
Alder Lakeに続き、次はSapphire Rapidsについて。
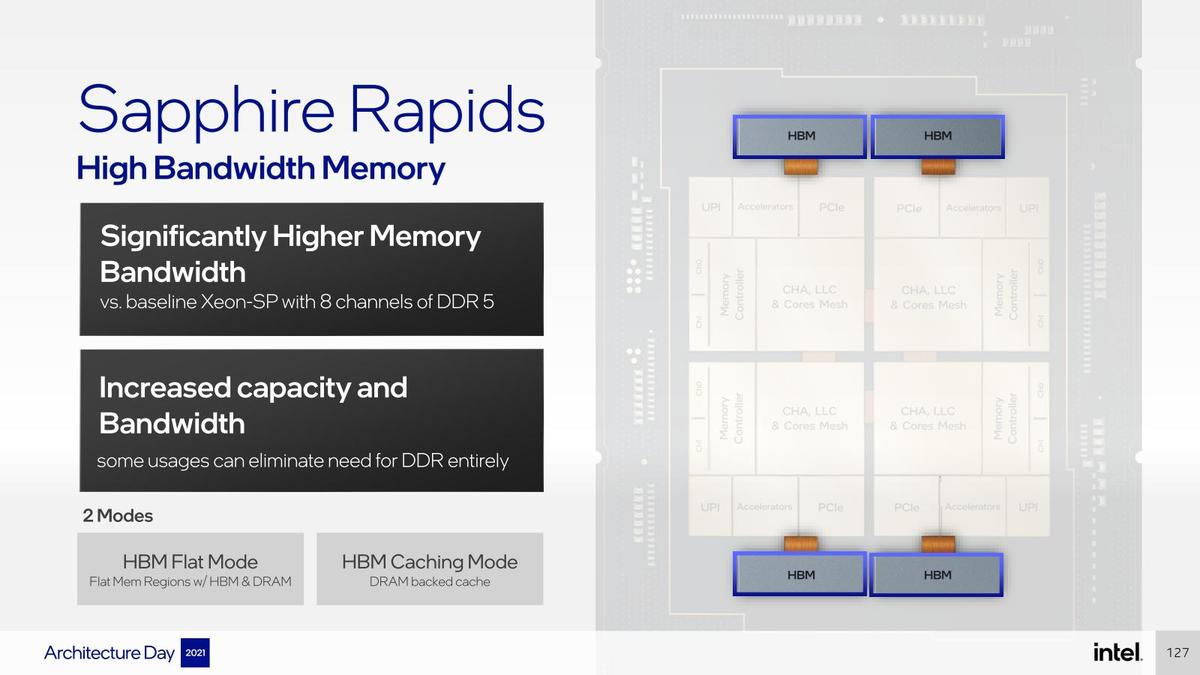
実はこちらも、HotChipsのSapphire RapidsのセッションそのものはArchitecture Dayと変わらないというか、スライドは殆ど変わらない程度である。一応新しく発表になった話としては、HBM併用時の2種類の動作モードが図入りになってすこし判りやすくなった(Photo01)事と、もう一つはI/O Virtualizationに絡む話(Photo02)である。
-
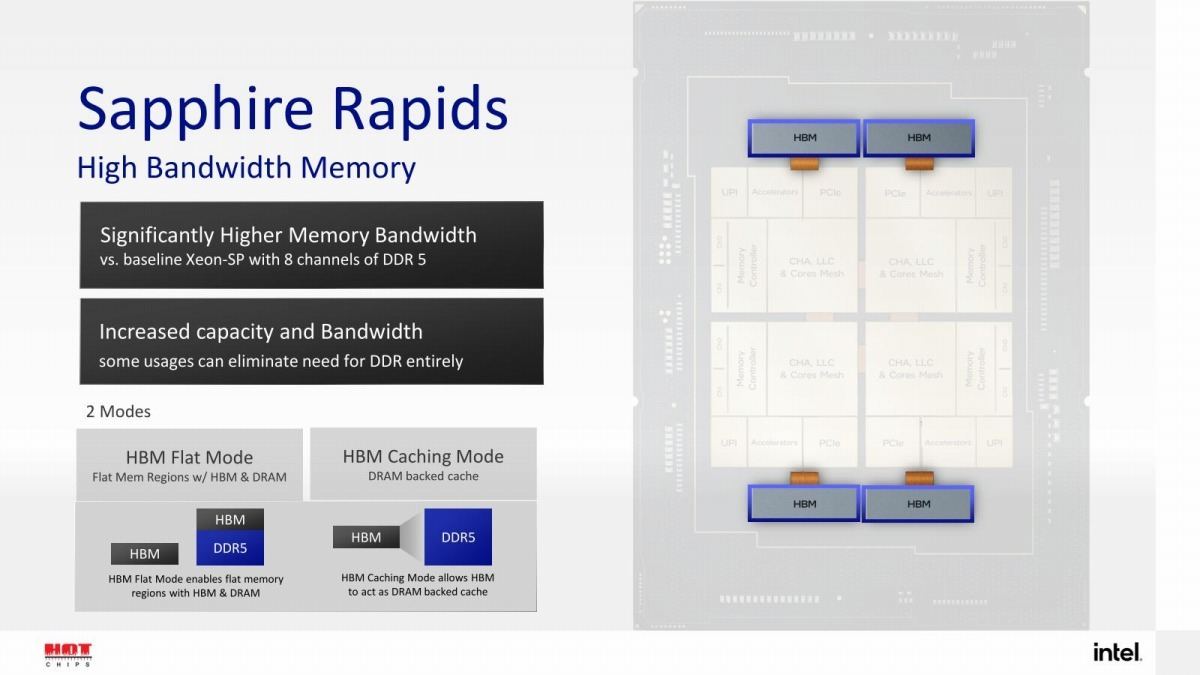
Photo01: Architecure Dayでのスライドはこちら。内容そのものは一緒。

-

Photo02: SR-IOVとS-IOVが混在して、非常に紛らわしいのが難点。もう少し違う名前は無かったのだろうか?

