LEFTやMIDといった関数を使って文字列データを分割することも可能だ。ただし、「関数の使い方を知っていれば十分」というケースは少なく、「どのようなアルゴリズムで文字を抜き出すか?」が重要な要素になるケースが大半を占める。その一例として、「住所」から「都道府県」を抜き出す場合を例に、考え方の基本を紹介していこう。
文字の抽出はアルゴリズム(考え方)が重要
前回の連載で紹介したLEFTやMID、RIGHTといった関数は、文字列データを分割して「新しい列」(フィールド)を作成する場合にもよく利用されている。たとえば、「住所」から「都道府県」だけを抜き出す、所属部署を「△△部」と「△△課」に分割する、といった場合などに関数LEFT、MID、RIGHTが活用できる。
ただし、単純に「関数を使えばOK」というケースは少なく、「どのような考え方に基づいて文字を抽出するか?」が重要になるケースが多い。
-

関数LEFT、MIDで文字を抽出、そのアルゴリズムと実例

その一例として、「住所」から「都道府県」を抜き出す方法を3つ紹介してみよう。今回は、以下の図のような住所一覧を使って具体的な手順を紹介していく。
-
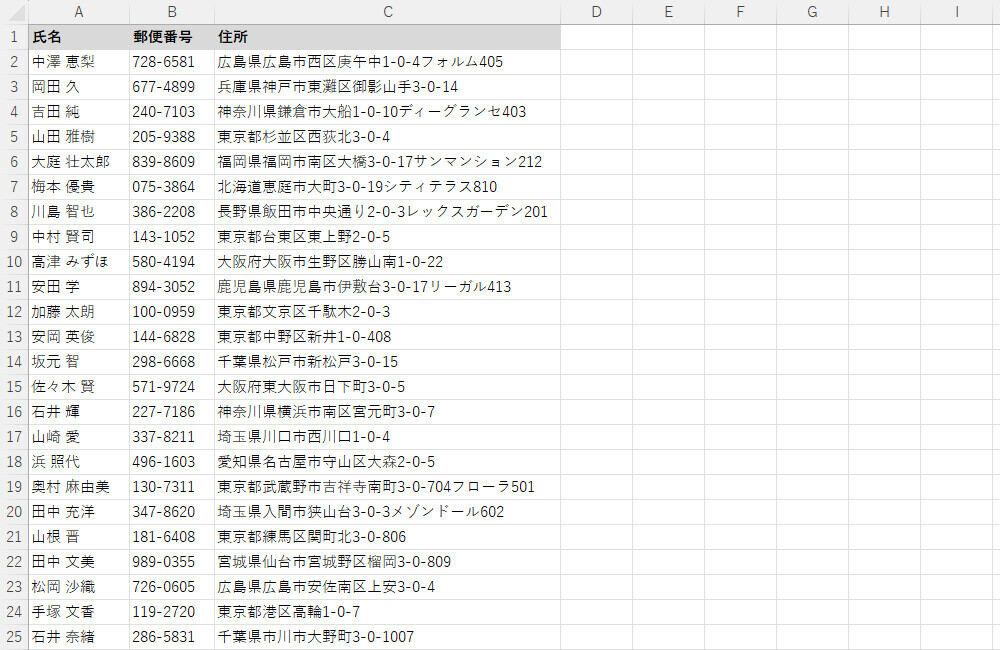
会員の住所一覧

最初に、「都道府県」の列を用意する。続いて、関数を使って「住所」から「都道府県」の文字を抽出していくが、「どうやって抜き出すか?」は一筋縄に解決できる問題ではない。
-

