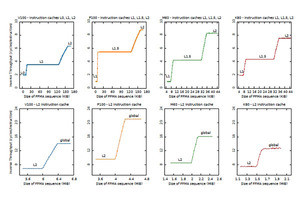
データキャッシュのバンド幅
L1Dキャッシュから各スレッドができるだけ多くのキャッシュラインを読みだせるコードを実行させてL1Dキャッシュのバンド幅を測定した。その結果が下の表で、上の行が実測したバンド幅、下の行は理論ピークのバンド幅である。これを見るとM60やK80は理論ピークのバンド幅は128バイト/サイクルと大きいが、実際に読めたのはM60では15.7B、K80でも68.6Bであった。これに比べると、V100は128Bのピークに対して108.3B、T4は64Bのピークに対して58.8Bがアクセスできている。
T4とP4は位置づけが似ているGPUであるが、L1Dキャッシュの実行バンド幅という点ではP4は15.7B/Cycleであったのに、T4は58.8B/Cycleとほぼ4倍のバンド幅に改善されている。
-
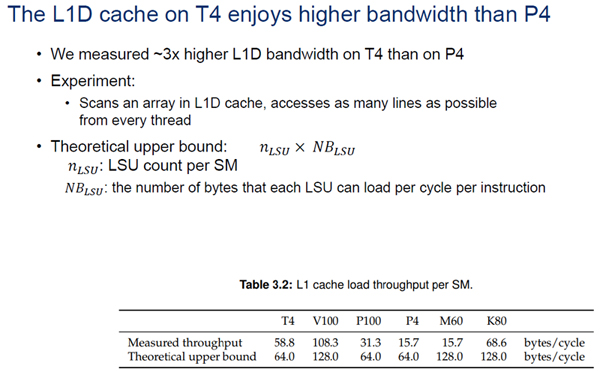
L1Dキャッシュのメモリバンド幅の測定。V100、T4は理論ピークのバンド幅に比べて、実際にアクセスできるバンド幅が大きい。P4と比べるとT4のL1Dキャッシュのバンド幅は4倍に近い

L2キャッシュはデータも命令も格納するユニファイドキT4の場合は16wayのセットアソシアティブキャッシュになっている。T4のL2キャッシュのバンド幅は実測で1270GB/sで、これはP4の実測の979GB/sの約1.3倍の値である。
-

ユニファイドキャッシュのL2キャッシュのバンド幅。P4と比べてT4のL2キャッシュのバンド幅は約1.3倍になっている

グローバルメモリのバンド幅
次の図は各GPUのグローバルメモリのバンド幅を測定した結果である。灰色の棒グラフが理論ピーク値で、青の棒グラフが実測値である。
やはり、メモリにHBM2を使っているP100とV100が高いバンド幅を示している。T4とP4の比較でみると、GDDR6メモリを使っているT4の方がグローバルメモリの実測バンド幅は大きいが、理論ピークと実測の比率はP4の方が高い値を示している。
-
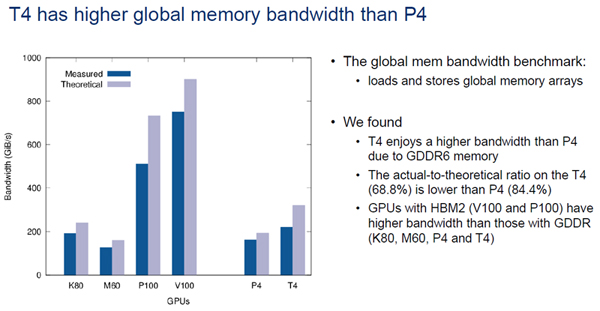
各GPUのグローバルメモリの理論ピークバンド幅と実測バンド幅。HBM2を使っているP100、V100は高いバンド幅を示している

T4 GPUの行列乗算性能
T4の演算性能をcuBLAS 10.1とCUTLASS 1.2 GEMM(マトリクスの乗算)で測定した。半精度、単精度、倍精度ともにスループットではcuBLASの方がCUTLASSより性能が高かった。しかし、int8での計算ではCUTLASSの方が精度が高かった。また、int4、int1をサポートしているのはCUTLASSだけでcuBLASはサポートしていない。
Gemm性能のグラフで、上に灰色の水平の線があるが、これは理論ピーク性能を示す線である。倍精度の計算(右下のグラフ)では、2048から4096程度の行列サイズでは、ほぼ理論ピークの性能が得られている。しかし、それ以外の精度の計算では、どの計算でもピーク演算性能より低い性能しか得られず、一般に精度が低くなると理論ピークからの低下が大きくなる傾向があるように見える。やはり、ハードウェアが倍精度、単精度に最適化されており、より低精度の計算にはオーバヘッドがあるのではないかと思われる。
-
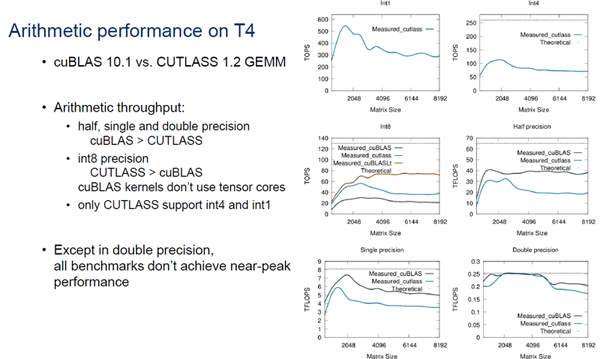
cuBLASとCUTLASSでの行列乗算性能の測定。Int1以外のグラフでは灰色の水平線が理論ピークを示す。倍精度の計算ではこのピーク値に近い性能が出ているが、それ以外の精度では理論ピークよりかなり低い値しか得られていない

