
既報の通り、IntelはLunar Lakeこと次世代Core Ultraの詳細をCOMPUTEXのタイミングで公開した。こちらについて、Intelの資料を基にもう少し掘り下げてご紹介したいと思う。
Package
先の記事にも、ASUSのZenBookの基板に搭載されたLunar Lakeの写真があったが、これの別スナップ(撮影は同じく笠原光氏)をもう少し拡大したのがこちら(Photo01)。パッケージ全体はかなり正方形に近いが、微妙に縦長である(幅27mm×高27.5mm)。Lunar LakeもMeteor Lake同様にFoverosを利用したChiplet構成であるが、Meteor Lakeと異なりLPDDR5Xもパッケージに積層する関係で高さが合わない。Meteor Lakeの周囲にあるシルバーのメタルガイドは、恐らくこの高さの差を埋めるためのものと思われる(Photo02)。
-

Photo01: 横の台湾の1元硬貨(直径20mm)からパッケージサイズを算出した。

-

Photo02: ヒートシンクは、このメタル部をガイドとして使う形で、不用意な物理的な接触によりダイを破損させないための、いわばバンパー的な役割を担っているだけだろう。

P-Core
Lunar LakeはP-Core×4+E-Core×4という構成であるが、まずそのP-Core。大きな変化はHyper-Threadingの無効化である。Hyper-ThreadingはP-Coreの場合、一般に30%のIPC(またはThroughput)向上が見込める半面、20%の消費電力増加につながる、とする(Photo03)。そこでP-CoreのHyper-Threadingを無効化(というか、削減)したことで、性能/消費電力比などの改善に繋がった(Photo04)としている。当たり前の話として、Hyper-ThreadingというかSMTを有効にすると、当然実行ユニットの利用効率が上がるから、性能は上がるけど(同時に動作する実行ユニットの数が増える分)消費電力も増える。で、SMTを無効化すればトータルの性能は落ちるが、逆にSingle Threadで考えた場合にはこれまで取り合いになっていた実行ユニットを常に自分で独占できる訳で、その分性能は多少ながら向上する。そしてこれはAlder Lake以降のIntelのアーキテクチャでは顕著であるが、本来Hyper-ThreadingというかSMTの対象として利用されやすい「雑多な軽い処理」は、Thread Directorを使って優先的にE-Coreに振り分けされる傾向にある。なので、P-Coreで処理するプログラムがMulti-Threadedなものであれば効果があるが、Single-ThreadedなプログラムであればHyper-Threadingでの効果は得られにくい。後述するように、Lunar LakeはSnapdragon X Eliteを仮想的にしている節があり、少しでも待機時消費電力を減らしたいというニーズが強い。その一方でプロセッサ性能の方は、Single Thread性能が上げられれば、Multi-Thread性能の方はE-Coreとの合わせ技でカバーできる。なるほどSingle-Thread Onlyになるのも無理もないところである。
-
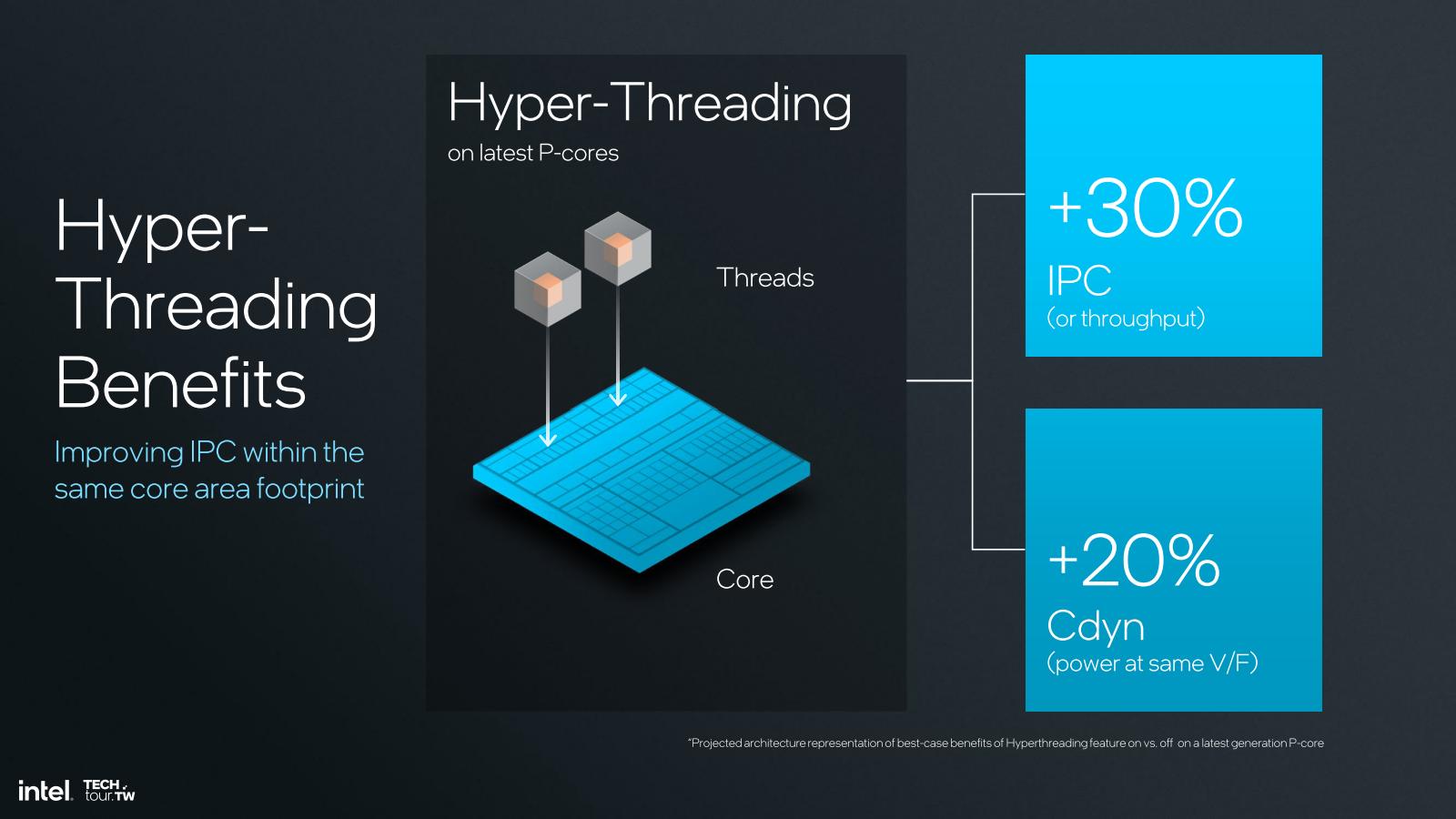
Photo03: 元々のPentium 4では、Decoderの性能が悪くて実行ユニットをフルに使えない事の対策であったが、本来のSMTはたとえばメモリ待ちなどによる実行ユニットの空きを別Threadの実行で埋めることで、実行効率を改善するのが目的である。