「都道府県」の列を用意

前回の連載でも紹介したように、LEFT、MID、RIGHTといった関数は「指定した文字数」だけ文字を抽出する関数となる。たとえば、「左から2文字分」とか、「4文字目から3文字分」といった文字の抽出であれば簡単に実行することができる。
一方、都道府県の文字数は「3文字」または「4文字」になるため、文字数は一律ではない。よって、関数LEFTだけで単純に解決できる問題とはならない。試しに、「住所」の先頭から3文字を関数LEFTで抽出した例を紹介しておこう。
-
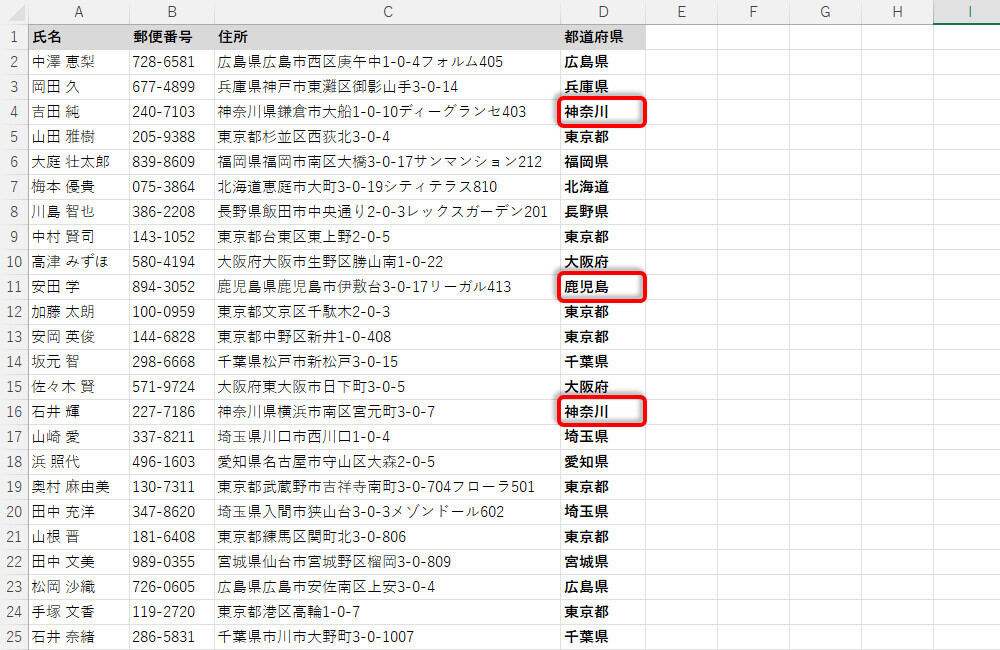
関数LEFTで先頭から3文字を抽出した場合

「広島県」や「兵庫県」のように正しく「都道府県」を抽出できるケースも沢山あるが、「神奈川」や「鹿児島」のように"県"の文字が不足している・・・、といった不具合が生じてしまう。これを完璧な形にするには、一定の法則にもとづいたアルゴリズムを構築し、それを実現するように関数を記述しなければならない。その具体的な方法を3種類ほど紹介していこう。


方法1:「4文字目が"県"であるか?」で条件分岐する方法
最初に紹介する方法は、「4文字目が"県"であるか?」に注目して条件分岐させる方法だ。これは、都道府県が以下のような法則になっていることに準拠した考え方となる。
・都道府県の文字数は「3文字」または「4文字」
・「4文字」になるのは、神奈川県、和歌山県、鹿児島県の3県のみ
・これらは「住所の4文字目」が必ず"県"になる
よって、「住所の4文字目」が"県"であった場合は「左から4文字を抽出」、そうでない場合は「左から3文字を抽出」というアルゴリズムを構築できる。「住所の4文字目」はMID(セル参照,4,1)で取得できるので、以下のように関数IFを記述すると「住所」から「都道府県」を抽出することが可能となる。
-
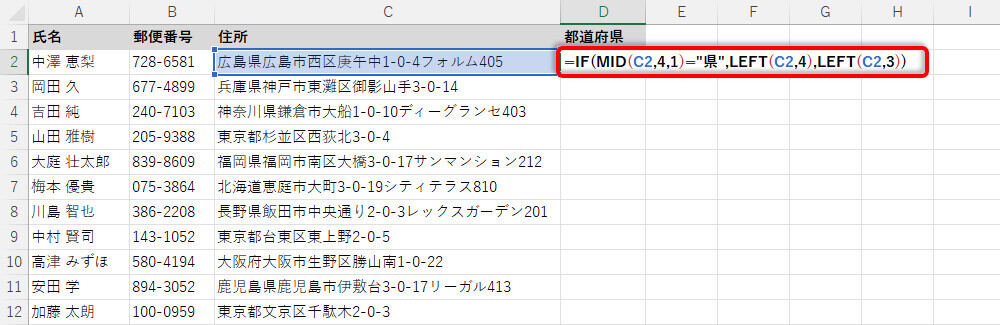
関数IF、MID、LEFTを使った「都道府県」の抽出

