
こちらでも述べたように、8月22日よりHotChips 33が開催され、Intelは
- Intel Alder Lake CPU Architectures
- Next-Gen Intel Xeon CPU - Sapphire Rapids
- Intel's Hyperscale-Ready SmartNIC for Infrastructure Processing
- Intel's Ponte Vecchio GPU Architecture
の4つをConference Sessionで発表したほか、更にTraining Sessionで
- Technology Provider: Intel packaging technologies for chiplets and 3D
- Case Study: Intel products built with 2.5D and 3D packaging
の2つを発表しており、さすがRhodium Sponsor(普通のスポンサーのハイエンドはPlatinumだが、HotChipsに関してはその上のRhodiumが設定されており、Intelのみが名前を連ねている)だけの事はある。
さて、そのHotChipsで色々とAlder LakeのDetailが出てくるかと思ったのだが、ちょっと肩透かしだったのはP-CoreやE-Coreの詳細は殆ど出てこなかったことだ。その代わりと言っては何だが、Intel Thread Directorの詳細が説明されたので、この内容をご紹介したい。
まず、僅かに出てきたP-CoreとE-Coreの追加情報について。E-Coreの性能はSkylakeとの比較という形でSingle Thread/ Multi Threadが示されており、一方P-Coreの方はCypress Coveとの比較が示されただけだったが、今回はP-CoreとE-Coreの比較が示された(Photo01)。
-
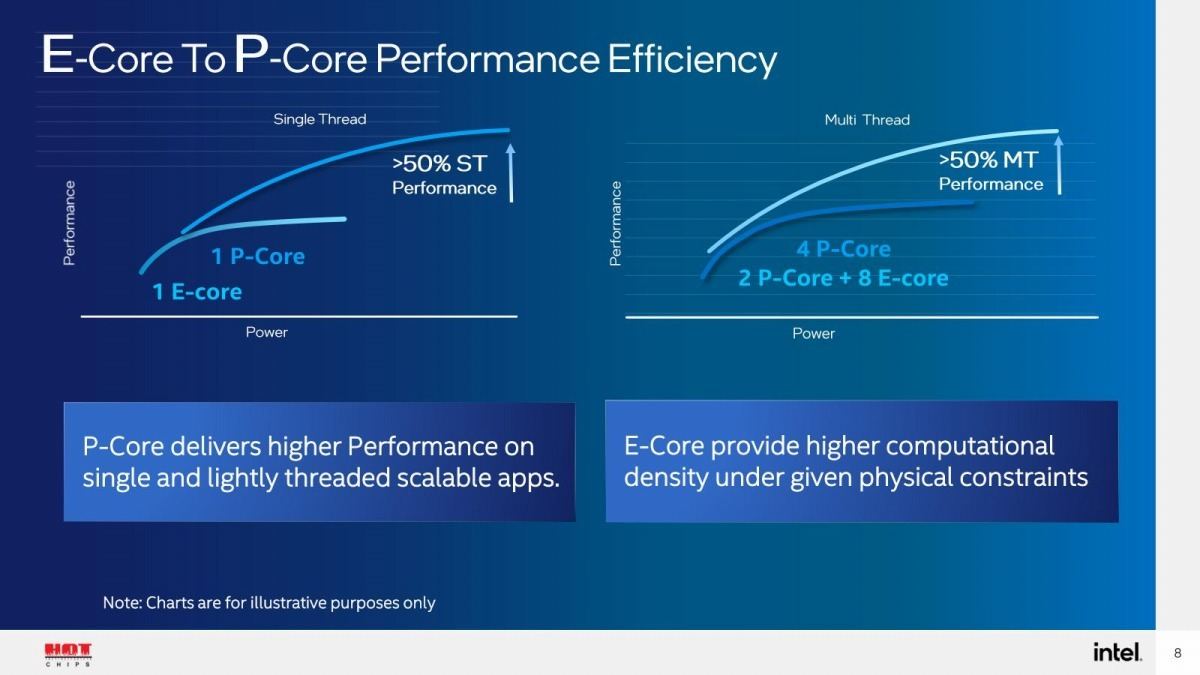
Photo01: Single ThreadにおけるE-Coreの頭打ち感がすごい。