このうちSVM(Shared Virtual Memory)は以前から実装されている機能で、OpenCLなどでもサポートされている。Sapphire RapidsではCXL 1.1を搭載したので、CXLベースのデバイスとの間でもSVMが利用できるようになったのが大きな違いである。これに対して新機能と言えるものはS-IOV(Scalable IO Virtualization)である。もっともS-IOVそのものも以前から規格の策定はなされていた。2018年6月には"Intel Scalable I/O Virtualization Technical Specification 1.0"がリリースされ、2020年9月に1.1にRevision Upしている。
S-IOVの目的は、行ってみればSR-IOV(Single Root I/O Virtualization)をハードウェア的にアシストする事で、多数のVMからデバイスを利用できるようにするというもので、これを利用するためにシステムの中に仮想のデバイスエンドポイント(ADI:Assignable Device Interface)を作成、このADIを使ってVMからデバイスへの接続を管理するという仕組みが提供される。勿論これはホストとデバイス、更にVM側がそれに対応しないと意味が無い。そんなわけで仕様そのものは2018年からあった訳だが、ホスト側としてSapphire RapidsがこのS-IOVのサポートを実装した、という話である。
さて、肝心のSapphire Rapidsのセッションでの話はそんなわけで肩透かしであったのだが、質疑応答及びPackageのセッションで色々面白い話があった。まず質疑応答であるが、先の記事のPhoto50で"CLDEMOTEに関しては詳細は不明。これはHotChipsを待ちたい。"とキャプションに記した。このCLDEMOTEであるが、完全に失念していたのだが、CLDEMOTEを最初に実装したのは実はTremontであった。正式名称は"Cache Line Demote"で、この命令はオペランドで指定したアドレスを含むCache Lineを、プロセッサコアに近いキャッシュ(つまりL1 D-Cache or L2)から遠いキャッシュ(L2 or L3)に移動すべき、とプロセッサに「示唆する」(Hint to)命令である。強制的に排除する命令ではなく、次にプロセッサがL1 D-CacheなりL2の入れ替えを行う際に、真っ先にL2/L3にSwap outされるべき領域をプロセッサに指示する仕組みだ。
これがどんな役に立つかであるが、一つ例を挙げるとSapphire RapidsやAlder Lakeなどの世代で、L2/L3はExclusive Cacheの形で実装される。ということは、あるコアがメモリを書き換えた後、そのアドレスをCLDEMOTE命令でL3にWrite Backさせると、他のコアがそのアドレスを迅速に参照できることになる。これが無いと、別のコアがそのアドレスを参照しようとして、Cache Invalidということで強制的に書き換えたコアのL1 D-Cacheの内容をL3に書き戻させ、それから参照を行う形になるので、時間が掛かる。ところがCLDEMOTEを使うと、別のコアが参照しようとする「前に」書き戻しが行われるので、結果として別のコアの待ち時間が減る、という訳だ。ちなみにこのCLDEMOTE命令、Sapphire Rapidsでは有効化されているが、Alder LakeのP-Core/E-Coreでは無効化されているとの話であった。
さて、Sapphire Rapidsでびっくりする話が出てきたのは、初日に行われたTutorial Sessionの第二部である"Advanced Packaging"の中の"Case Study: Intel products built with 2.5D and 3D packaging"である。ここでEMIBの代表として登場したSapphire Rapidsのスライドがこちら(Photo03)であるが
- HBM無しのSapphire Rapids(SPR XCC)とHBM付きのSapphire Rapids(SPR HBM)では、そもそもパッケージサイズが異なる。
- HBM2Eは8 Stackのものが使われる
- EMIB CountがSPR XCCは10(!)、SPR HBMは14となる
という説明が行われた。
-
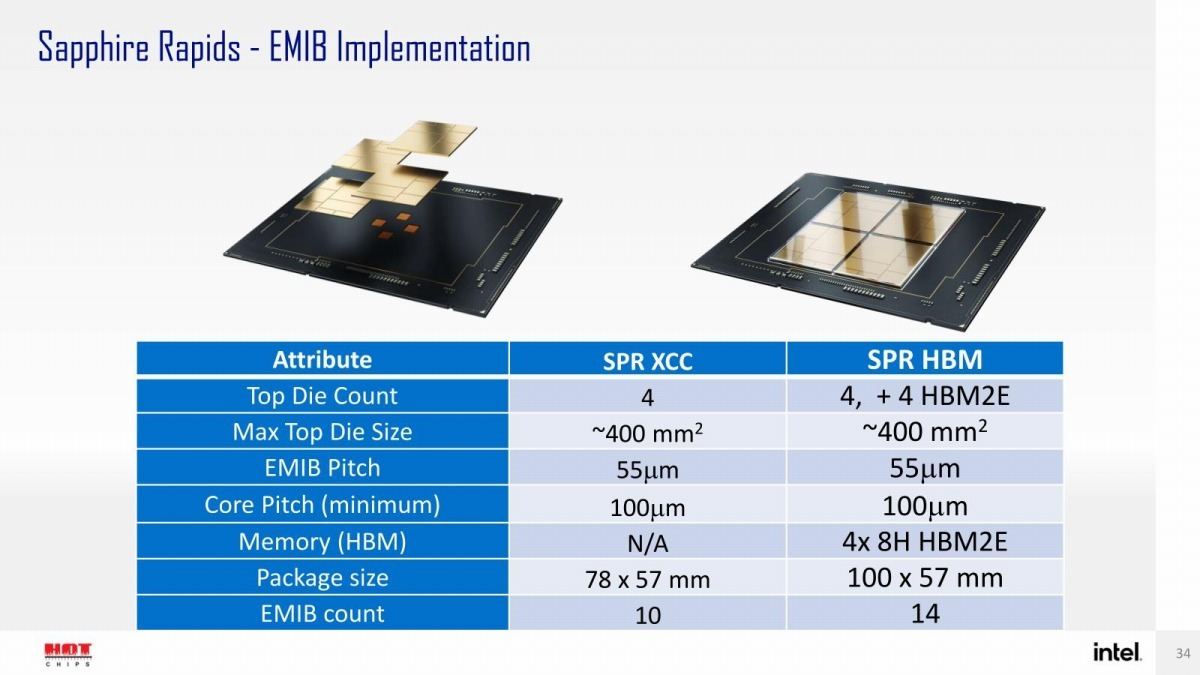
Photo03: 従来の説明図はPhoto03左側の様な構成で、EMIBはTile同士を繋ぐ4つのみと考えられていた。

