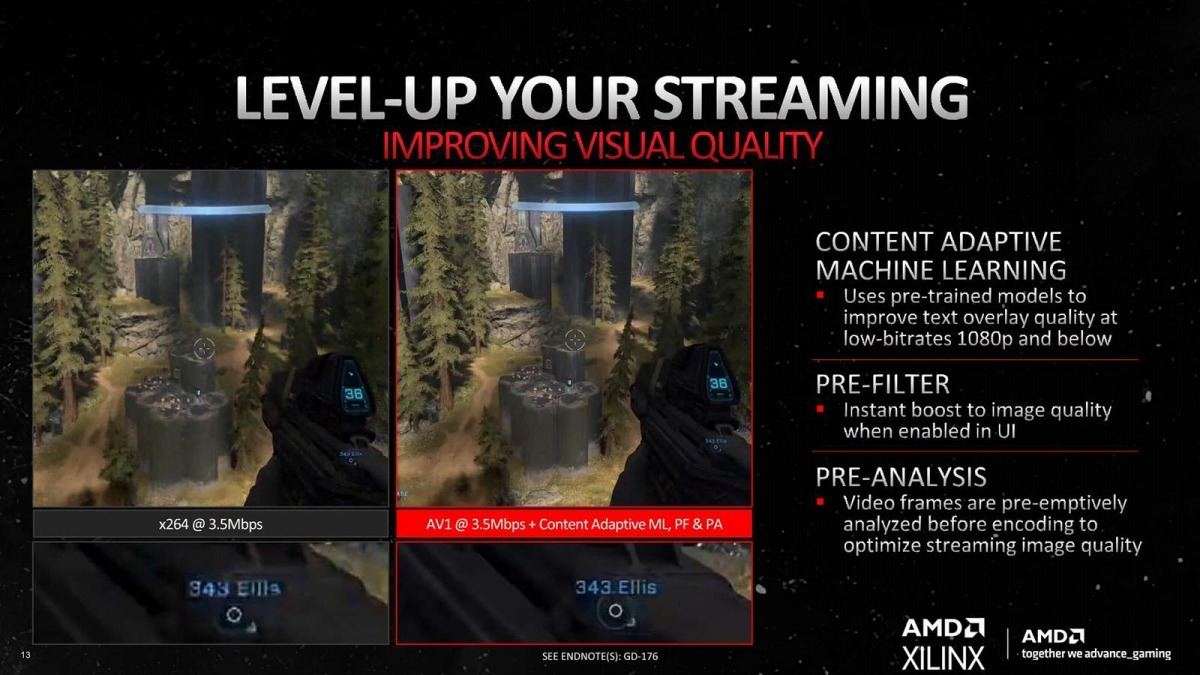
Photo31: 下段の数字の表現を見ると、大幅に画質が向上しているのが判る。

またMedia Engineの強化も大きな特徴である。説明ではH.264 vs AV1+Content Adaptive ML/Pre-Filter/Pre-Analysisの場合で、画質が大幅に改善したとしている。また、新しいSmart Access Videoを利用すると、エンコード速度を30%改善できるとしている(Photo32)。なので後はエンコーダソフトの対応が待たれるところ。恐らく発売日までには各社から対応するエンコーダソフトが出てくるとは思う(HandBrakeとFFmpegだけ、という可能性も無くはないが)。ちなみにAV1はともかくH.266(VVC:Versatile Video Coding)の対応はどう考えて居るか、は聞き忘れた(ライセンスの関係を考えると、サポートされない公算が高そうだが)。
-

Photo32: 多分Smart Access Memoryを応用した仕組みと思われるのだが、詳細は不明。

Software (HYPR-RXとFSR 2.2)
最後にソフトウェア関係について。まずHYPR-RXであるが、こちらは要するにFSR+Radeon BoostとRadeon Anti-Lagをまとめて有効化するオプションである(Photo33)。Radeon Settingsに目立つ形でHYPR-RXのボタンが追加され(Photo34)、これを有効にするだけでワンタッチで利用できるという訳だ。例えばDyingLight 2ではフレームレートが大幅に伸び、しかもLatencyが1/3近くまで削減できる、としている(Photo35)。
-

Photo33: 個別に設定を行う必要が無い(というか、ワンタッチで有効化できる)のがメリット。

-

Photo34: 恐らくショートカットキーなども設定され、簡単に利用できるようになるのだろうと想像される。

-

Photo35: ただDyingLight 2そのものが比較的軽いゲーム(Ray Tracing無しなら、Radeon RX 6600 XTでもFSR無しで90fps@Full HD以上が出る)なので、この数字だけ見てもメリットはちょっと感じにくいのだが。

次がFSR絡み。この11月に、AMDはFSR 2.2をリリース予定である(Photo36)。最初に対応するのはForza Horizon 5になるとの事(Photo37)。また近く3DMarkにFSR 2.2対応のFeature Testが追加される予定との事である。そして2023年には第3世代のFSRであるFSR 3がリリース予定となっている(Photo39)。それとDirectStorage 1.1にも近いうちに対応予定、という話であった(Photo40)。
-

Photo36: フォントが盛大に化けまくっているのはご愛敬。最近はDLSSとFSR、両対応のゲームが増えて来たのは事実。

-

Photo37: 11月8日リリース予定だから、この記事が掲載される頃には既に対応が終わっている「筈」である。

-

Photo38: あくまでもFeature Testなので、これで3DMarkのScoreが変わる事はなさそう。画面的にはSpeed Wayを利用する様に見える。

-

Photo39: Fluid Motionの組み合わせとされるが、具体的な話は現時点では一切なし。

-

Photo40: DirectStorage 1.1そのものは[11月7日から提供が開始された](https://devblogs.microsoft.com/directx/directstorage-1-1-now-available/)。

以上、やや駆け足であったがRDNA 3とNavi 31、Radeon RX 7000シリーズに関してのもう少し突っ込んだ説明である。あとは実際のベンチマーク結果を見るだけ、という感じだ。ただし価格の方は、米国価格はともかく国内ではちょっといいお値段になりそうで、そこをAMDがどこまで頑張れるか、発表を待ちたいところである。