上図の例は「住所の4文字目」が"県"でないため、偽の処理となるLEFT(C2,3)が実行される。その結果、「左から3文字」が抽出されることになる。
-
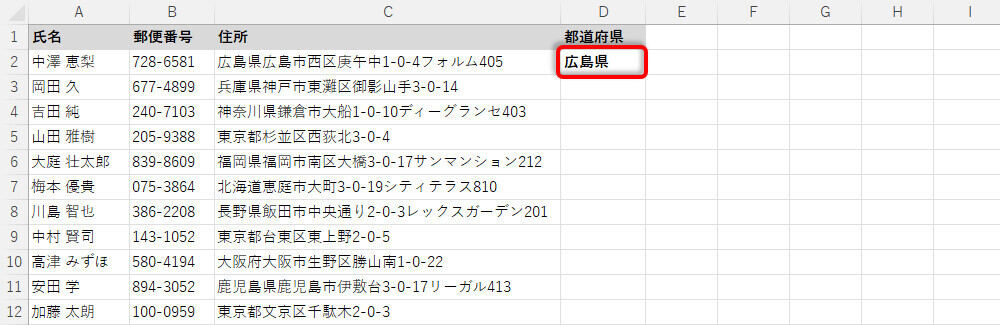
抽出された「都道府県」

あとは、この関数をオートフィルでコピーするだけ。神奈川県や鹿児島県のように「4文字」の都道府県も正しく抽出できていることを確認できるはずだ。
-
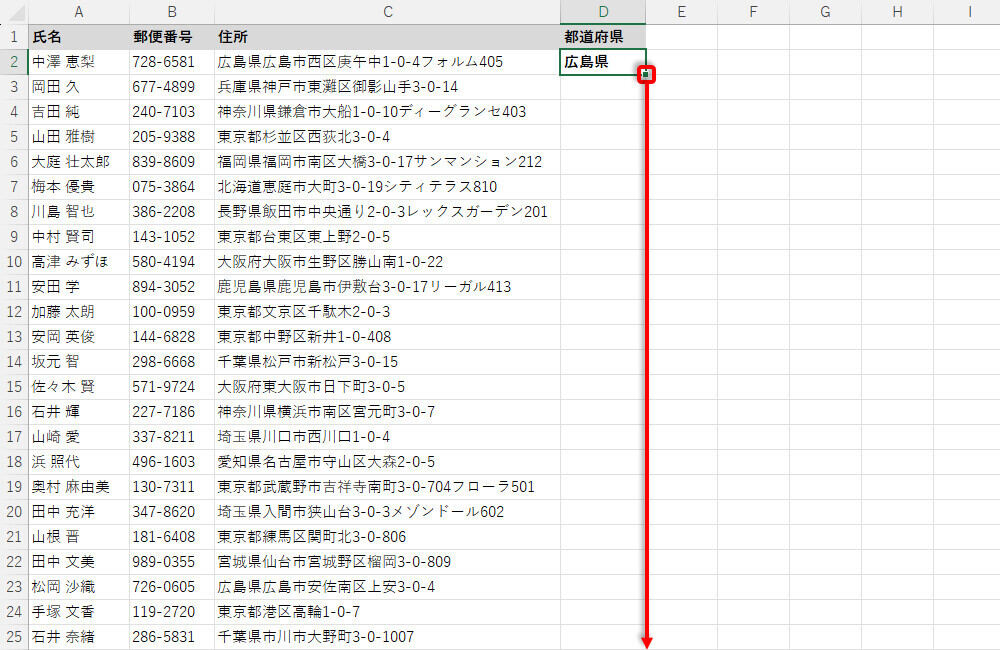
オートフィルで関数をコピー

