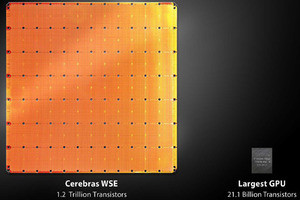
HuaweiのDaVinci
Huaweiはエッジ用からデータセンター用までを含むDaVinciシリーズを発表した。ここでは、データセンター用のDaVinci Maxを中心に紹介する。
-

HuaweiのDaVinciを発表するLiao Heng氏

HuaweiのDaVinciのブロックダイアグラムは次の図のようになっている。演算という点では4096個のFP16演算器を持つCUBEが中心で、さらに2048bitのINT8/FP16/FP32のベクタユニットを持っている。ベクタユニットは数値計算以外にアクティベーション関数の計算もできるようになっている。
-

HuaweiのDaVinciコアのブロックダイアグラム。4096個のFP16演算器を持つCUBE、2048bitのベクタ演算器を持つベクタユニットを持つ (出典:本連載のDaVinciの項のすべての図はHuaweiのLiao Heng氏の発表スライドのコピーである)

次の表に示すようにDaVinciシリーズは、データセンター用の「Davinci Max」から、「Davinci Lite」、「Davinci Tiny」とエッジデバイス用のものまでそろっている。
-

DaVinciはデータセンター用のMaxからスマートウォッチなど向けのTinyまで揃っている

大量の演算器を持つ場合、大量のスレッドを並列に走らせるGPUのようなアーキテクチャを使うアクセラレータも多いが、DaVinciではプログラムのしやすさという点で、シングルスレッドでC言語のようなプログラミングインタフェースで明示的に並列度をコントロールできるようなアーキテクチャになっている。
次の図のように、コントロールを行うスレッドは1本で、それが明示的にCubeキューやベクタキュー、MTEキューなどに仕事を突っ込んでそれらのパイプラインに仕事をやらせている。そして、依頼した仕事の終了は、バリアグローバルで確認する。
-

コントロールの基本はスカラパイプで、ここで実行するプログラムで明示的にCubeキュー、Vectorキュー、MTEキューなどに仕事を指示する。終了はバリアグローバルで確認する

m回まわるループを2スレッドで実行する場合は、次の図のようになり、スレッド1はループの奇数回目、スレッド2は偶数回目の実行を担当する。
-

2スレッドで実行する場合は、スレッド1はループの奇数回目を実行し、スレッド2は偶数回目を実行する

エッジ向けのAscend 310は、DaVinciコアは2個で、それ以外にPCIe3.0やギガビットEthernetなどのポートが出ている。
-

エッジ向けのAscend 310は、DaVinciコアは2個で、その他にUSB3.0、ギガビットEthernet、PCIe3.0などが出ており、他のデバイスを繋いでSoCが作れるようになっている

学習用のAscend 910 SoCは32個のDaVinciコアを集積し、4個のHBM2メモリを搭載し、それに加えて2本のDDR4インタフェースを装備して大容量のメモリをサポートできるようになっている。
さらにNimbus V3チップが付いており、DaVinciコアにネットワーク接続やx86/Armなどの他のシステムやFPGAなども接続できるようになっている。なお、制御用のCPUはTaishan MP4で4コアのArmアーキテクチャCPUを使っている。
-

学習用のシステムはDavinciコアを32個搭載し、Taishan MP4を制御用に使っている。メモリは4個のHBMと2チャネルのDDR4 DIMMが接続できる。また、Nimbus V3チップが接続されており、ネットワークや他のシステムと接続できるようになっている

次の表は各メモリやI/Oのバンド幅の一覧であるが、太い横線の上側のL1メモリまでは実行ユニットのバンド幅の1/10を確保しているが、L2メモリのバンド幅は1/100となっている。さらにHBMメモリでは1/2000、ノード内のバンド幅は1/40000.ノード間のバンド幅は1/200000と大容量のメモリのバンド幅とI/Oのバンド幅が性能向上の壁となっている。
なお、バッファやキャッシュがあればデータの再利用が発生するので、下の階層のメモリに必要なバンド幅は小さくなっていく。しかし、オレンジ色でハッチした欄は小さ過ぎで、性能ネックの原因になる。
-

各部が、512TOPSの実行ユニットの必要とするデータバンド幅の何倍のバンド幅を持っているかを示す表。L1メモリは1/10で十分なバンド幅を持っているがHBMやI/Oのバンド幅は小さく性能向上の壁になっている

さらに微細化の鈍化によるLogicの壁、電力の壁、熱の壁がある。これらの壁の制約を減らすために3D IC化が有効であるという。また、アーキテクチャの革新も進歩に貢献している。
-

メモリとインタフェースの壁に加えて、微細化のスローダウンによるロジックの壁、電力の壁、熱の壁がある。ICの3D化は、これらの壁を超える1つの方法。また、アーキテクチャの革新も重要な手段である

例えばAI SoCのダイの下に大容量のSRAMによるキャッシュを接続し、転送速度を向上し、さらに2個付けを可能にしたカスタムHBM2Eメモリを12スタック付ければ、HBM階層までのメモリの壁はかなり解消される。
-

AI SoCチップの下に3D SRAMキャッシュを付け、2個付けのできるカスタムHBM2Eメモリを12個付ければメモリの壁はかなり解消する

(次回は9月13日の掲載となります。)