



記者説明会では、VLSI Circuitsシンポジウムで発表される採択102件の論文の中から特に注目される発表論文13件の概要が紹介された。
5Gトランシーバ
5Gトランシーバ分野では、東京工業大学(東工大)の論文が注目論文に選ばれた。
5G中継用28GHz帯バッテリーレス無線機(論文番号 C11-1)
“A 28-GHz Phased-Array Relay Transceiver for 5G Network Using Vector-Summing Backscatter with 24-GHz Wireless Power and LO Transfer,” Michihiro Ide, et al., Tokyo Institute of Technology
5Gでは、従来より用いられてきた6GHz以下の低い周波数帯とあわせて、ミリ波帯を用いることが1つの特徴となっている。しかし、ミリ波は強い指向性を持ち、かつ伝搬距離も限られることから、基地局1台当たりでカバーできる通信範囲が狭くなるという問題があった。こうした課題を踏まえ、東工大は、中継基地局を多数配置することで5Gの通信範囲と通信容量を拡大するバッテリーレス中継無線機技術を発表する。24GHz帯無線電力伝送を併用することで、バッテリーレスで5G規格準拠の無線通信に成功したという。
-
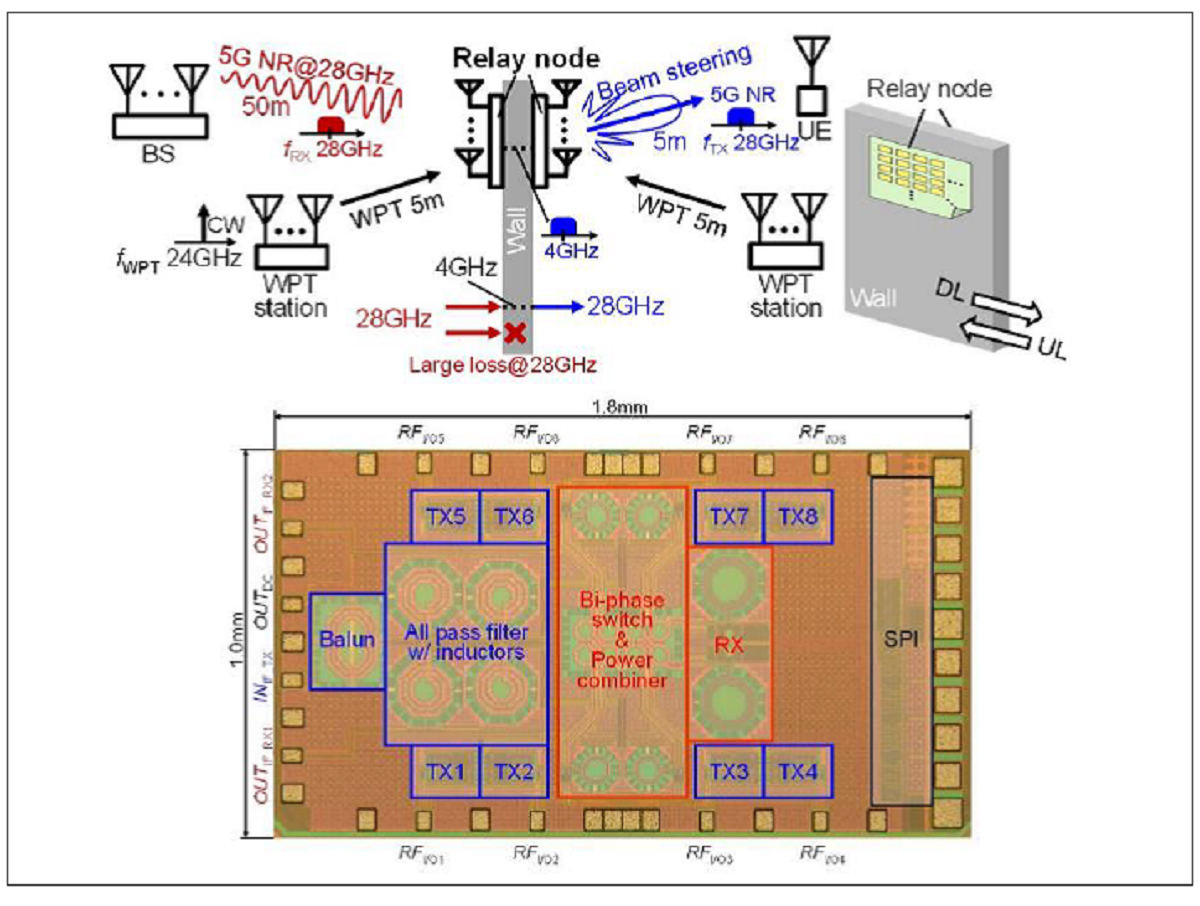
28GHz帯フェーズドアレイ中継無線機の概要とその半導体チップ写真 (出典:VLSIシンポジウム委員会)