-
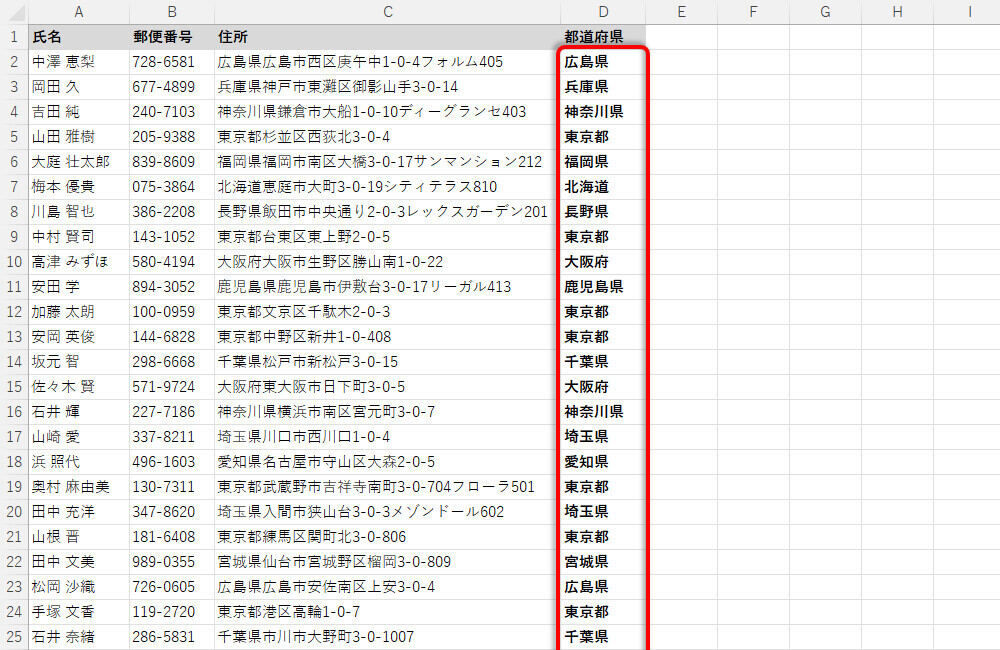
全レコードの「都道府県」を抽出した表

このように文字数を変化させながら「文字の抽出」を行うには、何らかのアルゴリズムを構築し、それに従って関数IFなどで条件分岐を行う必要がある。
方法2:TRUE / FALSEで抽出する文字数を変化させる方法
続いては、先ほどの例を少し改良した記述方法を紹介していこう。基本的なアルゴリズムは同じであるが、こちらは関数IFを使わない記述になっている。
まず最初に、以下の法則に注目してアルゴリズムを構築していく。
・都道府県の文字数は「3文字」または「4文字」
・その大半が「3文字」になる
つまり、「左から3文字」を抽出すれば、その大半は正しい都道府県になる、という考え方だ。
-
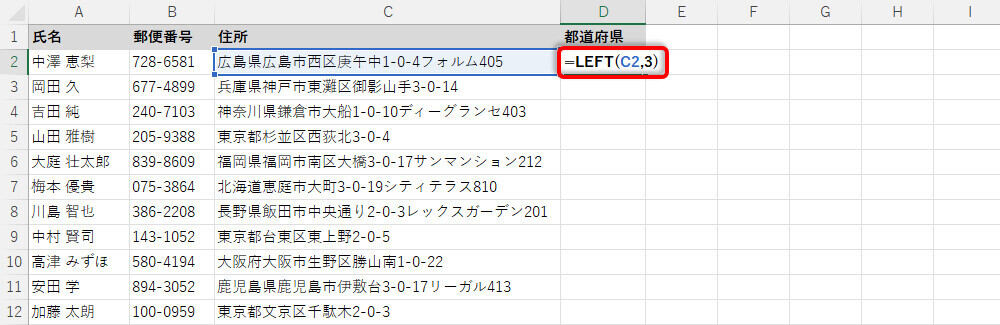
「左から3文字」を抽出する関数LEFT