-
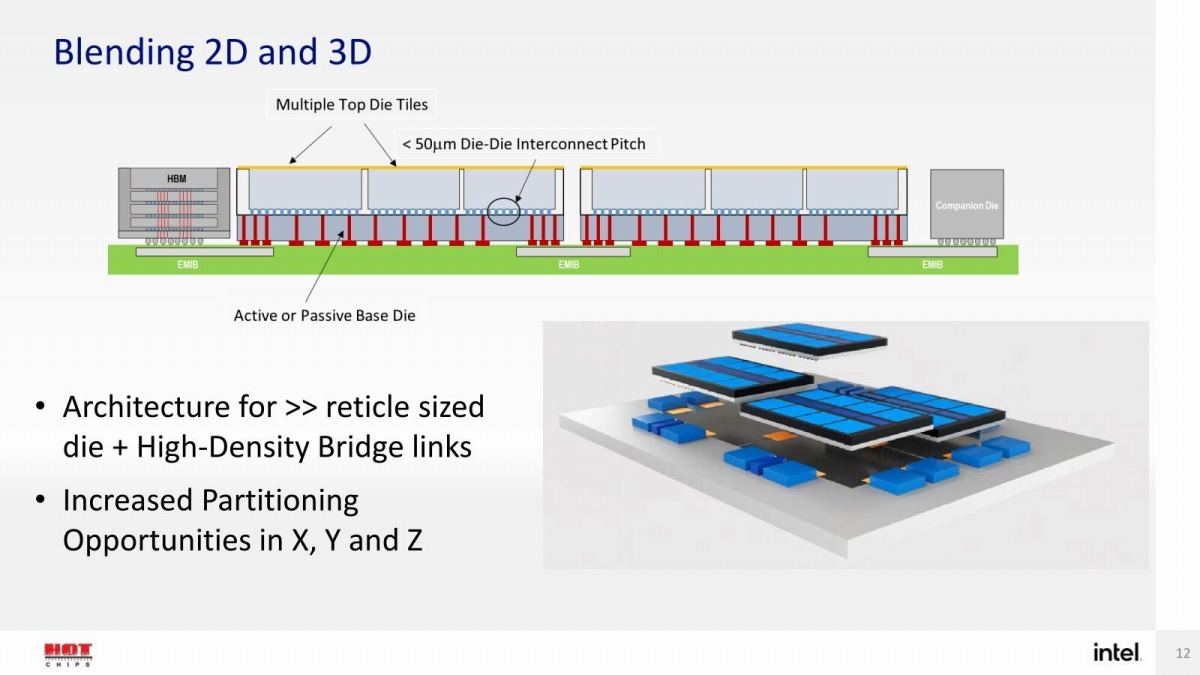
Photo04: ここで右下の図版がちょっと物議を醸しだした訳だが、この話はこの後のPackagingのUpdateで。結論から言っておけば、これは物理的には存在しないデバイスである。

そもそもEMIBが10というのは、これまでの説明に全然合っていない。これまでの説明、というのは要するに図1の様な構成を想定しており、これだと4 Dieで構成されるSapphire Rapidsの内部構成は図2の様な構成になる。ちなみにTileあたり4対のUPIが出る、という話はこちら(https://news.mynavi.jp/photo/article/20210820-1951586/images/054l.jpg)で明示されており、うち3対はパッケージ経由で外部に出て、1対がEMIB経由で内部のTile同士の接続に使われると想定していた。
-
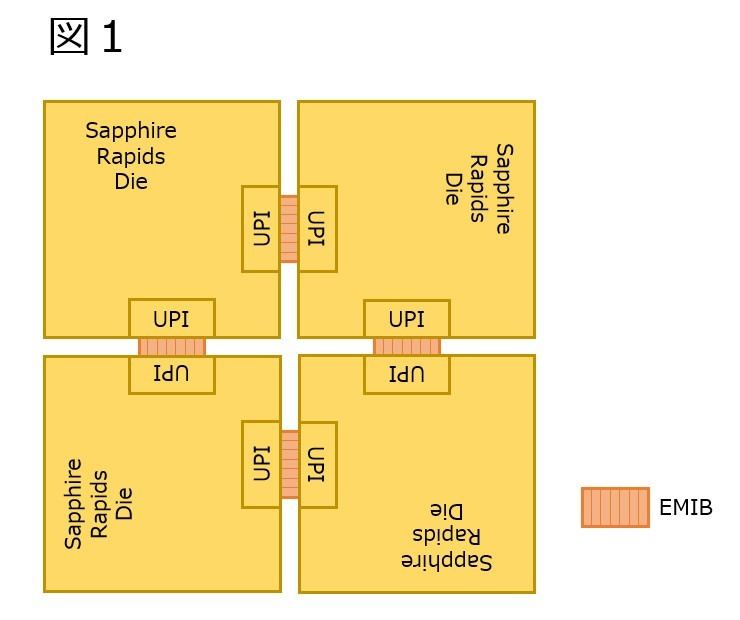
図1

