
2018年8月、ようやくNVIDIA GPUで大きな動きがあった。まず新アーキテクチャの「Turing」を発表し、続いて20日のGamescom 2018にあわせてGeForce Gaming Celebrationを開催。ここでGeForce RTXシリーズの詳細が披露された。
もっとも詳細とは言いつつもまだこの時点では不明な部分も結構あったのだが、その後ホワイトペーパーが公開されるなどどんどん情報が出てきており、9月20日にいよいよ発売されることになる。これに先駆けてGeForce RTX 2080とRTX 2080 Tiの2製品を評価することができたので、その内容をお届けしたい。
TuringアーキテクチャとTU102/104/106
新しいTuringアーキテクチャの特徴は、すでに加藤勝明氏の記事で語られているので、繰り返しは避けるが、このGeForce RTXシリーズに向けてNVIDIAは3種類のダイを用意した。
ハイエンドがTU102で、これはGeForce RTX 2080 Ti(とQuadro RTX)向け、メインストリーム(?)がTU104で、これがGeForce RTX 2080向け、ローエンド(???)がTU106で、こちらが(現時点ではまだ具体的な出荷時期が明らかにされていない)GeForce RTX 2070向けとなる。
いずれの構成でもSM(Streaming Multiprocessor)はPhoto01の様な構成である。TU102の場合、このSMを2つまとめたTPC(Texture Processing Clusters)が6つでGPC(Graphics Processing Clusters)を構成。このGPCが6つ搭載される形だ(Photo02)。なのでフル構成では6GPC=36TPC=72SMという計算になる。CUDA CoreはSMあたり64個なので、最大4608 CUDA Core(GeForce RTX 2080 Tiは34TPC=68SMで、4352 CUDA Core)となる。
-
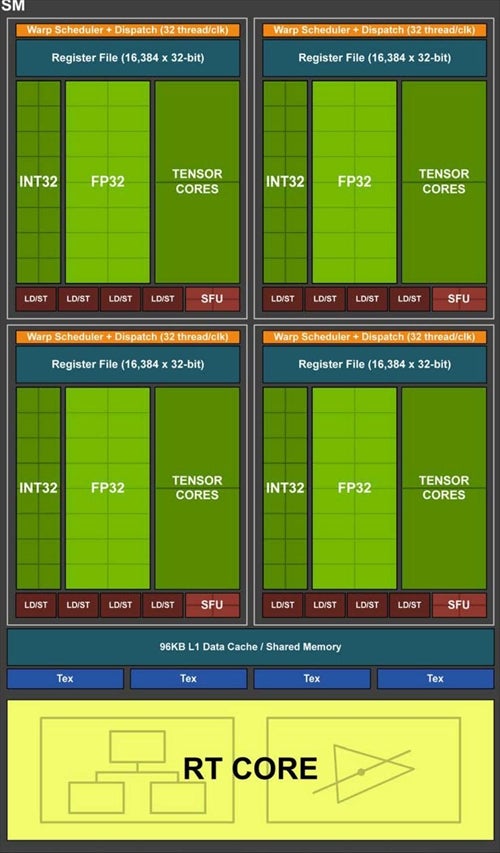
Photo01:Turing世代ではこのINT32とFP32が並行して稼働するのが大きなポイントとなっている。また1つのSMあたり1つの新しいRT Core(RayTracing Core)が搭載されている

-
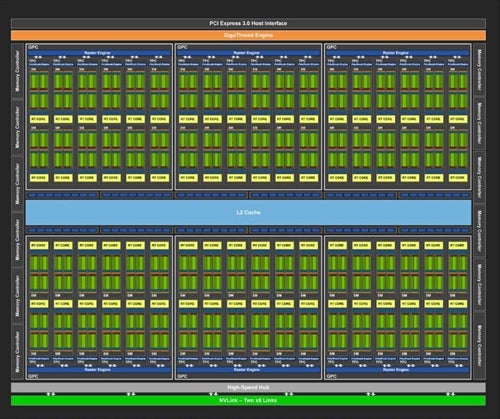
Photo02:ただしGeForce RTX 2080 TiはTPCを2つ無効化している。これもあってか、TU102そのものは本来L2が6MBだが、GeForce RTX 2080 TiはL2が5.5MBである

-

Photo03:L2は4MB

一方、GeForce RTX 2080向けのTU104は、6GPCなのは同じだが、1GPCあたり4TPUという構成になっている。なので6GPC=24TPC=48SMで2944 CUDA Coreという計算である。
またSLIの代わりに搭載されるNVLinkについて、TU102はx8 Linkが2組構成なのに対し、TU104ではx8 Linkが1組とされている。不思議なのは、この1GPCあたり4TPUという構成を取るのはTU104だけということだ。
というのは、GeForce RTX 2070向けのTU106では、GPCの数が3つに減る代わりに、1GPCあたりTPUが6つに戻っているからだ(Photo04)。なんでTU104だけこんな変な構成にしたのか疑問である。
-