T4とP4は、CUDAコアの数、最大グラフィックコア周波数などはほぼ同じである。演算性能でを比べると、単精度、倍精度の演算性能もほぼ同じである。しかし、次の表に示すように、Tensorコアのハードの強化で半精度浮動小数点とint8での計算はP4の6.3倍の性能となっている。また、int4とint1でもT4は素晴らしい性能を出している。
-
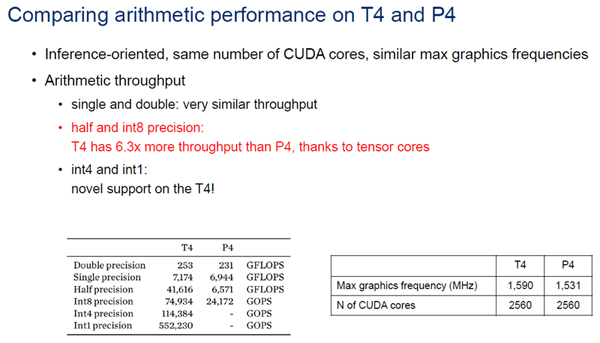
倍精度、単精度ではT4とP4は大差ないが、Tensorコアの改良で、T4の半精度とint8の性能はP4の6.3倍になった。また、int4とint1でも高い性能を出している

T4 GPUのパワースロットリング
次の図で赤線で示したGPUチップの温度が85℃を超えそうになると、T4は青線のクロック周波数を下げて過熱を防ぐ。安全性の観点では必須の機能であるが、このクロック低減に引っかかるとGPUの性能が低下してしまう。
-
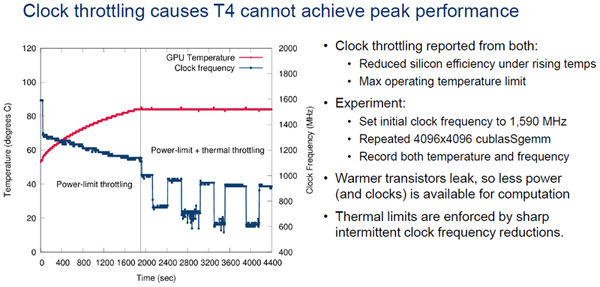
T4のクロックを1590MHzとして4096×4096のcublasSgemmを繰り返して実行すると、チップ温度が85℃を超えてクロックが低下させられる

次の図の上側の青い折線がクロック周波数、下側の緑の折線がcuBlas性能である。アレイのサイズを増やしていくとスロットリングが増えて実効クロックが下がる傾向にある。しかし、cuBlas性能はクロックには比例せず、あまり下がらない。
マトリクス乗算計算の性質として、アレイサイズが大きくなるとメモリアクセスに比べて演算の比率が増加して、cuBlas性能は上がる。この効果とアレイサイズが大きくなるとクロックが低下するという傾向が重なって、演算性能は次のグラフの緑の折れ線のような複雑な変化を示すのではないかと思われる。
-

アレイサイズを変えてcuBlas性能と、クロック周波数を測定。アレイを大きくするとクロックは下がる傾向にある。しかし、cuBlas性能はあまり下がっていない

次の図の縦軸はクロック周波数を消費電力で割った値を使い、横軸は時間(秒)である。T4とP4では動作開始の直後に温度制限に引っかかってクロックが下がるが、それ以外のGPUでは電力スロットルでクロックが下がるという現象はほとんど起こらない。
元々、P4とT4は70~75Wと電力が小さく、チップも小さいので温度が上がり易いと思われる。
-

縦軸は消費電力あたりのクロック周波数になっている。T4(水色)とP4(茶色)は電源投入直後にクロックが下がっているが、他のGPUではパワースロットルはほとんど起こらない

このCitadelの論文でT4 GPUのレイトレーシングコア以外の動作はかなり詳しく理解できる。もちろん、Citadelのサーバのソフトウェアをチューニングして性能を上げることが目的であるが、その過程で分かったGPUアーキテクチャを公表してくれるのはとても有難いことである。