-
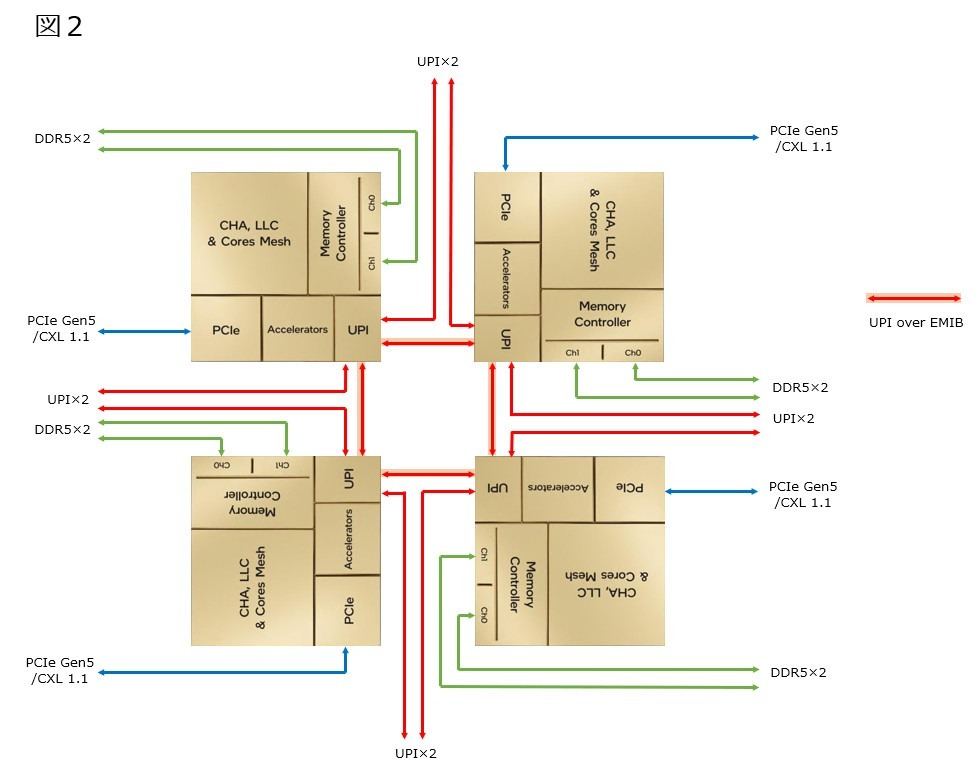
図2

ところがSPR XCCがEMIB×10というのは「Tile同士のUPI接続に×10」という事になる。この場合、図1の4つ以外は斜め方向の接続に利用される、と考えられる。図3の様な構成は考えられる。この場合、斜めのEMIB(しかも重なっている)をどう処理するか? という話になる。EMIBの断面構造そのものはPhoto04の様な形になっているわけだが、図3で言えば緑色のEMIBの接続は、実際には図4の様にブリッジを挟むことにすれば、一応斜め方向での接続も可能になる。このブリッジそのものもEMIBで構成し、更に図4でオレンジ色のEMIB部も、実際には別のパーツになっているとすれば、合計10で一応辻褄は合うことになる。その場合のシステム構成は図5の様になる訳だ。
-
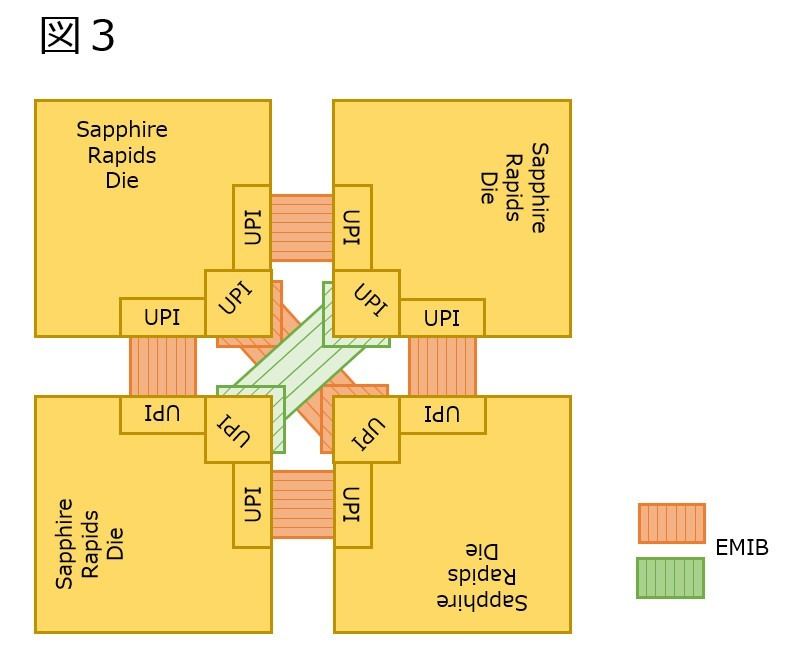
図3

