



NNAは非常に大きいので、論理検証のためのシミュレーションはチャレンジであった。Verilator SimはCPUで動作する一般的なシミュレータと比べて30倍のスピードであった。エミュレータはVerilatorよりも3桁近く高速であった。さらにFPGAで作ったプロトタイプはVerilatorより4桁速く、役に立った。
-

アーキテクチャの決定からテープアウトまで14カ月しかなく、論理シミュレーションはチャレンジであった。特に規模の大きいNNAはチャレンジ。FPGAを使ったプロトタイプは高速であり役立った

NNAでの推論はConvolutionとDeconvolutionの計算量が大きく、合計すると99.7%が積和計算である。しかし、積和計算だけを数桁高速にすると、今度はQuantizationやPoolingの実行時間が見えて性能が制限されるということになってくる。したがって、積和計算に加えて、QuantizationやPoolingハードウェアの高速化も考えて置く必要がある。
-

Convolutionの計算量が98.1%、Deconvolutionの計算量が1.6%で、合計99.7%が積和計算である。しかし、積和計算だけを速くすると、ReLUやPoolingの時間が性能の制約になる

NNAでは入力データを上から、重みを左から供給して96×96のアレイでシストリックに計算を行う。データの再利用を増やし、SRAMやDRAMのアクセスを減らして、消費電力を抑えられるよう、計算順序やシフトを最適化している。ここで、掛け算は8bit整数で行い、その結果を30bit整数に加算している。
-

NNA内部の計算方法。データの再利用を増やし、SRAMやDRAMのアクセスを減らしている。さらに、データのシフトの電力も減らすようになっている

加算命令を命令キャッシュから読むと25pJのエネルギーが掛かり、それをレジスタファイルに加算すると6pJ掛かる。そして、命令の実行に伴うコントロールに39pJ掛かると、これで70pJ必要になってしまう。しかし、加算だけなら0.1pJで実行することができ、柔軟なステートマシンにコントロールをやらせ、DRAMやSRAMのアクセスが不要となるよう計算を行えば大幅に消費エネルギーを低減できる。
-

柔軟性のあるステートマシンで制御を行い電力を削減している。またDRAMのアクセスは無くし、SRAMのアクセスも最小にして電力消費を抑えている

命令セットも次の図のように簡素化し、命令はDMA Read、DMA Write、Convolution、Deconvolutionなど8種類しかない。性能をあげるため、Out-of-Order実行を行っているが、DMAアクセスと計算命令の実行の場合だけのOOOに制限している。
-
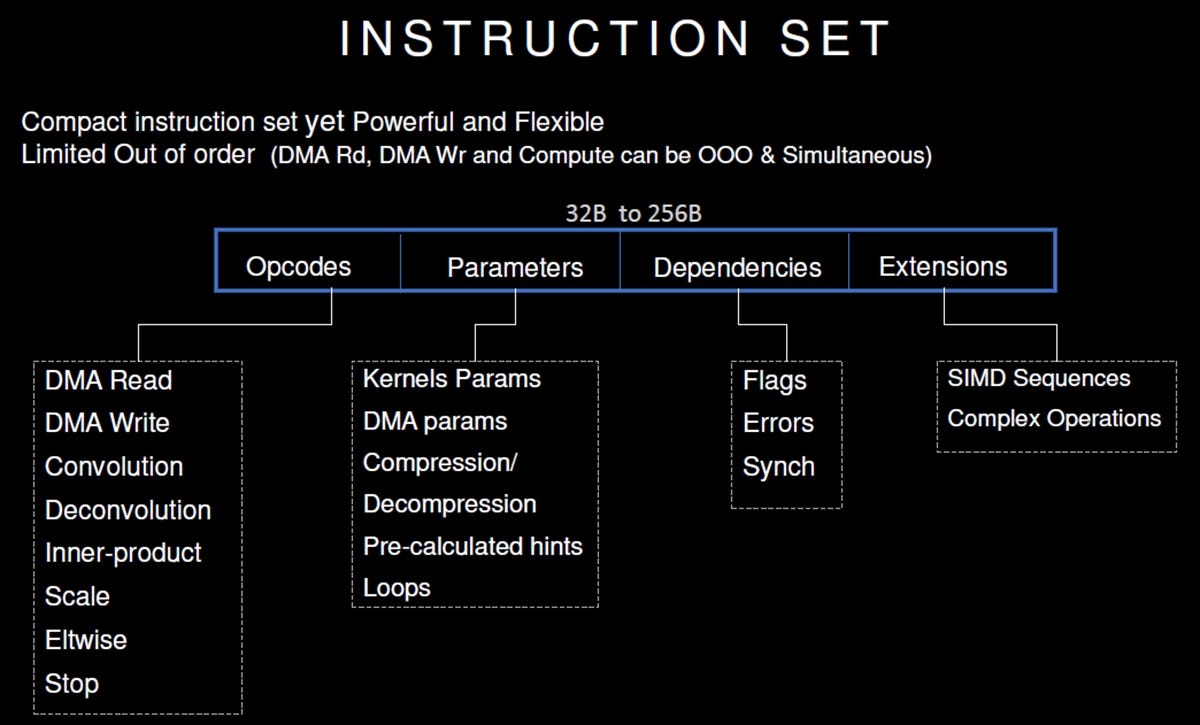
シーケンサで発行する命令は簡素で、命令の種別は8種に抑えられている。Out-of-Orderの実行はDMAの動作と演算命令の実行の場合だけ。しかし、十分な柔軟性がある

