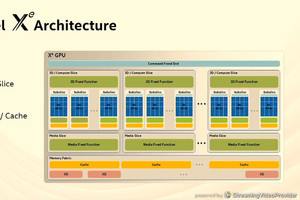
TPU v2では多数のTPUをインタコネクトで接続
TPU v1はシングルノードのアクセラレータであったが、大規模の学習を行うTPU v2では多数のノードを接続してマシンラーニングのスーパーコンピュータを作る必要がある。このためHBMとベクタメモリからインタコネクトを出して接続できるようにする。
これでTPU v2の計算エンジンができ上がりである。
-

さらに、ノード間を接続するインタコネクトを付け加えると、ジャーン!(英語ではTADA!)、TPU v2のノードのできあがり、となる

次の図は、TPU v2ノードの構成を、もう少し詳しく書いたものである。各コアにはスカラユニットが付いており、ベクタユニットには行列乗算ユニットとTranspose/Permuteユニットが接続されている。
そして、インタコネクトは2次元トーラスを使うので、インタコネクトルータからは4本のリンクが出ている。
-

TPU v2のもう少し詳しい図。各コアにはスカラユニットが含まれ、Transpose/Permuteユニットも含まれている。インタコネクトは2次元トーラスであるので、インタコネクトルータから4本のリンクが出ている

実はTPU v2のノードは次の図のように、インタコネクトルータを挟んで、Core0とCore1の2つのコアが存在する。TPU v2でもTPU v1のように2倍のサイズの1つのベクタユニットを作ることもできるが、大きなシストリックアレイにすると、演算レーテンシが長くなってしまう。このため、2つのベクタユニットがインタコネクトルータを共用する構造を採用した。発表スライドでは触れられていないが、TPU v1では8bit整数の積和演算器であるのに対して、TPU v2ではbfloat16の積和演算器となってサイズが大きくなったことがシストリックアレイのサイズを減らしたことに影響しているのではないかと思われる。
-

TPU v2のもう少し詳しいブロック図。256×256アレイのベクタユニットとすると演算レーテンシが長くなるため、TPU v2ではマトリクス乗算器は小さくして2つのコアがインタコネクトルータを共有する構造をとった

TPUコアはVLIWプロセサ
TPUコアは322bitという長い命令を使うVLIWアーキテクチャを使っている。VLIW用のコンパイラの作り方は、技術は確立しているので、それに基づいてコンパイラが作れるというメリットがある。そして、VLIWプロセサの命令はスカラ、ベクタ、マトリクスなどを変数として扱う線形代数を実行する命令となっている。
-

TPUコアは長い命令を使うVLIWアーキテクチャをとっている。命令で扱うデータはスカラ、ベクタ、マトリクスなどで、線形代数操作を行う命令を持たせている

TPUプロセサの命令は322bit長で、その中に2つのスカラ命令のスロット、4つのベクタ命令(ただし、2つはロード、ストア)のスロット、2つのマトリクス演算命令用のスロット、1つの雑用スロット、6つの直値のスロットが含まれている。
TPUコアの中のスカラユニットがVLIW命令をフェッチして、デコードを行う。また、スカラユニットはVLIW命令の中のスカラスロットの命令の実行も行う。
-

TPUの命令は322bitのVLIWである。その中に2つのスカラ命令、4つのベクタ命令、2つのマトリクス命令が記述できる

スカラユニットは2つのALUを持ち、4K×32bitのスカラメモリのデータを使ってスカラ演算を行う。そして、スカラユニットはSync Flagを保持し、デコードや命令のイシュー、レジスタファイルのアクセスなどを同期して行わせる機能を持っている。
-

スカラユニットは2つのALUを持つコンピュータで命令メモリから命令を読み出し、解釈して破線のように、各ブロックに指令を出して実行を行わせる

TPUコアのベクタユニットは、32bit幅で32エントリのベクタレジスタファイルと2つのALUを持つ。ただし、ベクタユニットはこのALUとレジスタファイルを8組持っている。この8組のセットをLaneと呼ぶ。
-

ベクタユニットは32bitの演算器を8組持ち、これがベクタ処理の1レーンになる。ベクタユニットは1レーンの双方向のデータパスでマトリクスユニットと接続されている

(次回は9月9日に掲載します)