-
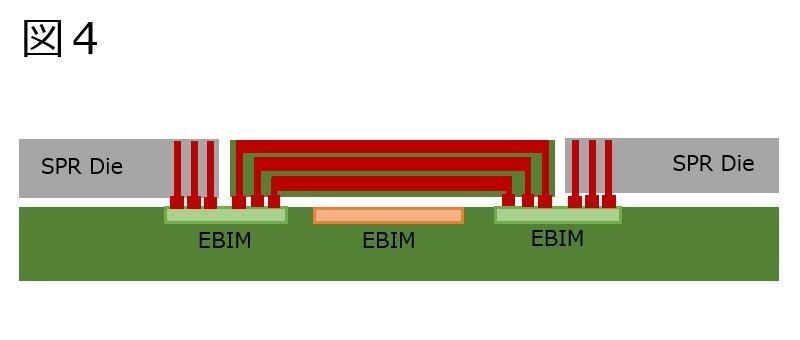
図4

-
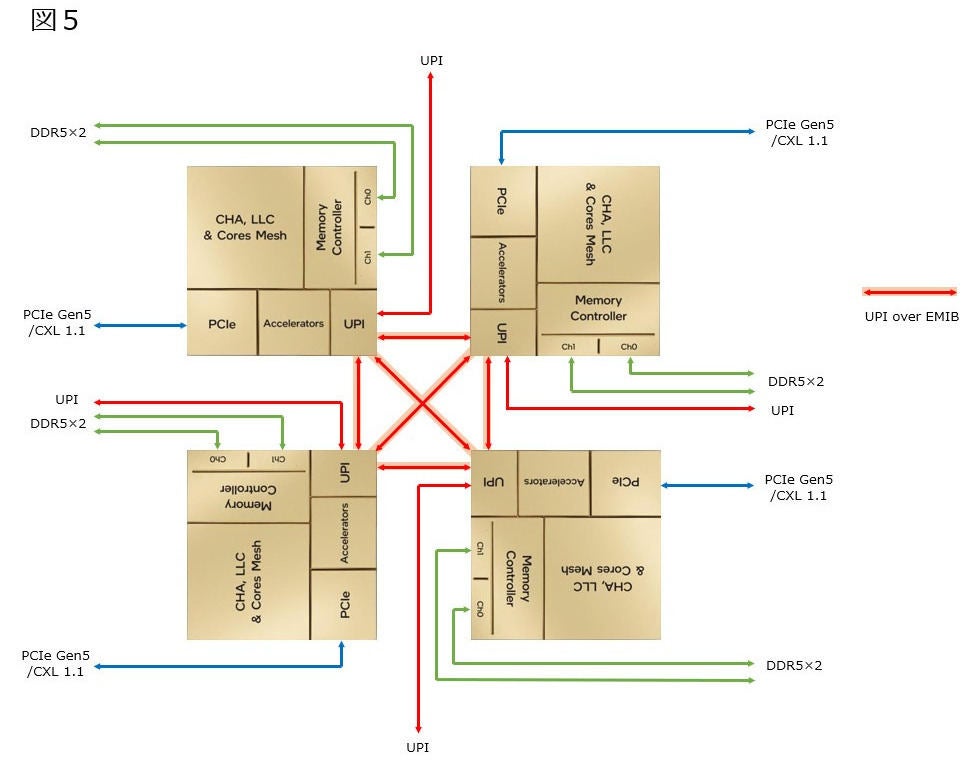
図5

もう一つの可能性は、「Tile同士のUPI接続に×6、Tile内のUPI接続に×4」である。この場合、クロスする斜め方向のEMIBが、図6の様に2層構造にすることが可能であれば実現は出来ると思う(今のところこれが可能という話は出てきていないが、不可能という話も聞いたことが無い)。なんでUPI接続がTile内に必要か? というと、質疑応答の中で説明者であるArijit Biswas氏が"in the 4-tile SoC we showed today each tile is symmetric, so a quarter of the IO lanes, mem channels, UPI links comes from each tile. for lower CC parts we will continue to support same # of lanes & channels so may not be a tiled design under the hood...either way, it looks monolithic to platform & SW regardless of whether the SoC underneath is tiled or a single monolithic die"(今回見せた4-Tileの構成は、I/Oやメモリが対称構成になっており、UPI Linkの1/4が各Tileから供給される。ただコア数が少ないSKUでも、I/OやMemoryチャネル数は変わりがない。なので、内部はTile構成ではなく、モノリシックかもしれない)という、非常に思わせぶりな返答を出したことによる。
-
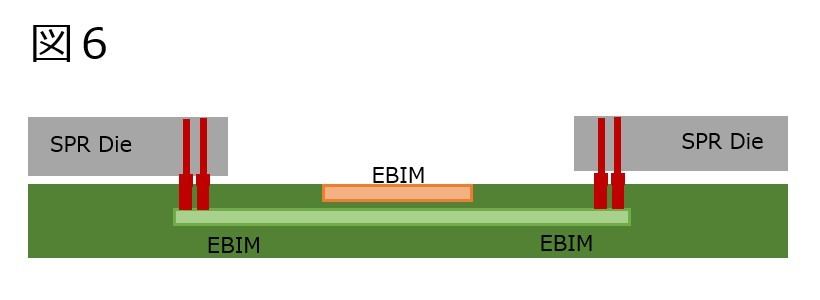
図6