Photo04:実はTU106もL2は4MBである

さらに言えば、TU104とTU106でメモリ回りの仕様がほぼ一緒、というのも腑に落ちない。L2は4MB、ROPは64基、メモリバスは256bitのGDDR6 14Gbpsとなっており、正直なところGeForce RTX 2070はもう少しメモリバス周りの性能を落としてもいいような気がする。
このあたりが、わかりにくいので抜粋したのが表1である。ついでなのでQuadro RTX 6000/5000も一緒にいれておいたが、GeForce RTX 2070とGeForce RTX 2080を比べるとスペック的にそれほど大きな開きがないことがわかる。案外お買い得というか、コストパフォーマンスが一番高いのはGeForce RTX 2070あたりかもしれない。
| 製品名 | Quadro RTX 6000 | GeForce RTX 2080 Ti | Quadro RTX 5000 | GeForce RTX 2080 | GeForce RTX 2070 |
|---|---|---|---|---|---|
| ダイ | TU102 | TU102 | TU104 | TU104 | TU106 |
| GPC | 6 | 6 | 6 | 6 | 3 |
| TPC | 36 | 34 | 24 | 23 | 18 |
| SM | 72 | 68 | 48 | 46 | 36 |
| CUDAコア | 4608 | 4352 | 3072 | 2944 | 2304 |
| L2キャッシュ | 6MB | 5.5MB | 4MB | 4MB | 4MB |
| ベースクロック | 1455MHz | 1350MHz | 1620MHz | 1515MHz | 1410MHz |
| ブーストクロック | 1770MHz | 1545/1635MHz | 1815MHz | 1710/1800MHz | 1620/1710MHz |
| メモリ | GDDR6 | GDDR6 | GDDR6 | GDDR6 | GDDR6 |
| メモリ容量 | 24GB | 11GB | 16GB | 8GB | 8GB |
| メモリバス | 384bit 14Gbps | 352bit 14Gbps | 256bit 14Gbps | 256bit 14Gbps | 256bit 14Gbps |
| メモリバンド幅 | 672GB/sec | 616GB/sec | 448GB/sec | 448GB/sec | 448GB/sec |
| ROP | 96 | 88 | 64 | 64 | 64 |
| Texture Unit | 288 | 272 | 192 | 184 | 144 |
| TDP | 250W | 250/260W | 230W | 215/225W | 175/185W |
| トランジスタ数 | 186億個 | 186億個 | 136億個 | 136億個 | 108億個 |
| ダイサイズ | 754mm | 754mm | 545mm | 545mm | 445mm |
| プロセス | TSMC 12FFN | TSMC 12FFN | TSMC 12FFN | TSMC 12FFN | TSMC 12FFN |
ところでこのTU102~TU106世代は、TSMCの12FFNを採用している。12FFNは2018年頭に紹介したが、要するにTSMCの16FF+のNVIDIAスペシャル版である。そのため、実際には16FF+を利用していたPascal世代から、トランジスタ密度そのものはあまり上げられない。
一方で、Pascal世代と比べてSMの中にTensor CoreやらRT Coreやらが入った関係で、明らかにトランジスタ数は増えることになる。つまり、必然的にダイが肥大化するのは避けられない。
表1にも示したが、ローエンドのTU106ですら445平方mmである。GeForce GTX 1080に搭載されていたGP104が72億トランジスタ、314平方mmだから、これを30%ほど上回っている計算だ。
GeForce GTX 1080 Tiに搭載されたGP102で120億トランジスタ、471平方mmとほぼ同等である。トランジスタ効率という観点で言えばGeForce RTX 2070がGeForce GTX 1080Ti並みの性能でないといけない訳だが、果たしてそこまでの性能が出るやら。
もっともNVIDIAの場合、真のハイエンドにあたるのはTesla V100に搭載されたGV100で、こちらは211億トランジスタ、815平方mmだから、こちらに比べればTU102やTU104はまだ可愛いという言い方もできるかもしれない。
とはいえそのGV100を搭載したNVIDIA Titan Vのお値段はほぼ3600ドルとかになっており、これとほぼ同等の原価が掛かっているであろう、GeForce RTX 2080 Tiを1200ドルで売り出そうとするNVIDIAの値段のつけ方がちょっと理解できないところではある。