-

Photo04: 逆にMulti-Threadな処理(例えばCineBenchのMulti)などはむしろ性能が落ちる事になる。

さて、本来P-CoreからHyper-Threadingを無効化しても、そこで10%を超えるようなエリア削減は難しい「筈である」。実際Hyper-ThreadingというかSMTを有効にしたところで、そこで別々に管理するリソースはそう多くない。PC(Program Counter)を始めとしていくつかのレジスタ類は二重持ちする必要があるだろうが、殆どのレジスタ類はSMTを有効にした際にそれがどちらのThreadのモノなのかを明確にするために1bitの管理bitを追加する程度で済むはずだからだ。ただ実際はSMTで性能を出そうとすると、レジスタ類の増量が必要になる。例えばROB(Re-Order Buffer)、Single Threadで100エントリあるとすれば、SMTの場合は200とは言わないまでも150位にしておかないと、ここがボトルネックになる可能性がある。こうしたものを全部Single Threadに最適化してゆくと、相応の面積削減にはなるだろう。今回IntelはLion CoveはHyper-Threadingを無効化したのではなく、削除したと明確に説明している。恐らく論理設計レベルではSMTを有効化できるオプションはまだ残しているだろう。ただそれを物理設計に移す段階で、SMT削除を行い、冗長なレジスタ類を排除しているのが面積削減に繋がっているものと思われる。このLion Coveは次のArrow Lakeでも使われるらしいので、こちらもHyper-Threadingが無効化されている可能性は大きい。
さてそのLion Coveそのものについて。P-Coreのアーキテクチャは
Alder Lake:Golden Cove
Raptor Lake:Raptor Cove
Meteor Lake:Redwood Cove
Lunar Lake:Lion Cove
という具合に変わっているが、Golden Cove/Raptor Cove/Redwood Coveは基本的には同一アーキテクチャであり、Golden Cove→Raptor Coveの差はL2キャッシュ容量(1.25MB→2MB)でしかないし、Raptor Cove→Redwood Coveは命令L1キャッシュ容量(32KB→64KB)の違いに留まる(細かいBug Fixなどは除く)。これに対してLion Coveは"Overhaul microarchitecture"とある(Photo05)様に、比較的大きく手が入っている。まずFront End。
Decode:6 wide→8 wide
MicroCode:2 wide→4 wide
μOp Cache:9 wide→12 wide
と猛烈な強化が行われた(Photo06)。μOp Cacheが12 wideと言う事は、最悪でも1cycleあたり6 x64命令の供給ができるということで、恐らくアベレージでは9 x64命令近くになるだろう。
-

Photo05: 最後の"Modernize design database"は設計手法の話であって、直接性能などに関係する話ではない。これについても後述。

-

Photo06: 当然μOp Queueの方も相当容量を増やしていると想像される。あとPredictionも最大8倍(文言を見ると履歴を最大8倍取るという意味に見える)が、これをまともに実装したら大変な事になるので、何かしらテクニックを使っているのだとは思う。

次いでBack End。そして実行ユニットは
ALU:5 wide→6 wide
FPU:3 wide→4 wide
とかなり強化されている(Photo07)。これに合わせて当然Instruction Windowも強化されてるし、遂にRetirementが12 wideまで拡張された(Photo08)。先にアベレージで9命令/cycle位を処理できるのではないか?と書いたが、このうちALUが6命令を処理し、残りがLoad/Store Unitという感じになりそうだ。そのALUも、例えばJump/Shiftは2→3になったほか、MulがRedwood CoveではMul+MulHiという変な構成だったのをMul×3にしており、またP0~P5までに割と均等に処理を割り振る様になっている(Photo09)。
-

Photo07: IDIVが見当たらないのは、MISCに含まれてしまったのだろうか?

-

Photo08: 発行ポートも遂に18である。

-

Photo09: Jumpが3、というのも冷静に考えると凄い話である。

一方FPUは、Redwood Coveが3つの発行ポートに無理やりいろんな処理を突っ込んでいたのを整理して、4つにうまく分散させたという格好である(Photo10)。特にRedwood CoveまではFMA256×2+FMA512みたいな変な構成だったのを、恐らくFMA256×2に分散。またFP ALUは3→4に、FP DIVは1→2にと地味に演算能力を引き上げているのが判る。
-

Photo10: あくまでLion Coveはクライアント向けということか、AVX512は実行できても1命令/cycleに抑えるようだ。ただ逆に256bit SIMDは×4になるわけで、AVX256の性能を高める方向に振っているのが判る。これ、Granite Rapidsとかこのあたりはどうなっているのか興味が尽きない。

そして実行ユニットの数と実行効率を改善した以上、それに見合うだけMemory Subsystemも強化する必要がある。まずCacheで言えば、従来のL1 D-CacheがL0 D-Cacheになり、新たに中間的な容量とLatencyのL1 D-Cacheが追加されたほか、全体的に容量の拡大が図られている(Photo11)。またLoad Store Unitも、
Redwood Cove:AGU×5、Store Data×2
Lion Cove:AGU×6、Store Data×2
とAGUが強化され、またD-TLBのエントリ数も強化されている(Photo12)。
-

Photo11: L0/L1/L2というよりも、L1/L2/L3と言うべきなのだろうが、外部に共有L3がある関係でL0にせざるをえなかったということか。L1が丁度中間的なLoad-to-Use Latencyなのが面白い。

-

Photo12: Load AGUは×3で変わらないが、Store AGUが2→3になった。

改めてRedwood CoveまでのALU/FPUを見ると、ポートを増やさずに無理やり実行ユニットを追加して、なので最適化というかスケジューリングがかなり難しくなってたのを整理し、発行ポートも追加して無理なく実行できるようにした、という感じであり、なるほど「オーバーホール」という言い方がふさわしい感じだ。
加えて電源管理周りも強化された。まず遂に(?)電源管理がAIベースになった(Photo13)ほか、大きな違いとしてClock倍率が16.67MHz刻みになった(Photo14)。説明では、これでよりギリギリまで動作周波数を上げられる様になった、としているし実際そういう面もあるのだが、その一方で同じだけ動作周波数を上げるためにはこれまでよりも煩雑に倍率変更が必要になる(倍率変更の回数が6倍になるから、例えば300MHz上げるのにこれまでなら3回の変更済んだのが18回に増える)事になる。勿論この辺はやりようは幾らでもあり、例えば温度/電力枠にゆとりがある時は6bin単位での更新、ギリギリになったら1bin単位で更新という風にすれば、それほど変更回数が増えない事になる。このあたりの調整も、そのAIに任せているという事なのかもしれない。
-