ここで特徴的というか、極端と思うのはE-Coreの性能の伸びなさである。P-CoreとE-Coreは同じ製造プロセス(というか、同一のダイ)で製造されているので、この差はパイプライン構成の差ということになる。もともとE-Coreは、Tremont世代と比べてもかなりバックエンド側の増強が目立つのだが、その作り方が相当省電力方向に振れている事を物語っている。例えば、パイプラインの1ステージに仕込むロジックを多くすれば、結果的に少ないサイクル数で処理が出来るから段数も減るし、ゲートの数も減るから省電力にしやすいが、これの動作周波数を上げようとすると、途端にパイプライン動作が間に合わなくなる。これを避けるにはステージあたりの処理を減らして、その分ステージ段数を増やせばいいわけだが、これは消費電力増加になる。これは一つの例で他にもいくつかあるが、全体としてE-CoreはP-Coreの最低動作周波数あたりが一番効率が良い周波数であり、それ以上は動作周波数が殆ど上がらない構成になっている様に見える。
ただマルチスレッドで言えば、P-Core×4よりもP-Core×2+E-Core×8の方が効率が50%アップというのは、(P-CoreはHyperThreadingが利用できることを考えると)、P-Core×1よりE-Core×4の方が効率が良い、ということになる。これだけ考えると、Xeonの中でもXeon-D系の後継製品としてはE-Coreは非常に適している事になるが、今のところIntelはE-Core単体の製品は考えていないようであり、今のままだと(一部Alder LakeがXeonのローエンド向けに使われる可能性はあるが)基本はSapphire Rapids系のP-Coreベースだけで構成されることになるのかもしれない。
次はThread Directorの話である。Thread Directorの基本的な動作はこちらで説明したが、今回もう少し細かい話が出てきた。
まず基本的な機能であるが、単に実行される命令セットとか負荷だけでなく、消費電力や温度なども同時にモニタリングして、これらに基づいてをスケジュールを行うことが明らかになった(Photo02)。まず大前提だが、CPUの中ではClass 0~Class 3という4種類のTask Classが用意されている。Class 3はSpin Lockなどに代表されるもので、Class 0はMainstream、つまりP-CoreとE-Coreのどちらで実施しても大きく性能が変わらないものであり、Class 1はIPC比が1.50程度まで、Class 2はそれ以上のIPC比が得られるアプリケーションである。
-

Photo02: Thermalでは、これまでは温度が上がったらThrottlingなどで動作周波数(と電圧)を下げるなどで対処していたわけだが、今後は例えば強制的にE-Coreにスレッドを割り当てるといった対応も可能になることになる。

-
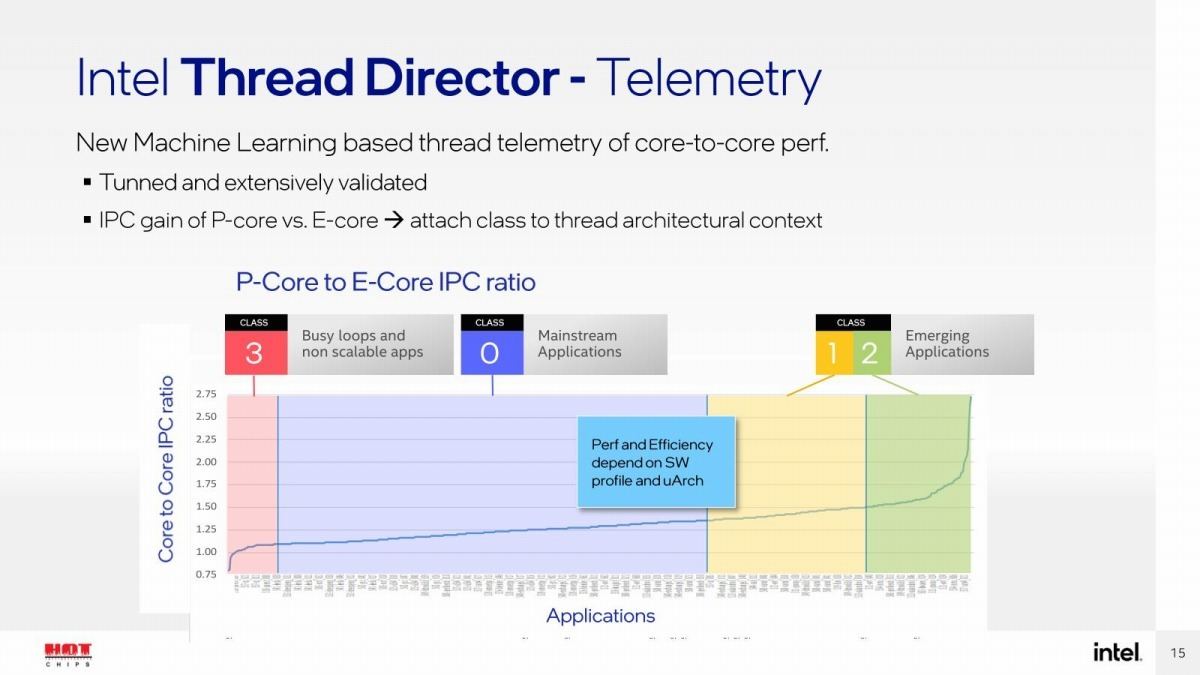
Photo03: このIPC比は要するにP-Core vs E-CoreのIPCの性能比である。