例えば、であるがもしそれぞれのSPR Tileが図7の様な構成だとしたらどうなるか? というと、これは1/2 Tileの派生型が非常に作りやすくなる。図8は2-Tileのケースだが、コアとAcceleratorは2 Tile分ながらPCIe/Memory Controller/UPIは4 Tile分になるから、コアの数だけは減って、MemoryやI/O Channelは維持されるという訳だ。これはこれで、EMIBが10個という条件に適う事になる。
-
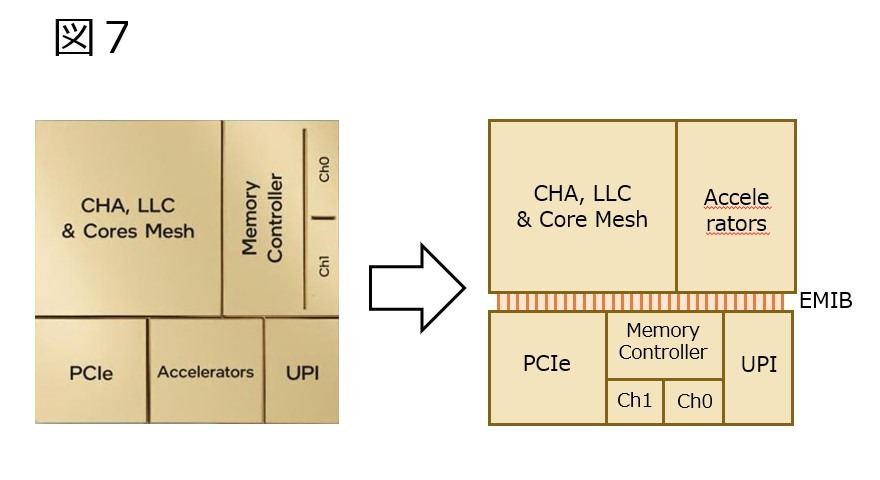
図7

-
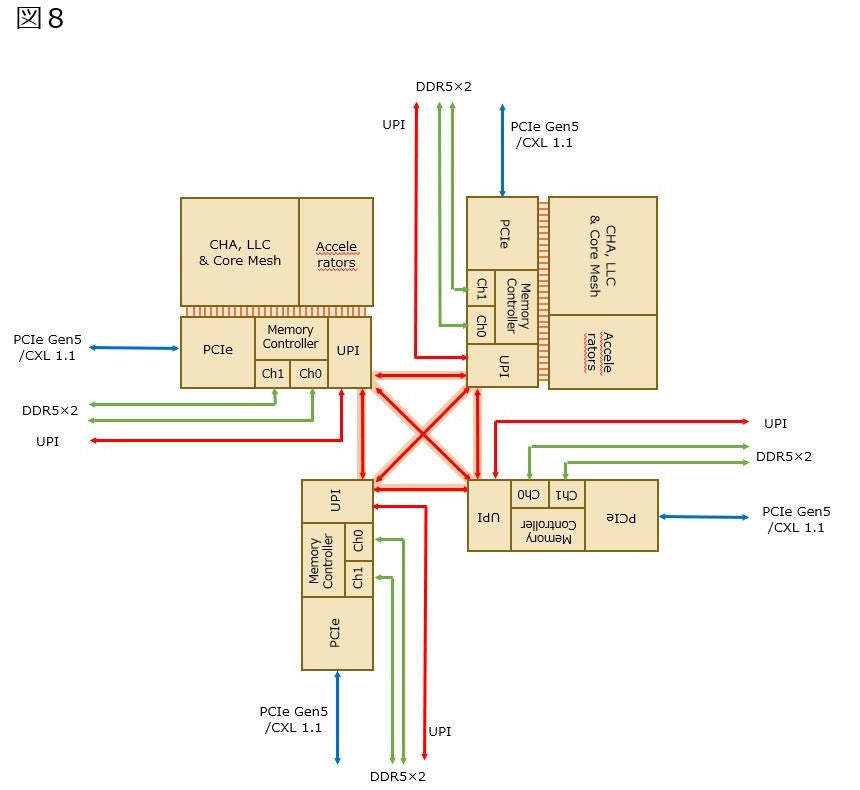
図8

さて、次の話は再びPhoto03に戻るか、SPR XCCとSPR HBMでパッケージが異なり、しかも長辺方向が伸びたことだ。Photo05はスライドに示されたSPR XCCのパッケージである。おそらくこのTileのサイズは正確ではないと思うが、そこは今回の問題ではない。問題はSPR HBMのパッケージで、長辺方向が100mmに伸びるという事は、パッケージ的にはPhoto06の様になる。つまり、HBMはPhoto06で言えばSPRのTileを挟み込むように配置するしかない(横方向に配置する余地はない)ということになる。
-

Photo05: ちなみにこの図に示されたSPRのTileのサイズは概ね331平方mm相当になるが、実際には400平方mmとPhoto03に記されているので、もう少しTileのサイズは大きくなるだろうし、そもそも正方形かどうかも不明である。