Photo13: もっともこれ、何をもってAIと呼んでいるかが良く判らないのでアレだが。AIを使って制御、という話はAMDもRyzenのPrecision BoostにAIを搭載と以前説明しており、ただこちらも何をどうしているのかの詳細は不明である。

-

Photo14: Ryzenは25MHz刻みだから、これを下回ったことになる。

こうした積み重ねでIPCを平均で14%改善した(Photo15)、というのがIntelの説明である。その性能改善は動作周波数が低いところほど顕著であり、動作周波数が高いところでは10%程度なのが、低くなるほど増え最大では18%以上になるとされている。ただSnapdragon Xと競合するのであれば、P-Coreそのものの消費電力は5W以下が想定される訳で、こうした領域で大きくIPCを伸ばしているのは好ましい特性と言える。
-
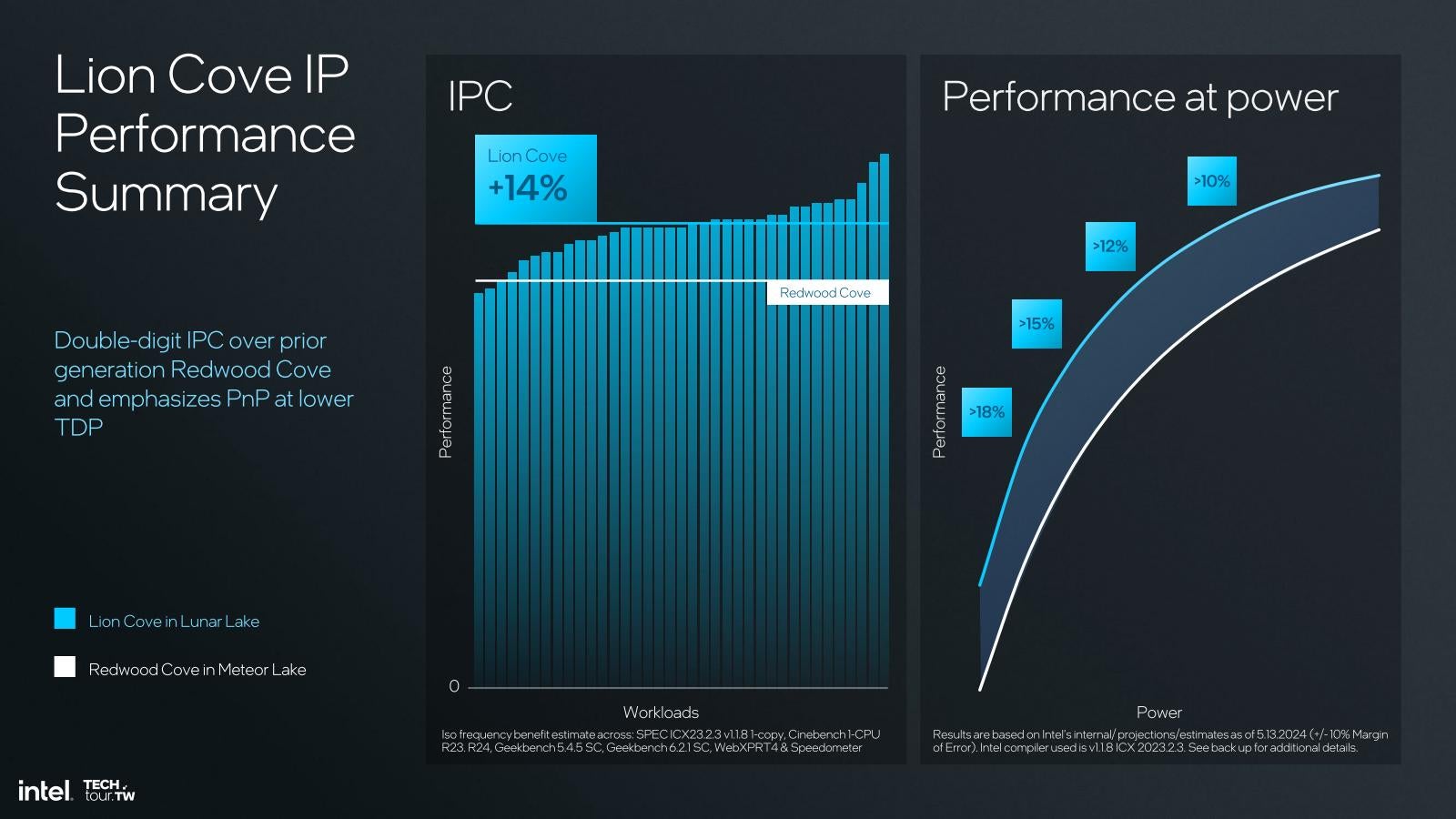
Photo15: 内容的にはこちらと一緒だが、特に低いTDPで効果が大きい、というコメントが追記されている。

最後が"Modernize design database"の話(Photo16)。Redwood CoveからLion Coveに移行するにあたり、設計技法をだいぶ変更したらしい。一つは内部の論理構造を大幅に作り替え、より大きい単位でのコンポーネント化を実現したこと、恐らくコンポーネント内部の作り方を変えた(Latch dominated→Flop dominated)こと、それとプロセス依存性からの脱却である。要するに以前は小部品を集めて構成していたものを、より大規模なモジュラ化することで効率化を図ると共に、そのモジュラ同士の接続方式を改善した、という話に読める。恐らくだが、これまでは小さなコンポーネント部品を大量に繋ぎ合わせる関係で、すべてのコンポーネントを連携して動かすためにはLatchを使ってきちんと同期させる必要があった。ところがコンポーネントのサイズが大きくなると、その内部はある意味勝手に動いても構わない(コンポーネント間はLatchを使って同期する必要はあるが)から、コンポーネント内部のLatchの数を大幅に減らすことが可能になったものと思われる。Latchはある意味SRAMであって面積も喰うし、このLatchにClockを分配するのにもそれなりの消費電力(と配線)が必要になるから、Latchを減らせればそれだけで回路規模と消費電力を抑えられる。Process-node-agnosticは「今まではそうなってなかったのか」という驚きも若干あるのだが、Lunar LakeやArrow LakeはTSMCを使って製造される関係で、物理設計は兎も角として論理設計はなるべく特定ファウンダリ/ノードに依存しない様に作らないと、プロセスを変えるたびに論理設計のやり直しが発生する事になる。これを極力抑えるようにした、ということである。とはいえ、99%非依存というのはまだ1%も依存部が残ってるという話であって、P-Coreの規模を考えると結構多いな、という印象も受ける。
-