このClassとProcessorの関係は、EHFI(Enhanced Hardware Feedback Interface)と呼ばれるメモリテーブルに格納される。実はこのEHFIの構成はSDM(Intel 64 and IA-32 architectures software developer's manual)のVolume 3B(System programming guide)のChapter 14.6に"Hardware Feedback Interface"として定義されており(これが追加されたのは2020年10月の事だった)、Photo04に示すようなテーブル構造である。
-
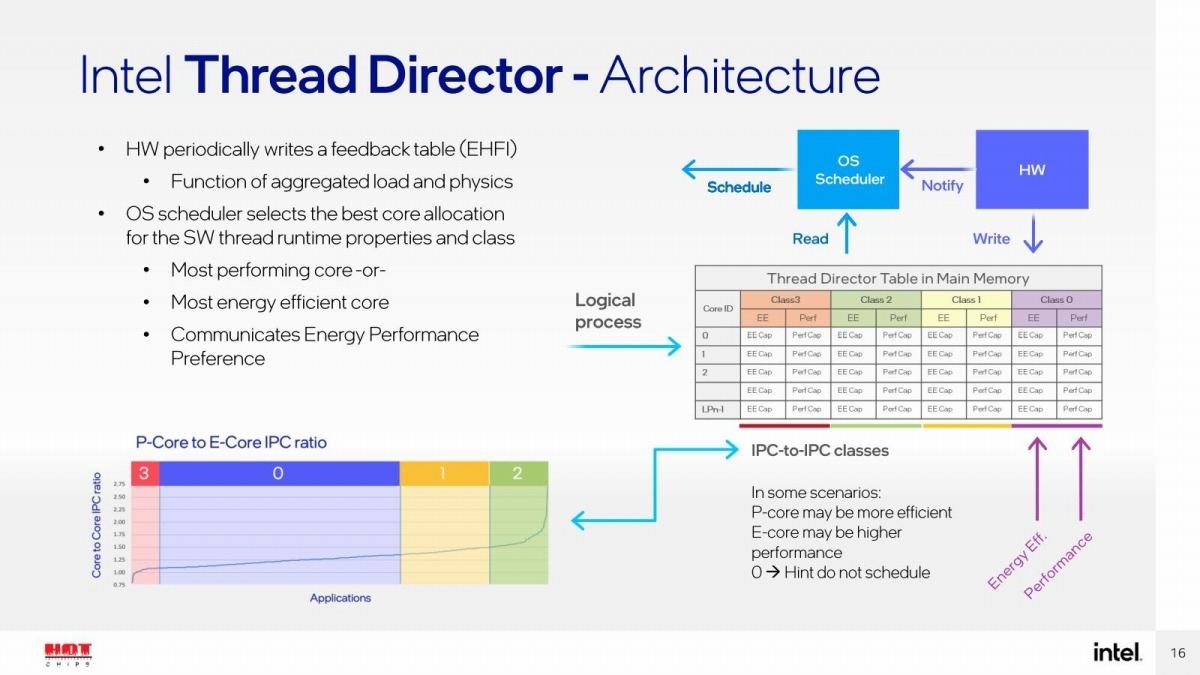
Photo04: モデルによってP-CoreとE-Coreの数が違うので、テーブルのサイズはモデルによって異なることになる。基本的には先頭16バイトがヘッダで、そのあとプロセッサ毎に8バイトづつのエントリが追加される(ウチ2バイトがTable、残りが予約である)。

