SoCというアプローチは最大限のエネルギー効率を提供してくれるが、システムアーキテクトはCMOSプラットフォーム内に多数の複雑な機能を集積することを余儀なくされた。
2000年代に誕生したマルチコアアーキテクチャの最適化により、初期のCPUからGPUへの分割、さまざまな電力最適化プロセッサ、さらにはさまざまな種類のアクセラレータに至るまで、コンピューティングエンジンの多様性が高まったほか、SoC内のメモリサブシステムも長年にわたって多様化し、複雑な階層とさまざまなアクセス メカニズムが生まれている。
この継続的な最適化の原動力は、コンピューティングシステムを、実行する必要があるタスクまたはワークロードの種類に合わせて最適化する必要性である。タスクまたはワークロードはそれぞれ、ターゲットアプリケーションに非常に固有である。このような進化が単一のテクノロジプラットフォーム内で可能になったことは非常に注目に値するが、現状では、いくつかの重要な障害がさらなる進化を妨げている。例えば、以下のような問題がある。
- マイクロバンプのピッチスケーリングとハイブリッドボンディングによって推進されるチップ間の電気相互接続の進歩によって、細分化されたSoC機能の分割が可能になる。また、Siフォトニクスベースの光相互接続と3D相互接続の進歩により、コパッケージングが可能になり、はるかに短いスケールで高帯域幅、低電力の光接続が実現できることから、SoCというアプローチが依然としてエネルギー効率の利点を保持しているかどうかという疑問が生じる。複数のダイに分割することが、コストとパフォーマンスの最適化に大きなメリットをもたらす可能性がある。
- アプリケーションの多様性により、コンピューティングパフォーマンスの限界を押し上げる高度なテクノロジが求められ、CMOSが一般的なプラットフォームとして提供できる機能の限界に達しつつある。設計者は、単一プラットフォームの制約を回避する必要があり、これが大きな非効率につながることもある。
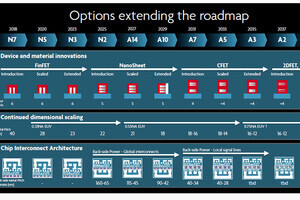
- CMOSプラットフォーム全体にわたる総合的なスケーリングソリューションの実現は、ますます困難になっている。例えば2nmのナノシートテクノロジでは、従来の厚膜I/O回路がSoCから排除される。SRAMはロジックほど拡張できず、フロントサイドの相互接続抵抗が法外に大きくなるため、SoC内の電力はバックサイドの相互接続ネットワークを通じて分配する必要がある。
- CMOSのノード間のパフォーマンス向上も、トランジスタのRC寄生が駆動力よりも速く増加したために大幅に減少した。これは、設計ルールとプロセス統合の複雑さにより、高度なCMOSの設計とウェハのコストが大幅に増加した時期に発生している。
汎用技術の強みを発揮できなくなってきたCMOS
技術と製品のニーズが変化する現在の状況において、創造的な組み合わせが革新的なソリューションにつながることが示されつつある。例えばApple M1 Ultraは、基本的にシリコンブリッジを介して2つのチップをつなぎ合わせることで、前例のないパフォーマンスと機能を備えたハイブリッドSoCを実現した1)。また、AMDは、元のプロセッサSoCの上にSRAMダイを3Dスタックすることでメモリ容量を増やしている2)。AIの分野では、300mmウェハ全面を活用するCerebras SystemsのWafer Scale Engine(WSE)シリーズや、NVIDIAによる大型GPUダイ「H100」とHBM DRAMを組み合わせた超スケールアウト処理システムが、ディープラーニングコンピューティングの限界を押し広げている3)4)。
-

Apple M1 Ultra。シリコンブリッジを介して2つのチップをつなぎ合わせている (出所:Apple)

-

AMDはプロセッサSoCの上にSRAMダイを3Dスタックすることで性能を向上させている (出所:AMD)

こうした事例は、特定のニーズに応じるための技術開発が極限まで追い込まれていることを示している。一方で、拡張現実や仮想現実、6Gワイヤレス、自律走行車などの新しいアプリケーションでは、大幅なパフォーマンスの向上と電力の削減が必要になってきている。ワークロードと動作条件により、CMOSがサポートすることが期待される実装の多様性がさらに高まり、最適とは言えない妥協がさらに多く必要になろうとしている。
言い換えれば、CMOSがかつての汎用技術としての強力な役割を果たせなくなったことを我々は目の当たりにしているということである。その代わりに、アプリケーションの成功は、利用可能なCMOSがその特定の境界条件をどれだけうまく満たしているかに左右される状況に陥ることになる。Googleのサラ・フッカーはこれを「ハードウェアくじ」と名付け、ハードウェアがどの研究アイデアが成功するか失敗するかを決定することを示唆している5)。
(次回に続く)
本記事はimecの「The CMOS 2.0 Revolution」を許可を得て翻訳したものとなります
参考文献
- Kenyon, C. & Capano, C. Apple Silicon Performance in Scientific Computing. 2022 IEEE High Performance Extreme Computing Conference, HPEC 2022 (2022) doi:10.1109/HPEC55821.2022.9926315
- AMD 3D V-CacheTM Technology | AMD
- Lie, S. Cerebras Architecture Deep Dive: First Look Inside the Hardware/Software Co-Design for Deep Learning. IEEE Micro 43, 18–30 (2023)
- Choquette, J. NVIDIA Hopper H100 GPU: Scaling Performance. IEEE Micro 43, 9–17 (2023)
- Hooker, S. The Hardware Lottery. CoRR abs/2009.06489, (2020).

Julien Ryckaert(ジュリアン・リッカート)

Sri Samavedam(スリ・サマヴェダム)