Photo16: 別にProcess-node-agnosticだからといって、TSMC N3B用の設計をそのままIntel 3で製造できるとか言う訳ではなく、物理設計に関しては特定ファブの特定ノード向けになるのは変わらない。その上の論理設計に関して、特定ファウンダリ/ノードの特徴に依存するような構造を可能な限り排除した、という話である。

E-Core
P-Coreもこれだけ中身が一新されている訳で、E-Coreも当然大幅に改良が施された。主要な設計目標はこの3つである(Photo17)。workload coverageやscalabilityはまぁ判らなくもないのだが、VectorのThroughputを倍増させるというのはやはりXeon向けを意識したもの、と考えるのが妥当なのだろう。そもそも現在のE-Coreは2020年にElkhart Lakeに実装されたTremontコアがベースで、
Tremont:Elkhart Lake
Gracemont:Alder Lake/Raptor Lake
Crestmont:Meteor Lake
Skymont:Lunar Lake
と来ているが、Tremont以来AVX512の実装を行っていない(そうした負荷の高い処理はP-Coreに任せることで消費電力と実装面積を削減する)というポリシーがあり、これはLunar Lakeにも引き継がれている。ただそれでもVector Throughputを増やす必要があったという事で、技術的にはAVX512を1cycleで処理できるThroughputを実現するに至っている。
-

Photo17: ただXeon向けはともかくLunar LakeでVectorのスループットが上がってもメリットは薄いので、VNNIの演算性能が倍増した事を前面に打ち出した気がする。Scalabilityの強化も、Lunar LakeというよりはSierra Forest向けの特徴と言えよう。

まずFront Eng側。PredictionとPrefetchであるが、随分また派手に強化したものだ、という感じである。
-

Photo18: Predictionの検索範囲を128Byteに増やしたという事は、要するにPrefetchの幅を128Bytes/cycleに強化し、しかもこれを1cycleで検索できるという事になる。また最大96命令をPrefetchできるというのも凄まじい。

そして次のDecode段が非常に意味深である(Photo19)。Tremont以来、E-CoreのDecodeは3-wide×2構成だった。Hyper-Threading無効時はこれを6-wideとして処理できるし、有効時はThread毎に3-wide構成のDecodeが可能という仕組みだった訳だが、今回×3構成になったというのは、つまり将来はコアあたり3 Threadが有効になるHyper-Threadingが実装される可能性がある事を示唆している。
-

Photo19: Microcodeをさらに分解、Nanocodeと呼ばれるものにして、複数の命令を並行してデコードできる様にしたとしている。クラスタ単位でのParallelismとしているから、つまりHyper-Threadingを無効化するとMicroCode命令を1cycleあたり3命令処理出来ることになる。

Lunar LakeはE-CoreはHyper-Threadingが無効化されているが、Sierra ForectではHyper-Threadingが有効化されており、288コアの製品は最大576 Threadとして動作するデモが2023年に行われている事からもこれは間違いない。Sierra Forestではコアあたり2 Threadだが、Sierra Forestの後継として名前が上がっているClearwater Forestでは、あるいはコアあたり3 Thread動作になっていても不思議ではないことをこのDecode段は示唆している。
話をLunar Lakeに戻すと、これに合わせてμOp Queueも96に増量されている。Hyper-Threading無効の状態で比較した場合、単純にCrestmont世代と比較して1.5倍のDecode Performanceが実装された格好になる。
Backendも、これに合わせて当然強化された(Photo20)。Crestmont世代の構成はこれとか、これを見ていただくのが早いが、
Allocate/Rename:5 wide→8 wide
発行ポート:17→26
Retirement:8→16
と、ほぼ1.5倍の命令発行能力と2倍の実行能力を実装している。実質的には1.5倍位の処理性能で、Hyper-Threadingをフル活用するともう少し性能が上がる、という感じだろうか? これにあわせて、Load/Store Unit周りの強化も凄まじい(Photo21)。バッファ周りも色々強化されているらしいが、今回具体的な数字は示されていない。この辺はまたOptimization Manualが更新されたら具体的な数字が出てくるだろう。
-

Photo20: こちらではAllocationが6→8になったと記されているが、"Intel 64 and IA-32 Architectures Optimization Reference Manual"には5となっているので、これは5のTypoと筆者は判断している。

-

Photo21: ROBが倍近い(256→416)というのも凄いところだが。Physical Register Filesは表には出てこない話だが、もし先の推測が正しいとすれば最大3 Threadの同時動作をサポートするために、相応にPhysical Register Filesを増強しないと効率が落ちる。多分Crestmont比で1.5倍位にはなっていそうだ。