各々のプロセッサは、Class 0~3に対して、それぞれEnergy EfficientとPerformanceのエントリを持ち、個々のEntryには0~255の数字が入る。これが何を意味しているかと言えば
- PerfCap(Performance Capability):0の場合、Perf Coreが必要なTaskはそのプロセッサコアには割り当てない。1~255は相対値で、高いほど性能も高い(255だと最高性能)事を示す。
- EECap(Energy Efficient Capability):0の場合、Energy Efficient Coreが必要なTaskはそのプロセッサコアには割り当てない。1~255は相対値で、高いほど省電力(255だと最高性能)事を示す。
となっている。実はこのテーブルはブート時には全部0であり、ハードウェアがこのテーブルを定期的に更新する仕組みだ(どういうアルゴリズムで、とかどのくらいの頻度で、というのはざっとドキュメントを読んだ限りでは明記されていない。ただ、テーブルを更新すると通知を出す機能があるほか、テーブルを初期化するHRESETという命令が新たに追加されている)。で、OSのスケジューラは自身がPerformanceコアが必要か、Energy Efficientコアが必要かというニーズに応じて、このEHFIを総なめして、一番適当そうなコアに割り当てる、という仕組みになっているわけだ。
これによるスケジューリングの模式図がこちら(Photo05)。先に、ドライバとかどうするんだろう? と書いたが、Kernelとかドライバは当然Priority Threadsに分類されるし、そういう設定をしておけばP-CoreからE-Coreに移る可能性はかなり減るわけで、あとはPriority ThreadsのClass 1~2をどうするかを考えればいいということになる。
-
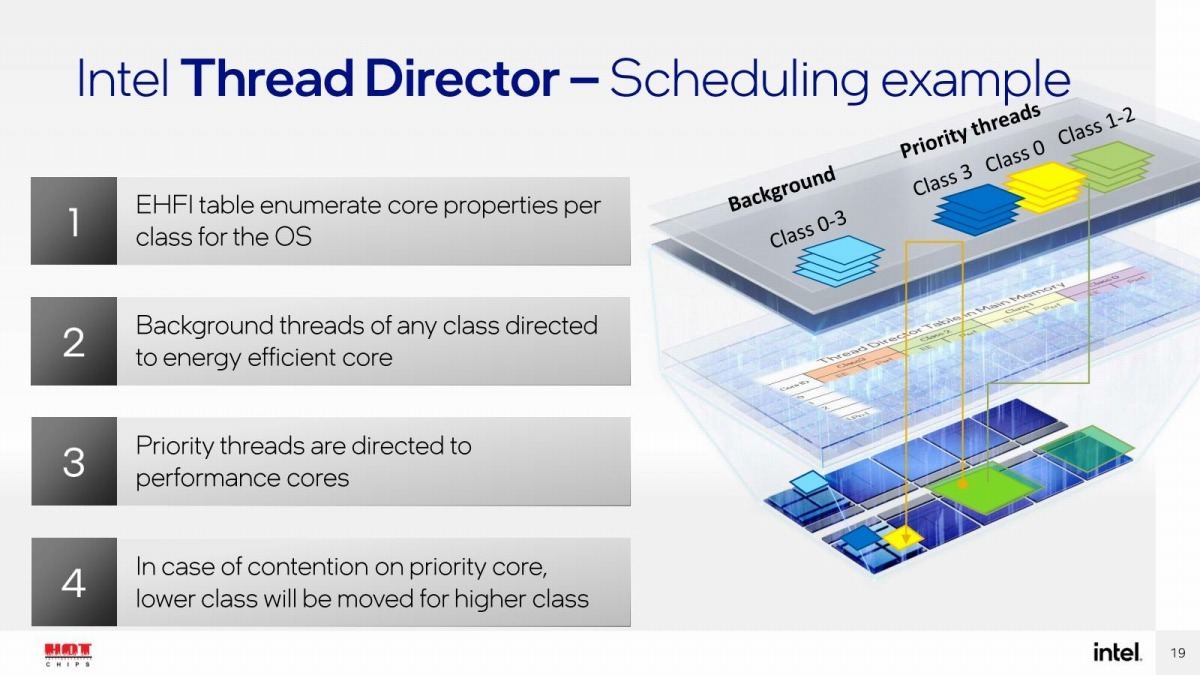
Photo05: この図に近いが、もう少し詳細が入った形になる。

Photo06は、Thread Directorを有効にした場合にどれだけ性能が向上するかの比で、Realtime ApplicationではE-Coreにスケジューリングされることが無くなるので性能が上がる、という状況が示されている。少なくともWindows 11で搭載予定のOS Schedulerと組み合わせれば、きちんと性能が上がるらしい事は示されたと言える。
-

Photo06: 縦軸の0位置は100%(つまりAlder LakeでThread Directorを無効化した状態)で、縦軸は「多分」性能比だと思うが、目盛り一つ分の単位は不明。