フォトニクス
フォトニクス分野の注目論文には、Intelの論文が選ばれた
シリコンフォトニクスのマイクロリング変調器を用いた4 x 112Gb/s WDM対応の送信機(論文番号:JFS3-4)
“Silicon Photonic Micro-Ring Modulator-based 4 x 112 Gb/s O-band WDM Transmitter with Ring Photocurrent-based Thermal Control in 28nm CMOS,” Jahnavi Sharma, et al., Intel
Intelは、400Gイーサネットモジュール、およびCo-Packaged Optics に対応した4λ×112Gb/s/λの波長分割多重(WDM)送信機を報告する。
フォトニックIC(PIC)には、ヒータ付きのマイクロリング変調器(MRM)が実装されている。また、28nm CMOS電子IC(EIC)には、非線形FFEを備えたPAM4 MRM駆動回路と、プロセスや温度変動に対して、PICのヒータ温度をコントロールすることでMRM共振波長を安定化させ、高速なWDMの送信波形を実現する制御回路が実装されている。
また著者は、Oバンドにおけるリング変調器を用いたWDM送信機として、最高速であると主張しているという。
-
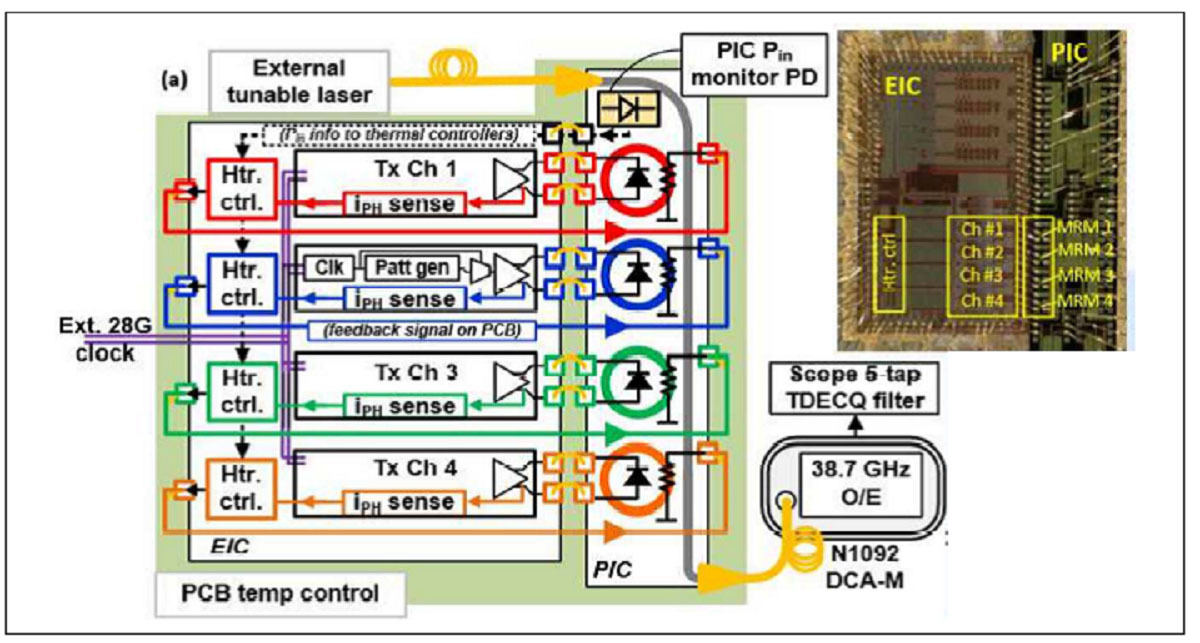
OバンドWDM対応シリコンフォトニック送信機の構成とチップ写真 (出典:VLSIシンポジウム委員会)

AI分野
AIおよびマシンラーニング分野では、米スタンフォード大学/TSMCとKAISTの2論文が注目論文に選ばれた。
マルチダイ・スケーラブル・プロセッサのRRAMを活用したエッジ用ディープ・ニューラル・ネットワーク・アクセラレータ(論文番号:CFS1-2)
“CHIMERA: A 0.92 TOPS, 2.2 TOPS/W Edge AI Accelerator with 2 MByte On-Chip Foundry Resistive RAM for Efficient Training and Inference,” Massimo Giordano, et al., Stanford University & TSMC
スタンフォード大とTSMCは、CHIMERAと名付けられたエッジAIアクセラレータを発表する。このアクセラレータは、推論とインクリメンタル学習をターゲットとしている。
CHIMERAは、不揮発性の抵抗性メモリ(RRAM)を統合し、その特性をチップ間リンクによるマルチダイ・スケーラブル・アプローチで利用している。著者らは、6つのチップ(C0〜C5)を接続することで、6倍の規模のDNNに推論をスケールアップしている。各チップは、それぞれの計算が終了すると電源を切る。重みメモリは不揮発性であるため、ウェイクアップは33μsと高速で、使用していないときは完全なパワーダウンが可能である。
また、重みの更新を最小限に抑えるトレーニングアルゴリズムを採用し、RRAMの耐久性、書き込みエネルギー、レイテンシといった課題にも取り組んでいる。このチップは、40nmプロセスで製造され、1チップあたり0.92TOPS、エネルギー効率2.2TOPS/Wを達成している。米国の大学と台湾のファウンドリが組んで、設計と製造の同時最適化を図っている点が注目される。
-