そして実行ユニットだが、Lion Coveを凌ぐぐらいに強化されている。ALU(Photo22)は遂に8つになり、Jumpも5つ、AGUもLoadが×3、Storeが×4である。もっともこれ、Single Threadで使い切れるかといえばかなり厳しい感じで、恐らくはHyper-Threading有効時に性能を引き上げるための方策だろう。その一方で動作周波数は低く抑えられるので、結果的にIPCが上がる(動作周波数を下げてもLLCとかメモリの速度は落ちないから、それだけLatencyが減る事になり、結果としてIPC向上に繋がる)格好だ。
-
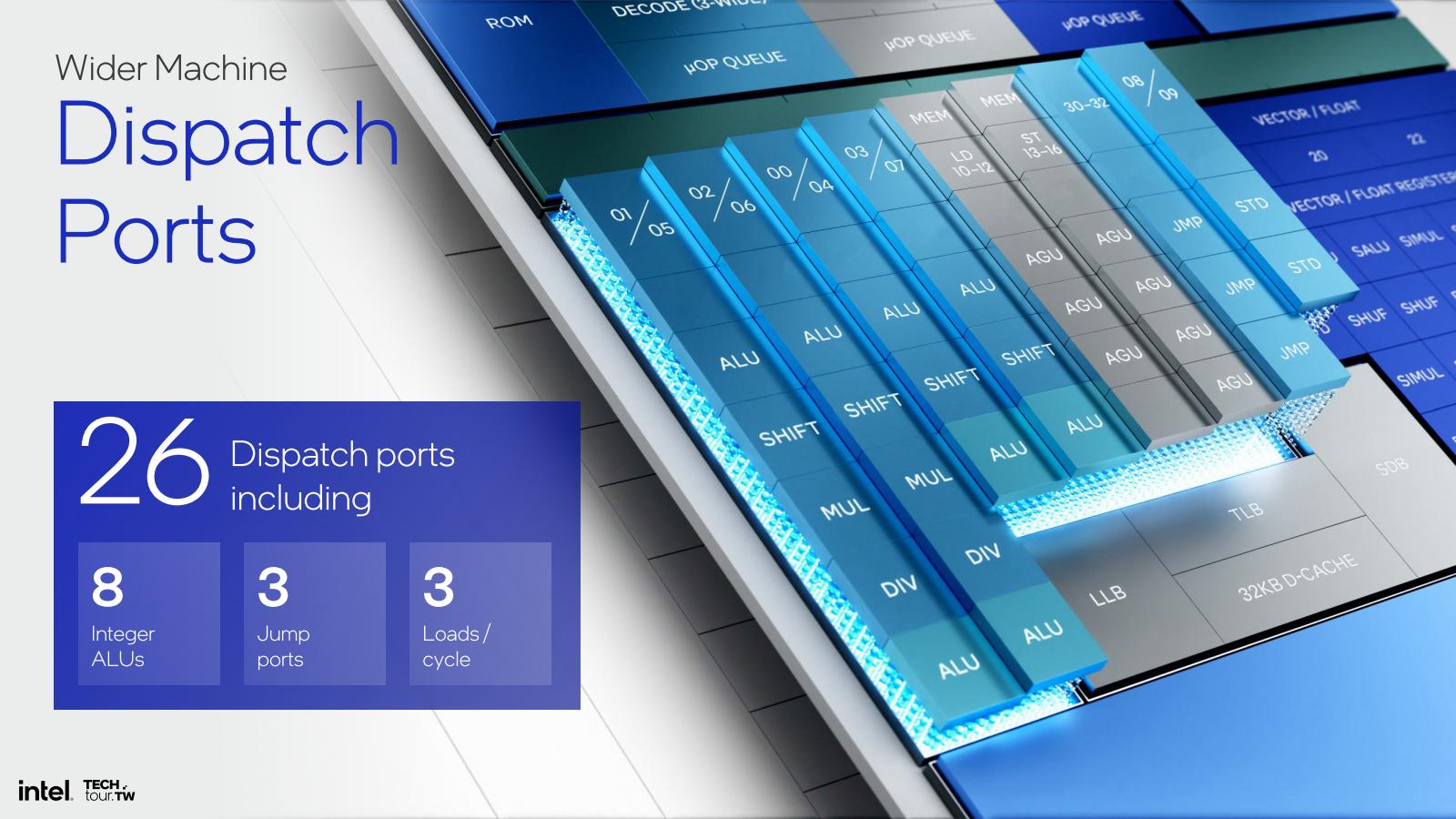
Photo22: Port 05~08はALUだけなのか、それともShift/Mulとかまで搭載するのかは現状良く判らない。

またFPUもCrestmontが3+2(FPU×3、LSU×2)だった発行ポートが4+2(FPU×4、LSU×2)に強化。実質512bit/cycleの処理性能を発揮するに至っている(Photo23)。当然Load Store Unitの強化も著しく、L2のTLBは4192 Entryまで増強されている(Photo24)。L2の容量そのものは増えていないが、帯域が倍増しているとされる(Photo25)。
-

Photo23: これ、連動させればAVX512も処理できるし、Xeon向けはそのオプションが有効化されている可能性もある(LSUが3×128bit Load/cycleというあたりは、可能性としては低いが)。Lunar Lakeは引き続きAVX256までのサポートで、ただしThroughputが2倍という格好だろう。

-

Photo24: Loadは×3なのにStoreが×4というアンバランスさがちょっと謎。AGUの数で言えばLion Coveより多いのだが、Lion Coveは256bit幅なので、帯域そのものはLion Coveの方が上である。

-

Photo25: L1 to L1については具体的な説明が無いので判らないが、L2にStore→L1にForwardするのではなく、直接Routingするような仕組みでも入ったのだろうか?

さて、こういう強化を行ったことでCrestmont比で整数演算で平均1.38倍、浮動小数点演算で1.68倍の性能改善がもたらされた、とする(Photo26)。もう少し具体的に、Lunar Lakeの様なモバイル向けの構成で言えば、まずSingle Threadでの性能と消費電力のカーブがこちら(Photo27)。TSMC N3Bを使っている分もあるとは思うが、同じ性能なら消費電力は大幅に下げられるし、同じ消費電力なら最大1.7倍の性能を発揮するとする。Multi-Threadは更に差が大きいが(Photo28)、こちらはLunar Lakeの方がコアの数が2倍と言う事を勘案すると、おおむねPhoto27と同傾向と言えるかと思う。
-

Photo26: 何故普通のE-CoreではなくSoC Tileに入ってる方のLP E-Coreと比較するのか、というとLunar LakeではE-CoreがLow Power Islandに配されているからという事だそうだ。