ちなみに上でちょっと書いた、消費電力に関する制御がこちら(Photo07)。理屈から言えば、たとえば本当に熱的に厳しくなったらThreadを全部E-Coreに移動する事で、放熱に問題があってもギリギリまで動き続けるなんて実装は可能だろうが、そうしたことがどこまで意味があるのかは良く判らない(むしろバシっと落ちてくれた方が、ユーザーに放熱の問題がある事を結果的に知らしめることになるので便利な気もするのだが)。
-
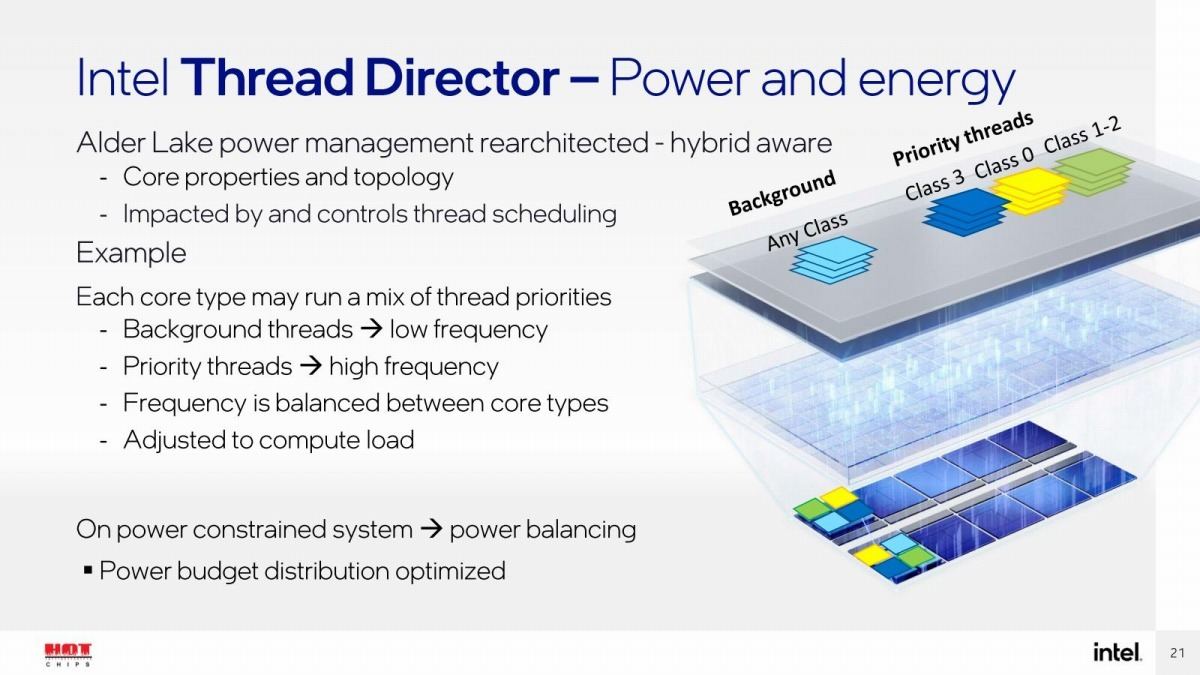
Photo07: もっともこちらはまだアルゴリズムなどは公開されていない(されるかどうかも不明だが)。

HotChipsでのAlder Lakeに関する新情報は残念ながらこの程度であった。とはいえ、Thread Directorの動作がもう少し明確になったのは喜ばしいところである。
ところで最後に余談を一つ。P-CoreはAlder LakeとSapphire Rapidsの両方で使われる関係で、Vector Unitには本来AVX-512のサポートも含まれている。ところがAlder LakeではAVX-512(やアクセラレータとして実装される)AMXは未サポートである。問題は、この状況でAlder LakeはAVX-512ユニットを「実装して無効化している」のか「削除した」のか、どちらだろう? という疑問が当然出てくる。
筆者は「実装して無効化している」案を取っていた。というのは、Alder Lakeはクライアントだけでなく、おそらくローエンドのXeon向けにも投入されると予測されるからだ。このケースでは、E-Coreを全部無効化した上で(E-Coreを有効化した状態だと、E-CoreがAVX-512をサポートしていないので、P-CoreもAVX-512を有効化できない)AVX-512を有効化して最大8コアのローエンドXeonとして投入する可能性が高いと思っていた。ただHotChipsの質疑応答で、同じ質問をEfraim Rotem氏に投げた人がおり、その答えは"It is a mix - some of the server features on Golden Cove are fused off in client and some are physically removed"(両方だ。Golden Coveのいくつかの機能はクライアント向けでは無効化され、いくつかは物理的に削除された)返事をしている。
ここでいくつかの機能というのは、例えばRAS関係などもその一つだが、これらは命令パイプラインの中にがっちり組み込まれているから、物理的に削除するのは大変に難しい。ところがAVX-512 Unitはそれだけで一塊になっているうえ、これが結構大きなエリアサイズであるから、物理的に削除するのは簡単だしメリットも大きい。という訳で、おそらくは物理的に取り除かれているものと思われる。









{kind=link}