もちろん、このままでは「4文字」の都道府県に対応できない。そこで、以下の法則をアルゴリズムに追加していく。
・「4文字」になるのは、神奈川県、和歌山県、鹿児島県の3県のみ
・これらは「住所の4文字目」が必ず"県"になる
つまり、「住所の4文字目」が"県"のときだけ、抽出する文字をプラス1して「4文字」に変更してあげればよい訳だ。ここでのポイントは「プラス1」をどのように表現するか?
関数に詳しい方なら、条件を満たしていることを示すTRUEが「数値の1」、条件を満たさないFALSEは「数値の0」として扱われることをご存じだろう。これを活用して「プラス1」を表現する。
「住所の4文字目」が"県"か否かの条件式は、「MID(セル参照,4,1)="県"」と記述できる。この結果は、TRUE(1)またはFALSE(0)になる。これを抽出する文字数「3」に足し算してあげると、TRUEの場合は「4文字」、FALSEの場合は「3文字」という条件分岐を実現できる。
-

関数IFを使わずに「抽出する文字数」を変化させる方法

上図の例は「住所の4文字目」が"県"でないため、条件式の結果はFLASEになる。よって、抽出する文字数は3+0=3となり「左から3文字」が抽出される。あとは、この関数をオートフィルでコピーするだけだ。
-
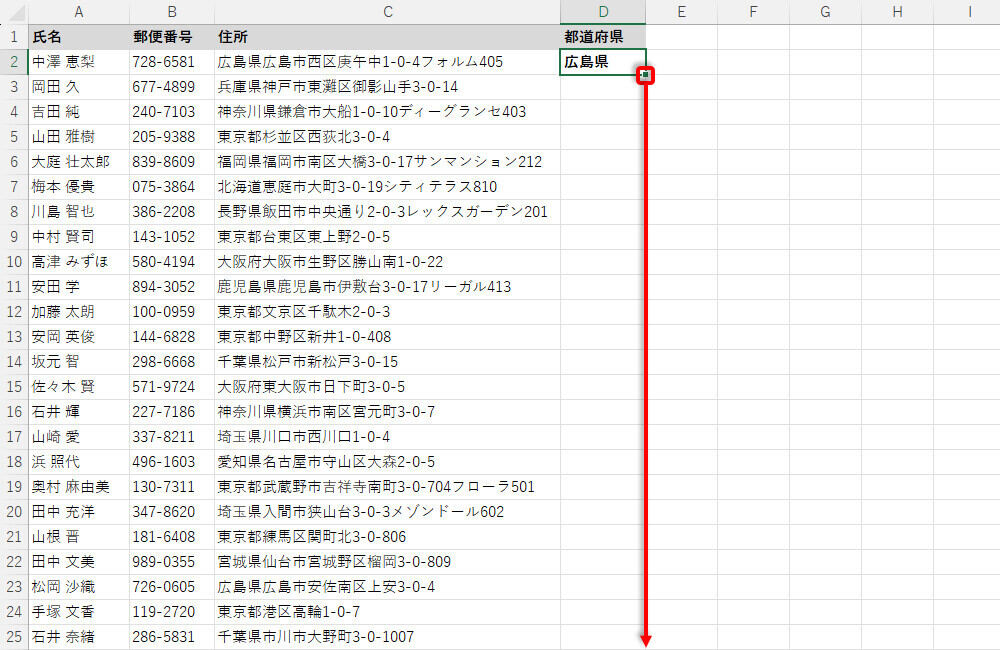
オートフィルで関数をコピー