-
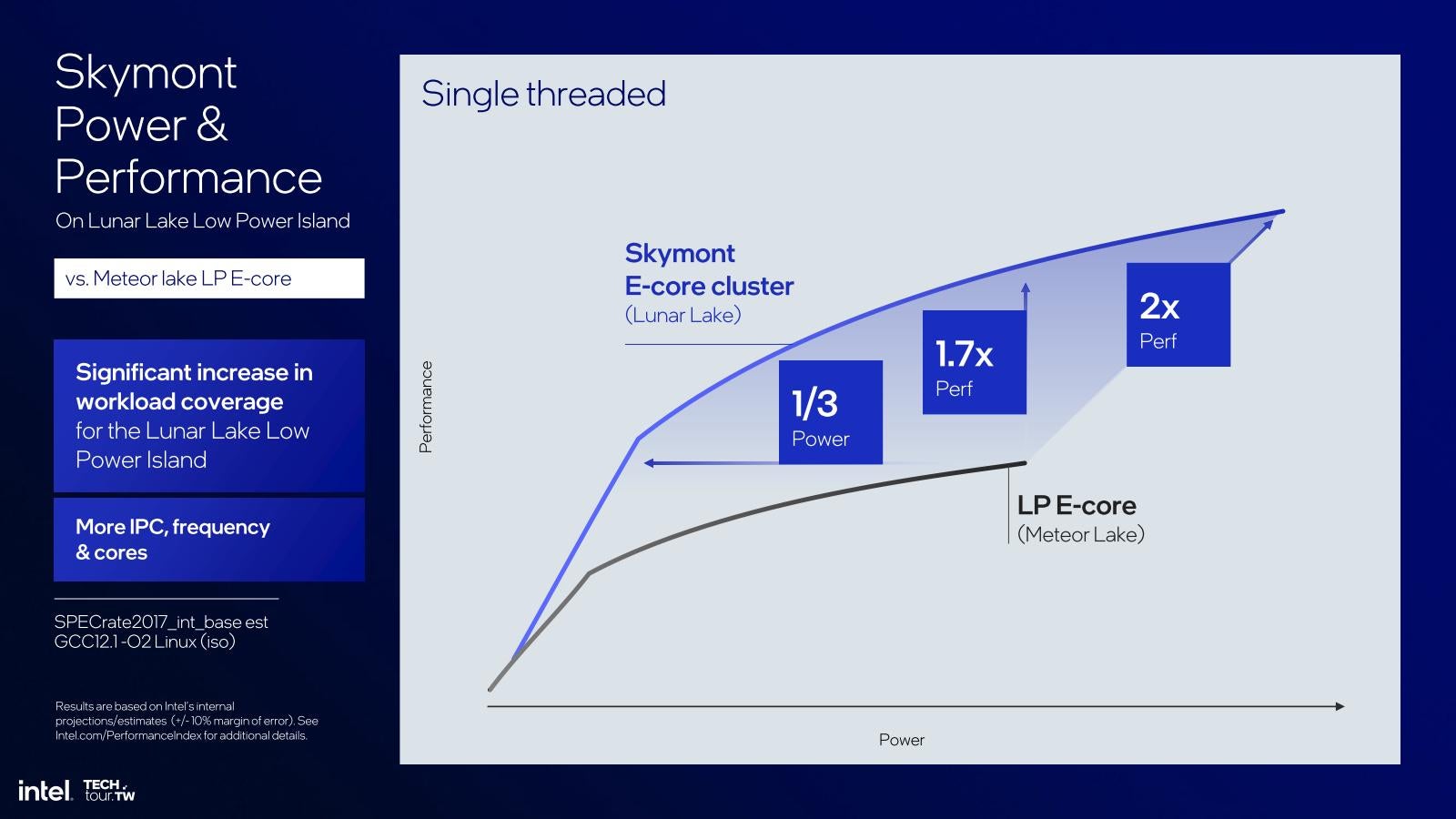
Photo27: 多分Meteor LakeでCompute Tileの側の(つまりIntel 4の側の)E-Coreの方はもう少し上が伸びそうではあるのだが。

-
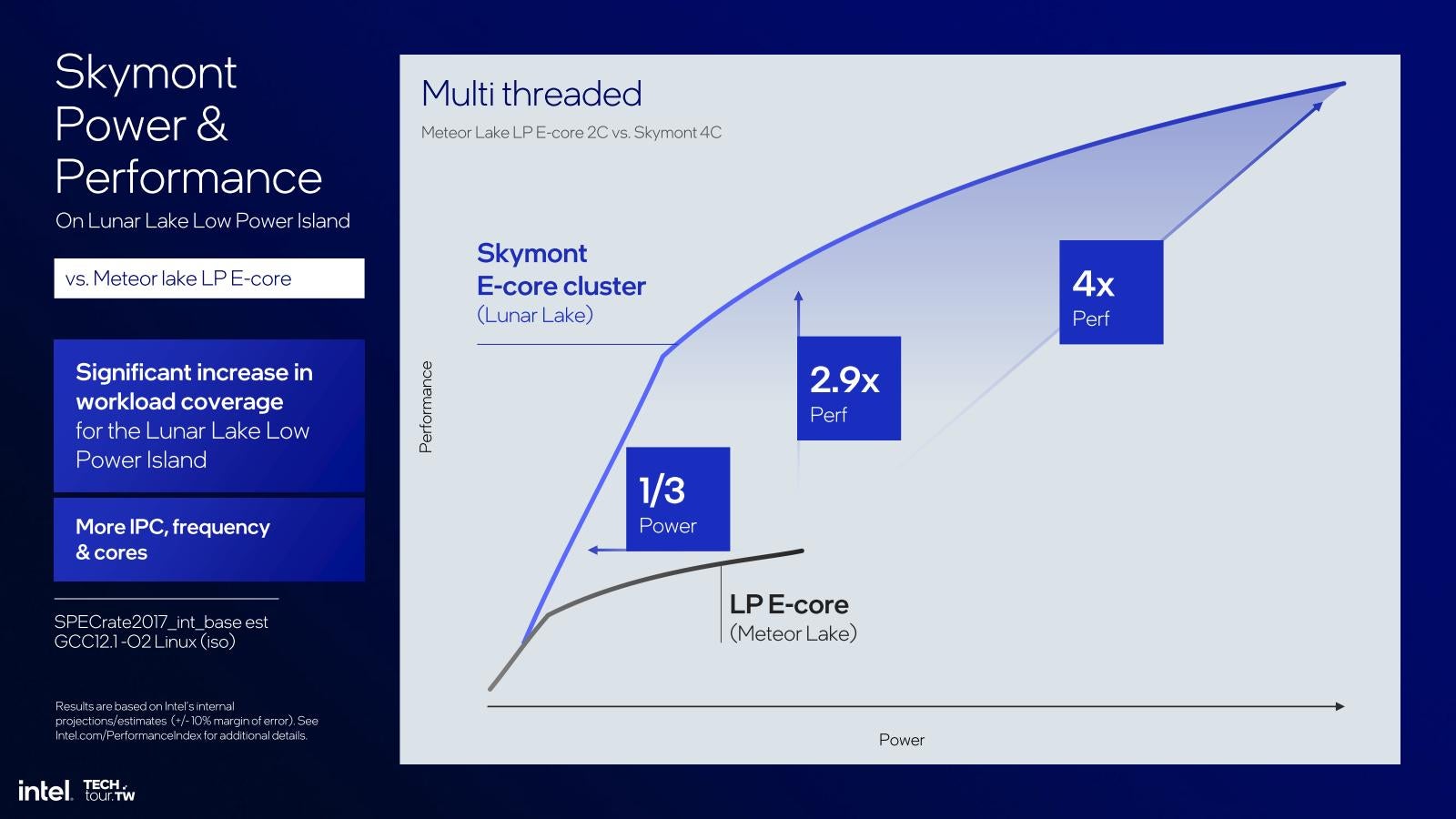
Photo28: それでもコアの数が2倍にも拘わらず、同じ性能なら消費電力が1/3なのは、多分Photo27の時の半分までE-Coreの動作周波数を落としたためだろう。低ければ低いほど効率的に動くからだ。