NNAのブロックダイヤグラムは、次の図のようになっている。左側が命令処理部で、右側がデータ処理部である。データはSRAMバンクから供給され、重みもSRAMに格納されているが重みバッファを持ち、再利用を増やしている。96×96の積和アレイで演算を行い、一群の処理が終わるとDeconvolutionやPooling処理を行い、バッファでSRAMの幅に合わせて書き戻しを行う。
重みはすべてSRAMに入っている設計で、重み専用のシーケンサで、次にアクセスするSRAMアドレスを決めている。
-

左半分は命令の制御部分で、右半分が演算部分である。演算部は96×96の積和演算器を囲んで上から入力データ、左から重みを供給している。積和演算器の下にプーリングの演算器などがある

前の図でSIMD Lanesと書かれている部分は、入り口に32bitのレジスタファイルがあり、それに3つの演算器が繋がっている。右端の演算器は浮動小数点、中央の演算器は8b/16b/32bの整数演算器で、左端の演算器は層ごとの正規化やReLUなどの処理を行うブロックである。
-

SIMD Lanesの部分の中身のブロックダイヤグラム。右から浮動小数点演算器、中央が8b/16b/32bの整数演算器、左端は層ごとの正規化やReLU処理などの演算器である

Poolingは局所的な特徴を纏めて縮小して画像処理を行うもので、入力の小領域(2×2や3×3)を、その中の最大値で代表させるMax Poolingや平均値で代表させるAverage Poolingなどが代表的なものである。ブロック図の3つの長方形の左端の箱がPoolingする小領域のArrayを取り出す部分、2番目が 96個の小領域それぞれのプール値を求める部分で、MaxとAverageがサポートされている。Averageの場合は小領域の全部のピクセル値の合計を出して、領域のサイズで割って平均値を出す必要があるので、この処理を96ピクセル分並列に実行する部分となっている。
-