この方法でも「住所」から「都道府県」を正しく抽出することできる。
-
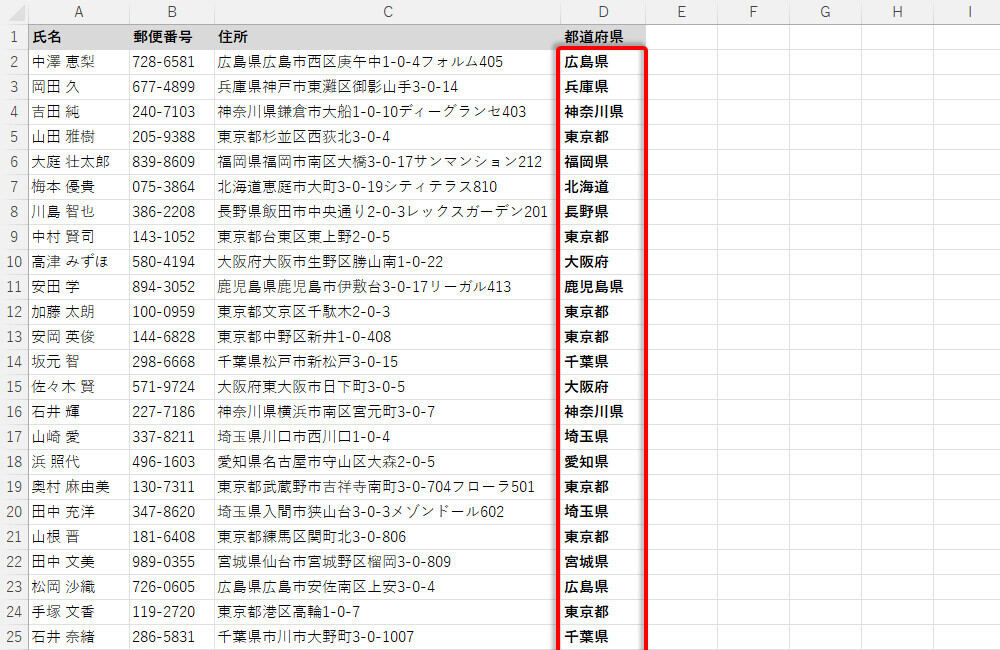
全レコードの「都道府県」を抽出した表

方法3:とりあえず"県"の文字まで抽出し、エラー対策を講じる方法
続いては、都道府県の大半が「△△県」になることに注目したアルゴリズムを紹介していこう。箇条書きで示すと、以下のような法則になる。
・都道府県の最後の文字は、"都"、"道"、"府"、"県"のいずれか
・その大半は"県"であり、それ以外は例外と考える
よって、とりあえず"県"の文字まで抜き出してみよう、という考え方だ。
「"県"が何文字目に登場するか?」は関数FINDで求められる。その結果は、N(文字目)という数値になる。よって、「左からN文字」を抽出する関数LEFTは、
=LEFT(参照セル,FIND("県",参照セル))
と記述できる。
-
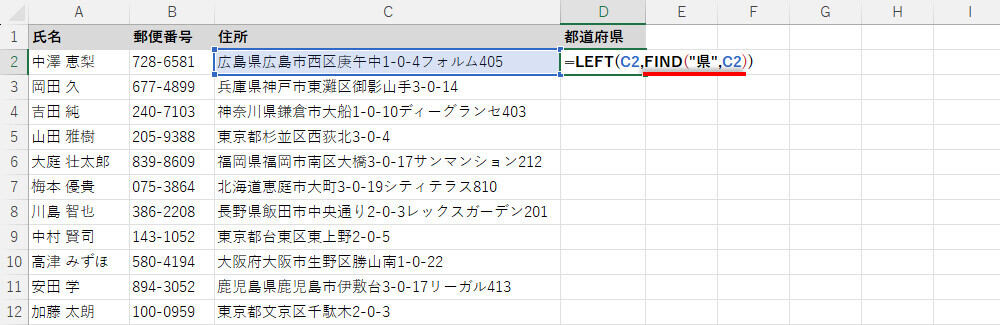
関数LEFTで"県"の文字まで抽出する方法