-

Photo06: これはPhotoshopを使って長辺を100mm相当に伸ばしてみた図である。

ところでこのHBM2eであるが、Memory ControllerはDDR5のMemory Controllerと共通かどうかを確認したところ、これもArijit Biswas氏より明快に"HBM controller is separate from DDR controller"という返事を頂いた。ということで、SPR HBMの場合、Tileは図9の様な形になる訳だ。
-
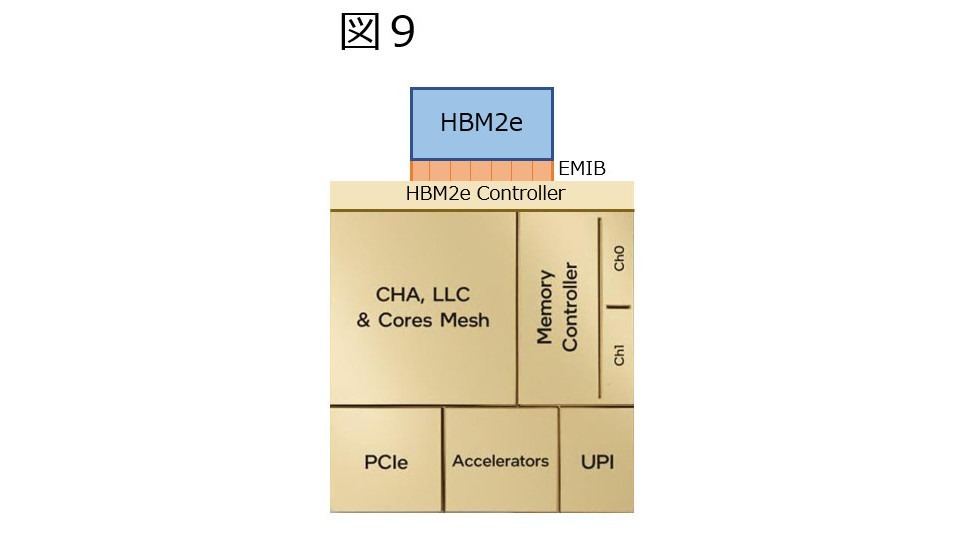
図9

さて、ここまでの図では、Tileを90°づつ捻りながら、UPIのI/Fが最小になる様に配置してきたわけだが、同じことをこのHBM付きで行うとどうなるか? というと、図10の様にHBM2eのStackが4方向に散らばる形にならざるを得ない。EMIBで延々と配線を引っ張って、Photo06の様にパッケージの上下方向に寄せるというのは現実問題として不可能である。それもあって、SPR HBMではむしろパッケージの横幅が増えるかと思ったのだが、実際には縦方向に増えてしまった。こうなると考えられるパターンは2つである。一つは図11の様に、HBM2eのI/Fが2か所に用意され、排他利用になっているパターンだ。これだと、図12の様にうまくHBM2eのStackをTileの上下に配することができる。ただHBM2eのI/Fもそう小さくはない上に、2つ設けるとなるとそれなりのエリアサイズになる訳で、そのあたりがネックにならざるを得ない。
-
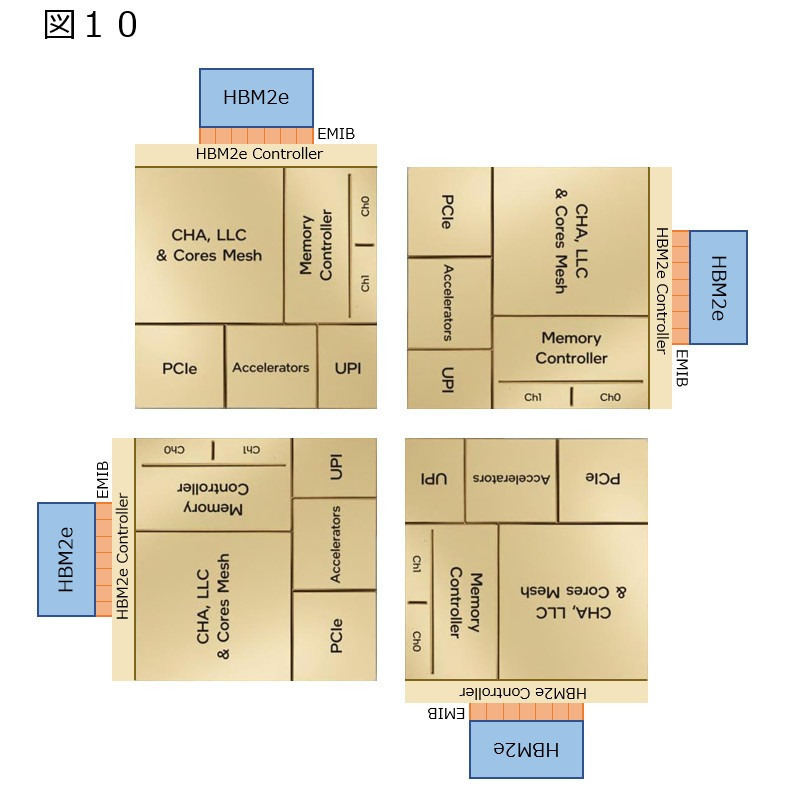
図10