プーリングは小領域の全ピクセルをその領域の中の最大値のピクセルや全体の平均値にする処理で、それを96ピクセルを並列に実行するハードウェアを持っている

性能であるがHW2.5というのが、現在の車に搭載されているもので、今回発表のFSDはHW3.0と書かれている場合もある。性能の比較であるが、FSDはHW2.5の21倍の性能になっているとのことである。しかし、何が改善されて21倍の性能になっているかの説明は無かった。
-
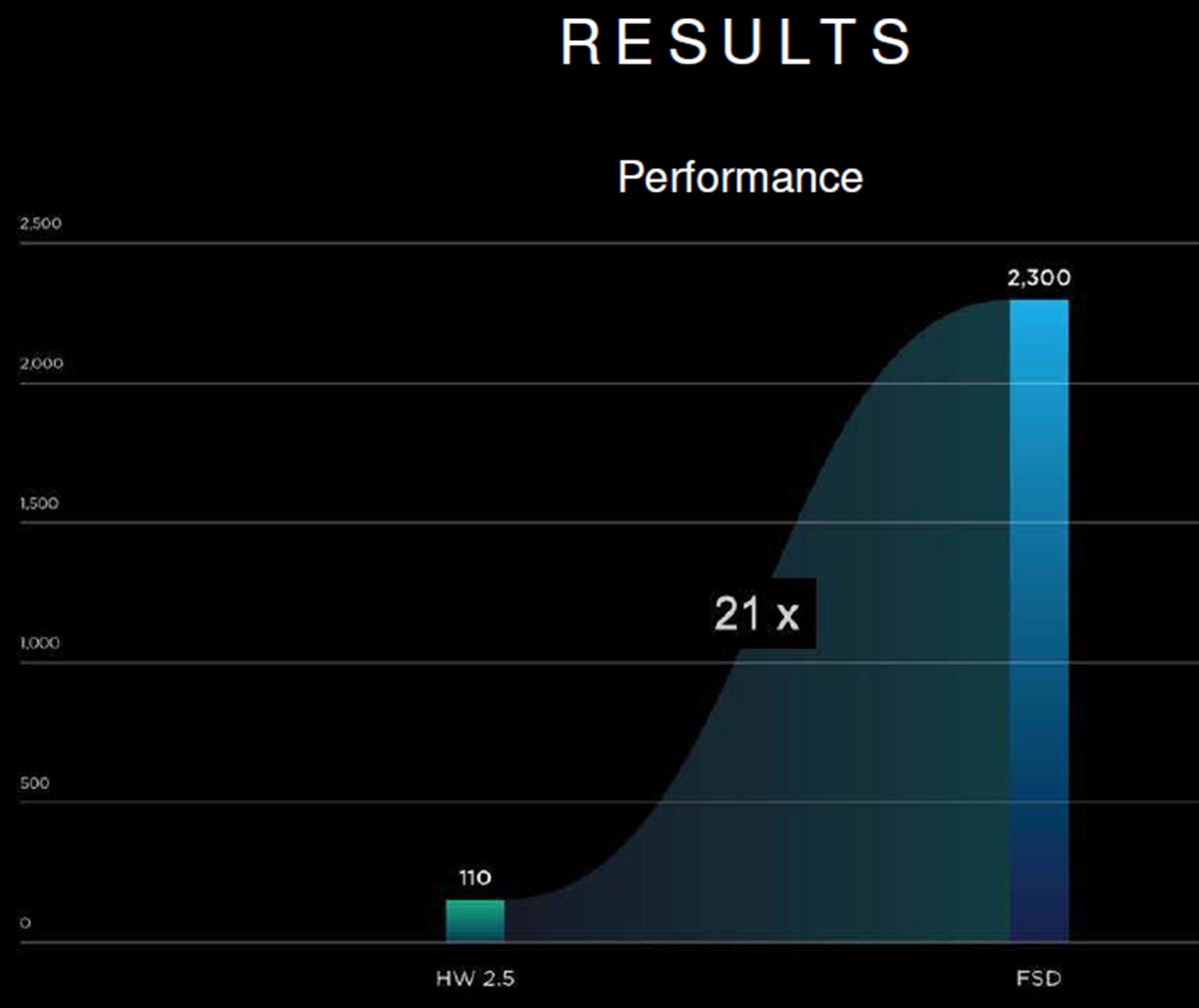
現在の車に搭載しているHW2.5と比較すると21倍の性能。何が改善されたかは明らかにされなかった

消費電力では、HW2.5が57Wであったのに対して、FSDは72Wに増加している。しかし、性能が21倍であるからエネルギー効率としては約17倍の改善である。また、NNAの部分だけの消費電力は15Wとなっている。
-

消費電力はHW2.5に比べると1.25倍に増えている。FSD全体は72Wであるが、NNA単体では15Wである

そして、FSDのコストはHW2.5の0.8倍とのことである。2チップを使って冗長化すると、FSDのコストは1.6になってしまうが、安全のためにはやむを得ないところであろう。
-

コストはHW2.5の0.8倍に低減している

まとめであるが、FSDはゼロベースで設計し、完全な最適化を行ったSoCである。FSDは、素晴らしい性能/電力値を達成した。そして、最適なコストで完全な冗長性を追加できる設計になっている。
結果として、FSDコンピュータは安全性と将来の自律運転を可能にしている。そして、この製品は将来のものではなく、今日にも購入できるものであると結んだ。
-

FSDは完全新設計で、高い性能/電力を実現した。そして、最適なコストで完全な冗長構成が実現できる。このFSDは、将来の製品ではなく、今日、購入できるものである

発表の題名であるFull Self Driving Computerの名前に沿う自動運転ができるかどうかが知りたいところであるが、Ganesh Venkataramanan氏は、チップについては詳しく述べたが、ソフトウェア込みの運転の質についてはまったく触れられなかった。
(次回は9月27日に掲載します)