この関数をオートフィルでコピーすると、以下の図のような結果になる。
-
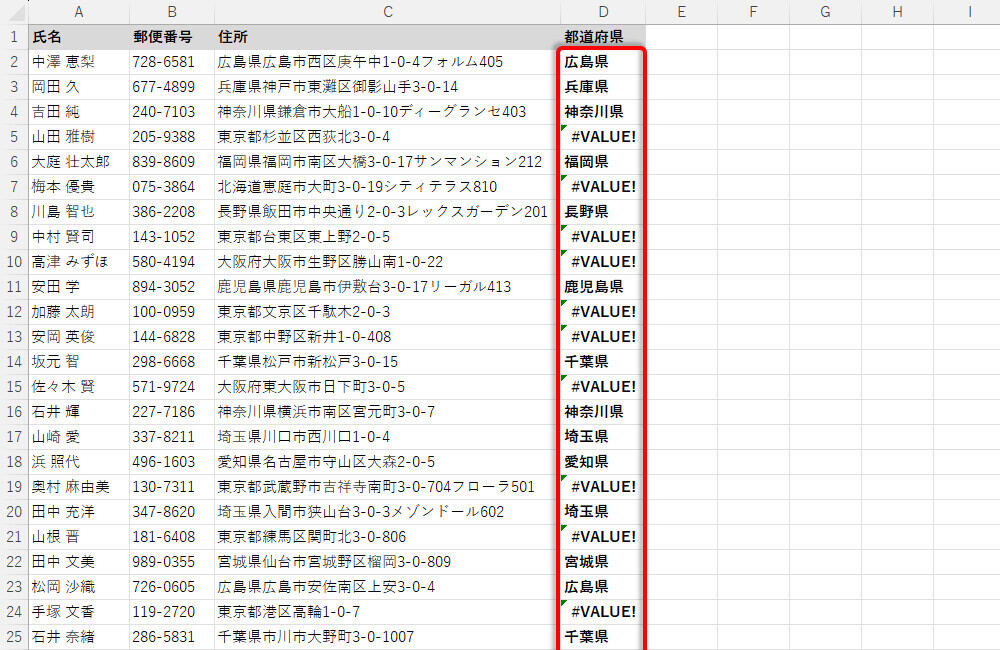
オートフィルで関数をコピーした様子

"県"の位置まで文字を抽出しているので、都道府県が「3文字」でも「4文字」でも問題なく抽出することが可能だ。ただし、住所に"県"の文字を含まない場合は「#VALUE!」のエラーが発生してしまう。
ということで、"県"を含まない場合の法則を考えてみよう。
・住所に"県"を含まない場合は、エラーが発生する
・"県"を含まないのは、北海道、東京都、京都府、大阪府の4つ
・これらはすべて「3文字」になる
つまり、エラーが発生したときのみ、「左から3文字を抽出」という処理に変更してあげればよい訳だ。エラーが発生したときの代替処理は、関数IFERRORで指定できる。これを先ほどの記述に追加すると、以下のようになる。
-
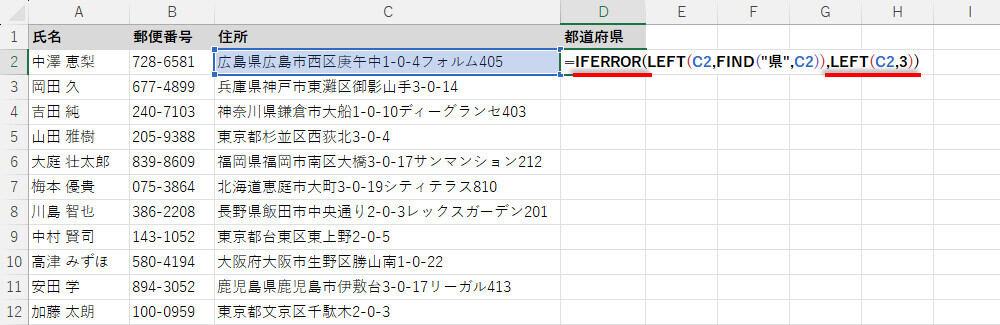
関数IFERRORで"県"を含まない住所に対応

