


本連載はHisa Ando氏による連載「コンピュータアーキテクチャ」の初掲載(2005年9月20日掲載)から第72回(2007年3月31日掲載)までの原稿を再掲載したものとなります。第73回以降、最新のものにつきましては、コチラにて、ご確認ください。
キャッシュって何だろう?
性能の観点でCPUの仕様を見るとき、コア数、クロック周波数の次に来るのがキャッシュの容量というのが一般的であるが、キャッシュとはどういうもので、どう動くのかについてはあまり理解されていないように思われる。そこでこの一連の連載ではキャッシュについて述べようと思う。
プロセサのクロックが16MHz(GHzでは無い!)程度であった1980年代半ばまではDRAMメモリのアクセス時間も5サイクル程度であり、データをDRAMまで取りに行くことは大した問題では無かった。しかし、プロセサのクロックが1GHzを超えると、プロセサのクロック周期は1ns以下であるのに対して、DRAMのアクセスは1CPUの小規模システムでも50~80ns程度であり、100CPUサイクルのオーダで待ち時間が発生することになった。これではプロセサコアはメモリにデータを取りに行く時間、遊んでいるばかりで、処理を行う時間は僅かになってしまい性能が出ないことになってしまう。
この問題の解決のために考えだされたのがキャッシュという構造である。キャッシュは日本語では現金を意味するCashと同じ発音であるが、プロセサのキャッシュはCacheで、盗品あるいは貴重品の貯蔵所というような意味である。本来、メモリにあるデータを盗んで来てキャッシュに蓄えているわけであり、盗品の隠し場所は言いえて妙である。
言葉の遊びはともかく、遅いメモリまでデータを取りに行かなくても良いように、小さな貯蔵所をCPUの近くに設けることにより高速化するというのがキャッシュの考え方である。昔々、メモリが小さくプログラム全体がメモリに入りきらない頃、ディスクから必要な部分だけをメモリに持ってきたオーバレイも同じようなアイデアであるが、オーバレイはソフトが意識してメモリとディスクの入れ替えを行ったのに対して、キャッシュはソフトには見えない形でその内容を管理する点が大きく異なっている。
キャッシュは物理的にはCPUの近傍に大容量DRAMより高速のメモリを設け、頻繁に使用されるデータをそこに入れておけば、遅いDRAMへデータアクセスする頻度が減少し、メモリアクセスのオーバーヘッドが減少するというアイデアであり、メインフレームでは1968年に登場したIBM S/360 Model85から使われているメカニズムである。
キャッシュは、メモリの一部の頻繁に使われるデータを格納する高速の小規模メモリであるが、どのようにして頻繁に使われるデータかを判定し、どのようにデータを格納するかなどで多くのバリエーションがある。また、1CPUだけのシステムでは問題が無いが、複数のCPUがそれぞれにキャッシュを持つ場合には、それらのキャッシュの間の整合をとるコヒーレンス処理が問題となるが、これらについて順に述べていくことにしたい。
どういう単位でキャッシュに入れるのか?
キャッシュを作る時、まず考えるのがキャッシュに格納する単位データの大きさで、この単位データをキャッシュライン、その大きさをキャッシュラインサイズ、あるいは単にラインサイズと呼ぶ。ラインサイズを大きくするとメモリとの転送の回数が減り、その点では効率的であるが、折角メモリから持ってきても使われない部分が増加し、キャッシュメモリの利用効率が悪くなるという問題がある。また、一定量のキャッシュメモリを考えると、ラインサイズを大きくするとキャッシュに格納できるライン数が逆比例で減ってしまう。メモリの領域を連続してアクセスするような場合はともかく、あちこちの番地を参照する場合は、ライン数が減ると目的のデータがキャッシュに無い(キャッシュミス)ケースが増えてしまう。一方、ラインサイズを小さくすると、これらの逆で、利用効率はキャッシュヒット率の点では有利であるが、メモリからの転送回数が増える、後で述べるように管理のためのオーバーヘッドのハードウェアが増えるという問題がある。
これらのトレードオフから、32バイトから256バイト程度のラインサイズが用いられるのが一般的である。また、搭載できるメモリ量が増加するとラインサイズを増やしても格納できるライン数を維持できるため、半導体の微細化により搭載できるメモリ量が増加するに連れて、ラインサイズは増加する傾向にある。最近では2次キャッシュ、3次キャッシュをもつプロセサが普通であるが、容量の大きな2次、3次キャッシュでは、1次キャッシュよりも大きなラインサイズが用いられることが多い。
最近ではデュアルコアのプロセサが増え、2つのコアで1つの2次キャッシュを共用する構成のCPUチップも一般化してきた。それぞれのプロセサコアで動くプログラムが使うメモリ領域はメモリ上では連続アドレスのブロックになっているが、図1に示すように、キャッシュに格納される時には、ラインサイズの単位でバラバラな場所に格納されうる。
-
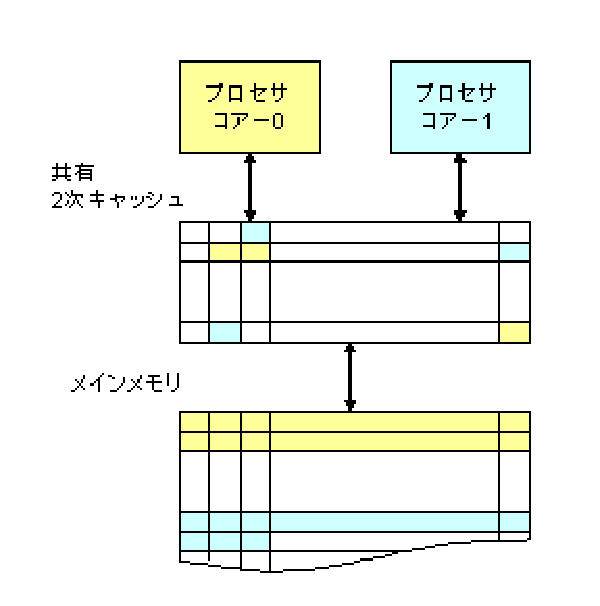
図1 マルチコア共有キャッシュ

一般的な共有2次キャッシュでは、プロセサ毎にキャッシュ内で使える場所は決まっておらず、一方があちこちのメモリアドレスをアクセスし、他方はあまりメモリを使わない処理であると、前者はキャッシュを多く使い、後者はあまりキャッシュ領域を必要としないという、うまい組み合わせになる。また、キャッシュの各ラインにはどのプロセサがそのデータをキャッシュに読み込んだのかを示す情報は無く、プロセサコア-0が読み込んだデータをプロセサコア-1が使うことやその逆も可能であり、両方のプロセサで同一の命令コードを使う場合や、同じデータを参照する場合などは、一つのコピーを両者で利用できるので効率的である。
各プロセサから共有キャッシュにアクセスする構成では、共有キャッシュはプロセサコアごとにアクセス要求を受け付けるFIFO(First In First Out)のキューを持ち、公平な順番(2プロセサの場合は、交互)でキューに溜まった要求を処理するとか、キューに溜まっている要求の待ち行列が長いほうを優先して処理するなどの方法が採られる。