-
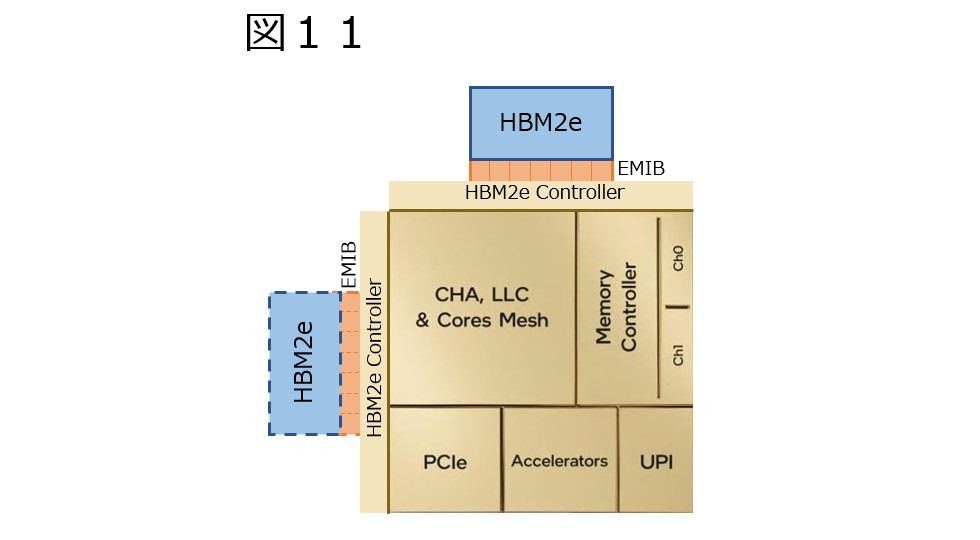
図11

-
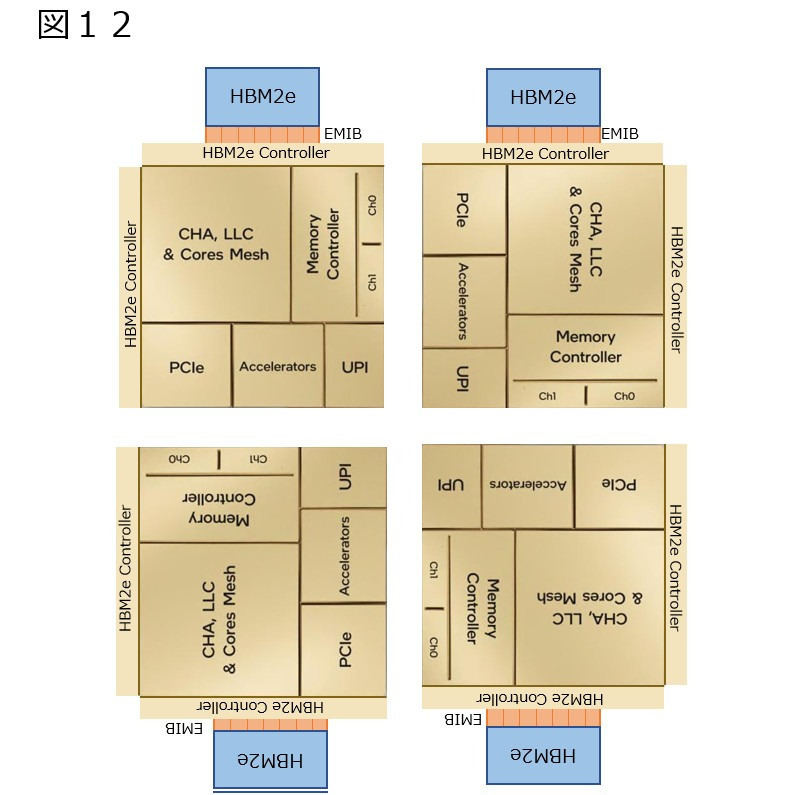
図12

もう一つの案は、2種類のTileがあるというものだ。つまり図13の様に、鏡対称な2種類のTileが存在すれば、これをひっくり返して配するだけで図14の様にうまくHBM2e Stackをパッケージの上下に追いやることができる。こちらの方が無駄にHBM2eのコントローラが存在しないからエリアサイズは小さくできる。それはメリットなのだが、今度は「同じコア数を持つ2種類のTileを用意する」というデメリットが生じる。つまり初期コストが2倍になる訳で、果たしてそこまでIntelが踏み切れるか、は未知数だ。
-
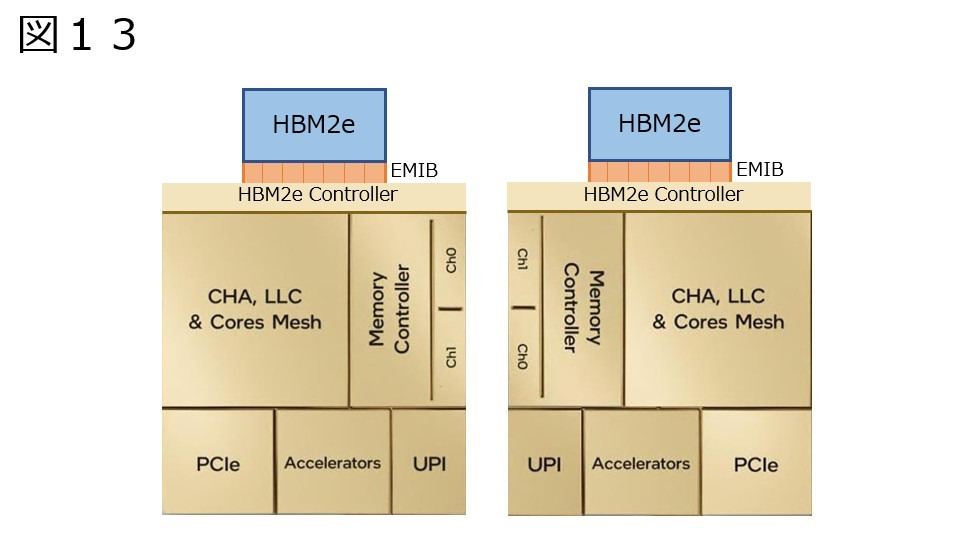
図13

-

図14

ちなみにコア数を含む詳細に関しては「製品Specは登場まで待て」ということで未公開のままである。色々謎の多いSapphire Rapidsだが、HotChipsの説明で更に謎が深まる格好となった。









{kind=link}