システムプリント基板の外観と半導体ダイ写真 (出典:VLSIシンポジウム委員会)

トレーニングを加速するエネルギー効率に優れた深層強化学習(DRL)プロセッサ(論文番号:CFS1-3)
“OmniDRL: A 29.3 TFLOPS/W Deep Reinforcement Learning Processor with Dual-mode Weight Compression and On-chip Sparse Weight Transposer,” Juhyoung Lee, et al., KAIST
韓国の国立大学KAISTの研究者らは、トレーニングタスクを高速化するために、高性能でエネルギー効率の高い深層強化学習(DRL)プロセッサ「OmniDRL」を発表する。
OmniDRL は、複数(24個)のグループ・スパース・トレーニング・コア(GSTC)を備えており、プルーニングとブロック・サーキュラント・ベースの重みグルーピングを利用することで、トレーニング速度を2倍に向上させた。
さらに、DRLでは、圧縮ネットワークインターフェース(CNI)に指数平均デルタエンコーディング(EMDE)を採用し、指数圧縮率の向上(1.6 倍)とメモリアクセス電力の削減(23.3%)を実現したほか、スパース・ウェイト・トランスポーザー(SWT)を搭載することで、圧縮された重みの転置をオンチップで行い、外部メモリへのアクセスを低減している。このプロセッサは28nm CMOSプロセスで製造され、ピーク時の性能は4.18TFLOPS、ピーク時のエネルギー効率は29.3TFLOPS/Wを達成している。
-
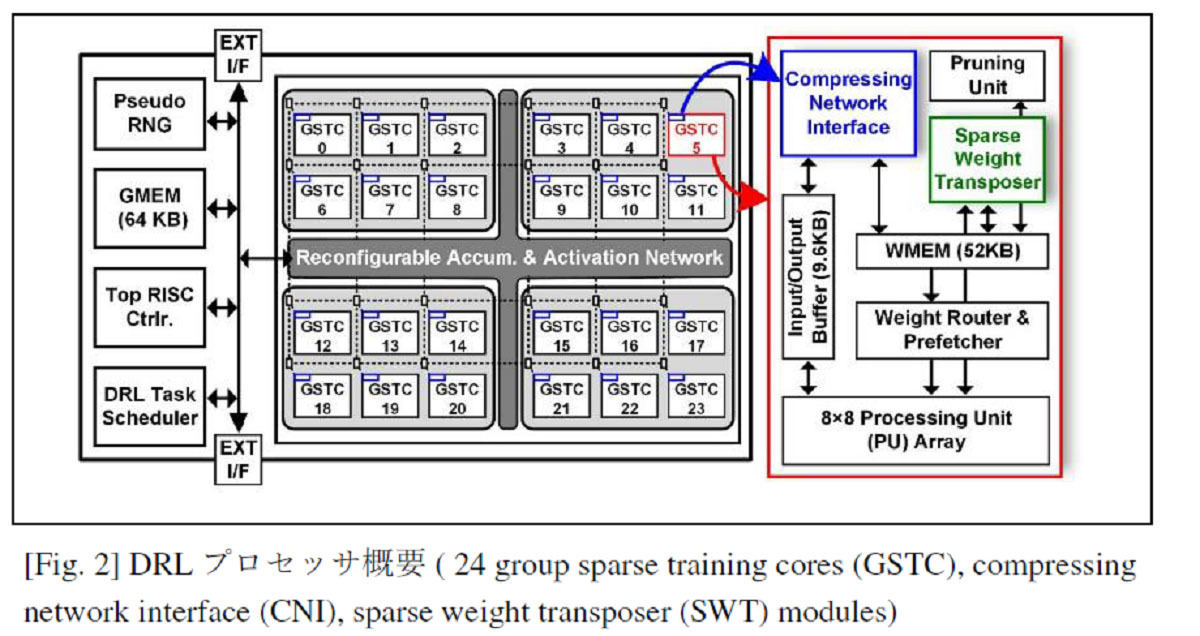
DRLプロセッサ概要 (出典:VLSIシンポジウム委員会)