一方、これはRaptor Lakeと同等の構成を想定したDesktop向けのシミュレーション結果である(Photo29)が、比較対象はCrestmontではなくRaptor Coveである事に注意。整数演算/浮動小数点演算共にRaptor Lake比で2%増しとなっている。実際Single Thread性能はRaptor Coveをわずかに凌駕している(Photo30)。この青い枠の部分を拡大したのがこちら(Photo31)で、低消費電力領域においては、同じ動作周波数なら消費電力40%減、同じ消費電力なら動作周波数20%増が達成されている。勿論SkymontはPhoto30に示すように動作周波数の頭打ちが早めなので、あまり高速動作には向かないのだが、Raptor Lakeのケースで見ても2~3GHz程度までは動作しそうだし、その範囲ではRaptor Lakeすら凌ぐ性能が出せるというあたりに、コアの強化ぶりが良く判る。
-
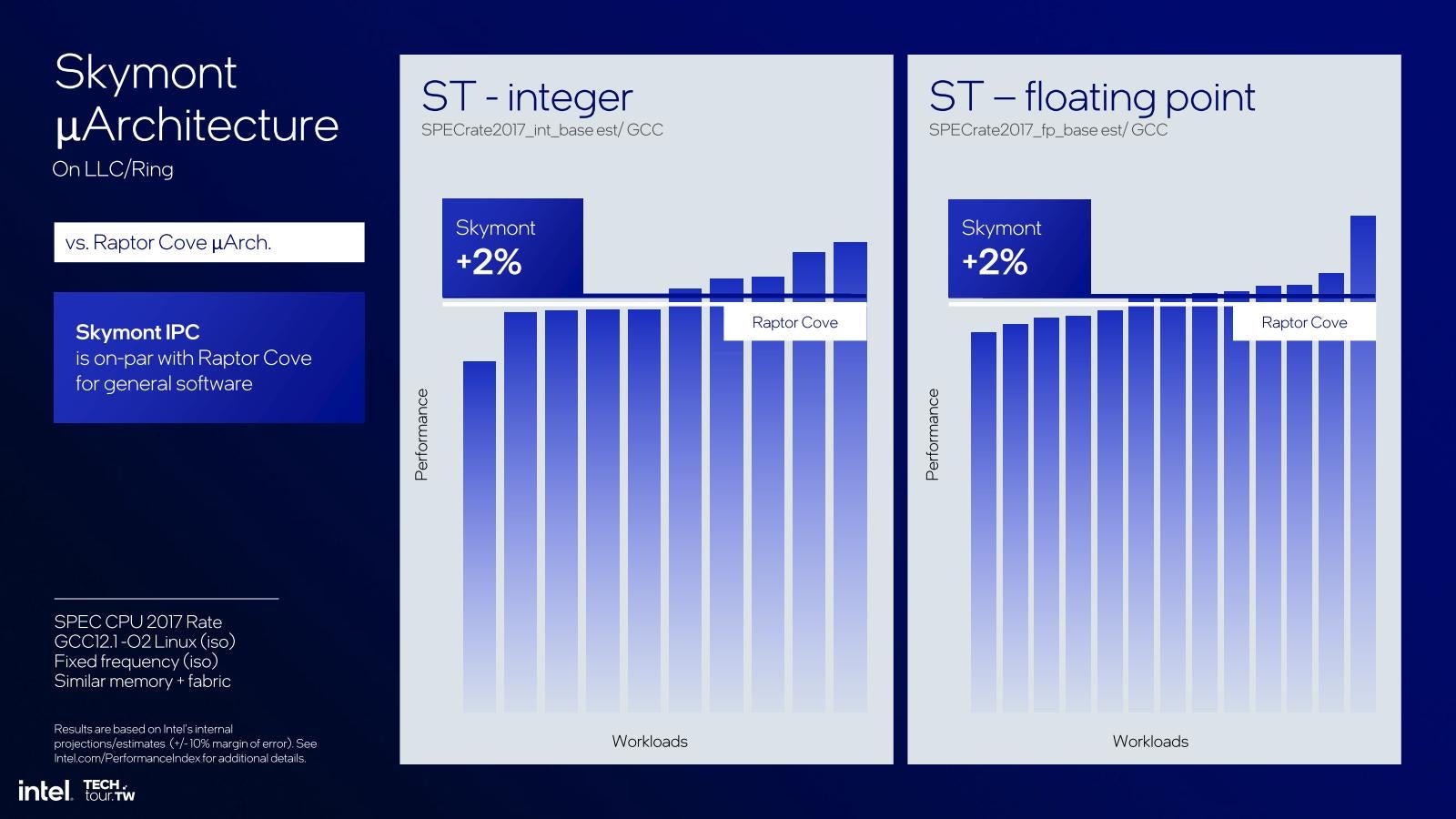
Photo29: だからといって、SkymontだけのDesktop CPUとか作ってもI/O性能とかが十分に出ない公算が高いので、ゲームとかには向いてないとは思うのだが。ただBusiness Desktop向けとかには良さそう。

