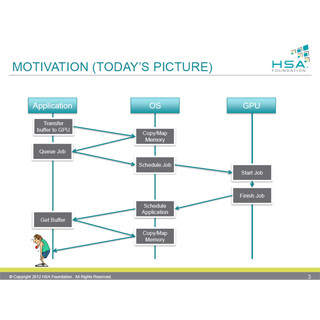
HSAキューイングモデル
最初に書いたように、現状では、CPUとGPUのメモリが別々であるので、データのコピーが必要である。また、GPUに処理を依頼するにはOSを経由する必要があり、時間が掛かる。
これに対して、HSAではCPUとGPUに共通の仮想メモリ空間を造り、一部のページはCPUメモリ、一部のページはGPUメモリにマッピングされるという構造を実現する。

|
|
HSAでは、CPUとGPUは1つの仮想メモリ空間を共用する |
どちらも同じ仮想メモリ空間を共用するので、CPUが書き込んだデータをGPUが読んだり、その逆も可能であり、GPUに仕事を依頼するときに、データをGPUメモリにコピーする必要がなくなる。また、CPUとGPUのキャッシュコヒーレンシが確保できれば、CPU側のメモリに連続域のバッファを確保しなくても、キャッシュを使って相手方のメモリを効率よくアクセスできるようになる。

|
|
共通の仮想アドレス空間とキャッシュコヒーレンシをサポートすれば、CPUメモリのバッファ確保とCPUメモリとGPUメモリ間のデータのコピーが不要になる |
これでデータの受け渡しの4つのステップが不要になる。
これに加えてHSAではGPUに処理を依頼するパケットの形式を決め、OSのサービスを使わず、ユーザモードでGPUのジョブキューに依頼パケットを書き込むメカニズムをサポートする。なお、キューの生成、破棄はHSAランタイムの呼び出しで行うことができるようになっている。

|
|
HSAランタイムを呼び出して共通メモリ上にキューを作り、HSAで決められたプロトコルに従って、ユーザモードプログラムがキューにパケットを入れる |
処理を依頼するディスパッチパケットの形式は次の図のように決められている。

|
|
Dispatchパケットのフォーマット |
ディスパッチパケットの最初の4バイトは待ち合わせの条件などを指定しており、それに続いて、ワークグループのX、Y、Z方向の大きさ、グリッドのX、Y、Z方向の大きさ、セグメントのサイズ、実行するハードウェア命令のアドレス、完了を知らせるシグナルオブジェクトのアドレスなどが書かれている。
パケットの処理開始はインオーダで、キューに入れられた順に処理が開始される。しかし、パケットのバリアビットが立っている場合は、それ以前にキューに入れられたすべてのパケットの実行が終わらないと、そのパケットの処理を開始しない。
また、詳細は略すが、パケット間の依存性がある場合に、待ち合わせを行うバリアパケットがある。バリアパケットは指定した条件が満足されるまで実行を完了せず、条件として指定した一群のパケットの終了を待ち合わせることができる。

|
|
FFTを、各段を2つのパケットとし、段の間にバリアを入れて実行する |
この図はFFT(高速フーリエ変換)処理のパケットへの分割とデータの流れを示している。
次の図は、FFTの処理の状況を示しており、まず、パケット1が発行されて実行に移る。そしてパケット1の発行が終わると、パケット2が発行されて実行が開始され、パケット1と2は並列に処理が行われる。
しかし、パケット3との間にはバリアがあり、パケット3の発行はパケット2が完了するまで待たされる。結果として、パケット3の実行は、パケット2が完了しその結果が使用できるようになるのを待ち合わせる。

|
|
パケット1と2は順次開始され、並列に実行されるが、バリアがあるので、パケット3の実行は、パケット2の完了を待ち合わせる |
このように、HSAでは、ユーザモードで書き込めるキューの作成メカニズム、キューへの書き込みプロトコル、キューに入れるパケットの形式を決めており、アプリケーションから、OSの介在なしにGPUに処理を依頼し、処理結果を受け取ることができるようになる。結果として、中間のバッファの確保、データのコピーや、OP経由のGPU起動などのステップをすべて省くことができ、最低限のステップでGPUに処理を割り振ることができるようになる。
|
|
|
HSAでは中間のステップをすべて省いて、効率よくGPUに処理を依頼できる |
このように、HSAでは、単一の仮想メモリアドレス空間とキャッシュコヒーレンシのサポート、並列処理を効率的に行えるメモリモデルとユーザモードキューイングをサポートすることによって、 GPUと処理分担が効率よく行えるようになる。