あとは、この関数をオートフィルでコピーするだけ。この方法でも「住所」から「都道府県」を正しく抽出することできる。
-
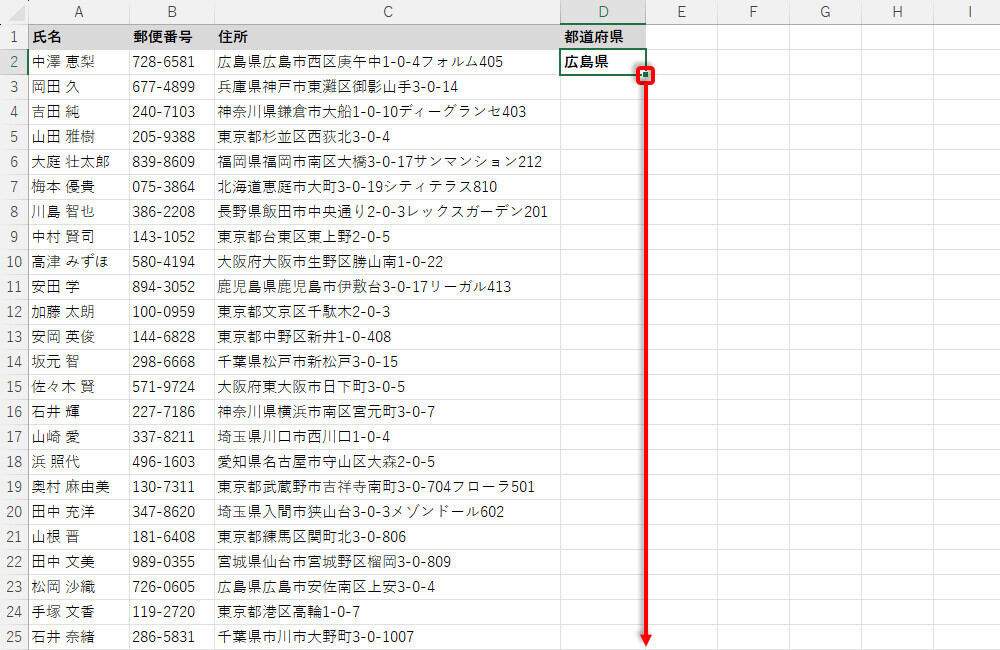
オートフィルで関数をコピー

-

全レコードの「都道府県」を抽出した表

今回の連載で紹介したように、LEFTやMID、RIGHTといった関数を使って「必要な文字」だけを抽出することも可能である。ただし、その位置や文字数が一定でない場合は、何らかのアルゴリズムを構築して、それに従って関数を記述していく必要がある。むしろ、「関数の使い方」より、「どのようにアルゴリズムを構築するか?」が重要になるといえるだろう。
さらに、構築したアルゴリズムを具現化するために、関数IFや関数IFERRORなどを上手に活用するテクニックを学んでおく必要もある。
このように「文字の抽出」は、複数の関数を組み合わせた、少し上級者向けの課題になるケースが少なくない。その解決方法(アルゴリズム)は状況に応じて異なるため、一概に述べることはできないが、今回の連載が少しでも参考になれば幸いである。