-
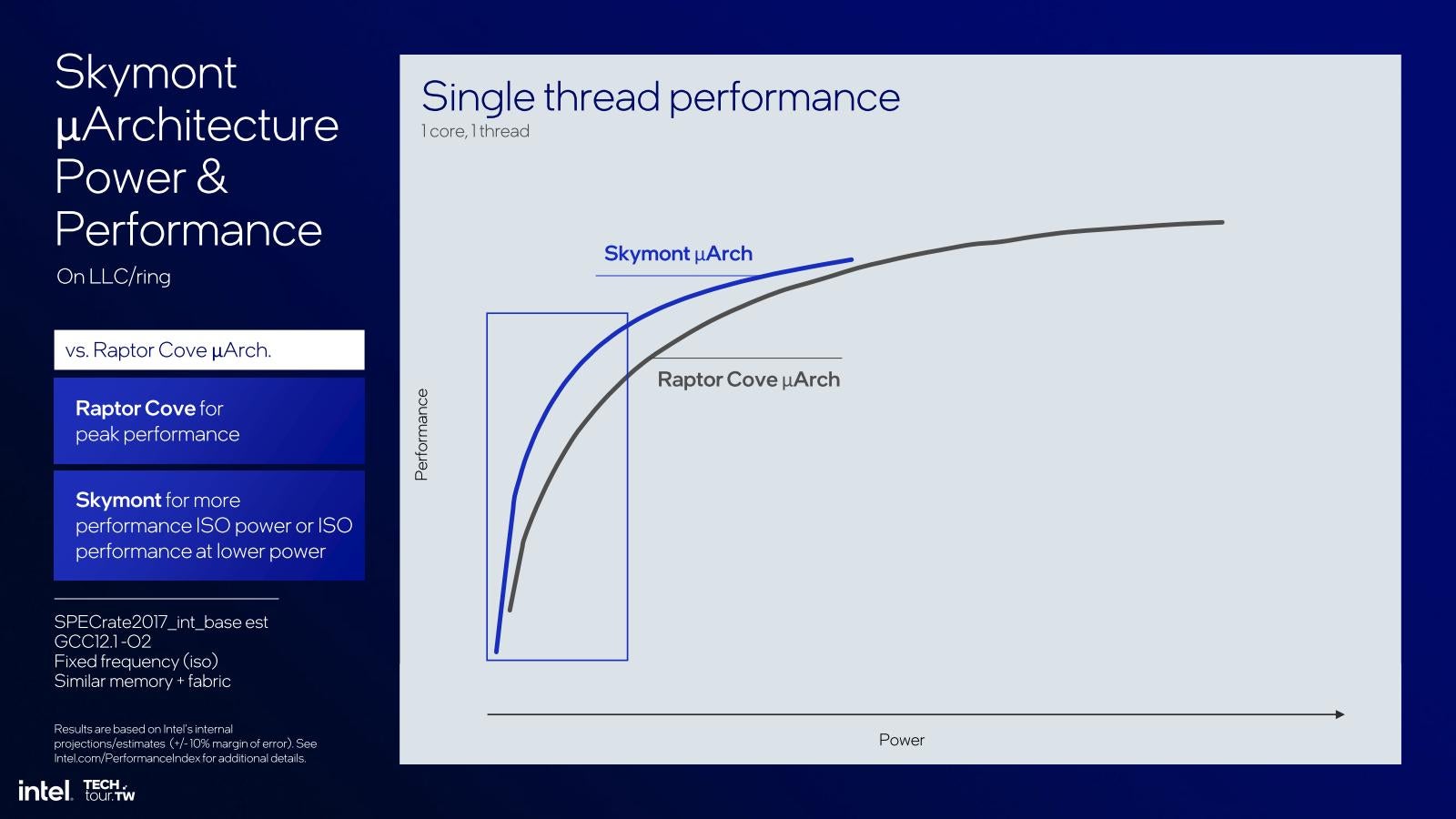
Photo30: もっともRaptor CoveをTSMC N3Bで作り直したらまた話が変わってくると思うので、そのあたりは考慮すべきだろう。

-
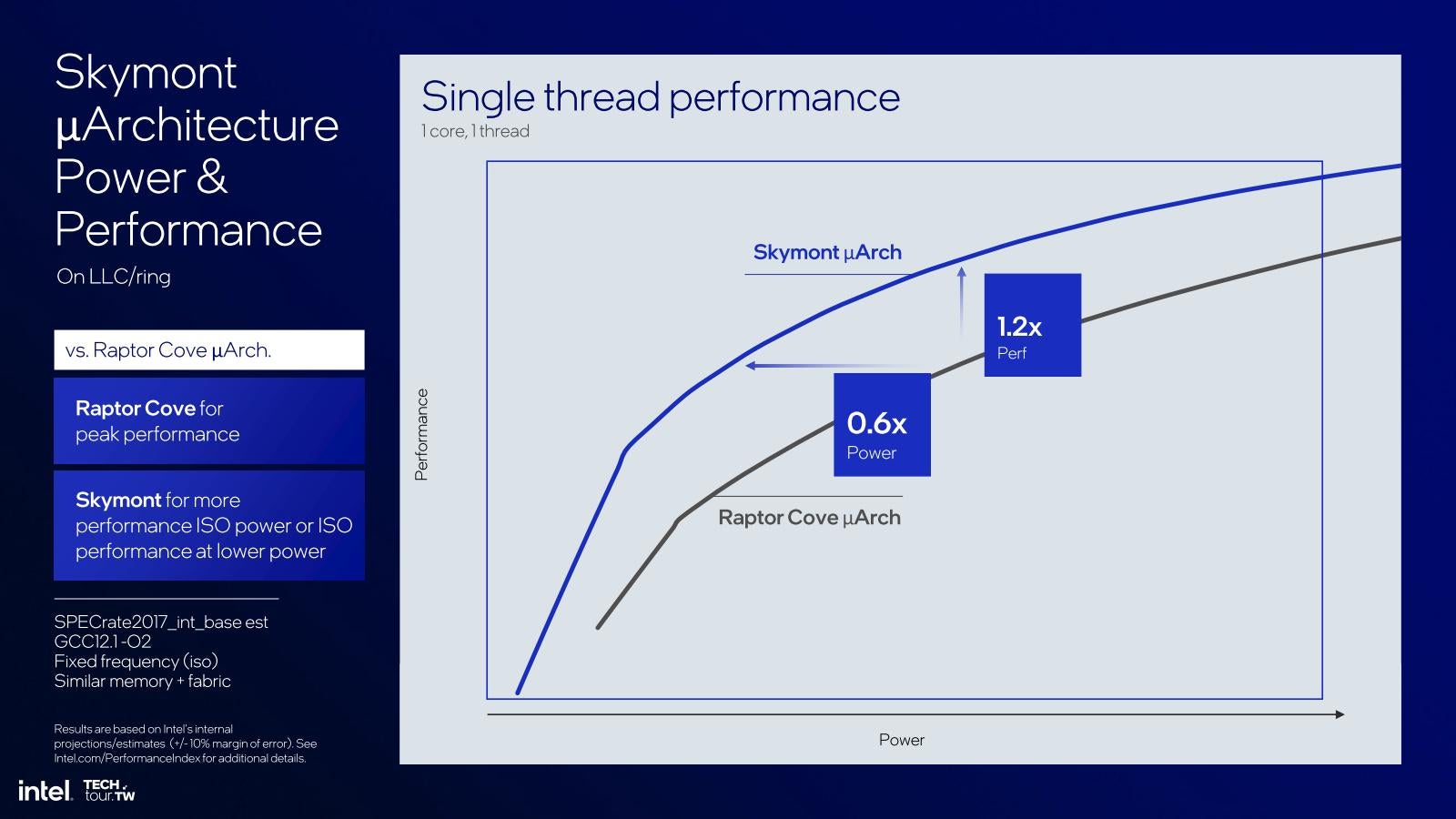
Photo31:

ちょっと長くなったのでNPUやGPU、システム全体のパッケージなどは別記事とさせていただきたい。









{kind=link}