


スノーフレイクは4月18日、開発者向けのフレームワーク「Snowpark」に関する説明会を開催した。説明会では、「Snowpark」の技術的な解説と導入事例の紹介が行われた。
データエンジニアリングの課題を解消する「Snowpark」
「Snowpark」を用いることで、Java、Scala、Pythonといったプログラミング言語を用いてデータクラウド「Snowflake」上のデータを操作することが可能になる。シニアプロダクトマーケティングマネージャー兼エヴァンジェリスト KT氏は、「Snowflakeはデータエンジニアリングにおける課題を解決するもの」と説明した。
-

スノーフレイク シニアプロダクトマーケティングマネージャー兼エヴァンジェリスト KT氏

KT氏は、データエンジニアリングの課題として、「サイロ化した多様なデータ」「パイプラインの信頼性と性能」「管理と維持が難しい点」を挙げた。同氏は、これらの課題を従来のアプローチでは複雑になるため解決することは難しいと指摘した。
従来のアプローチでは、「顧客が言語ごとに処理クラスターを実行することが多い」「キャパシティ管理とリソースのサイズ設定が複雑」「データ移動とデータサイロが多い」といった問題があるという。
「Snowflake」は合理化されたアーキテクチャによって、これらの問題を解消している。具体的に「Snowflake」は、「多様な言語をネイティブでサポートする単一のプラットフォーム」「シンプルなキャパシティ管理とリソースのサイズ設定」「同一データでコラボレーション可能」「一貫したガバナンスと セキュリティポリシー」という特徴を備えている。これらを実現する機能の一つが「Snowpark」となる。
「Python、Java、Scala、SQLに対応するSnowparkは言語の柔軟性に対応し、開発者のスキルセットもカバーする。Snowparkは既存のSparkパイプラインを最小限のコード変更で移行するため、パイプラインのスピードアップを実現する。パイプラインが短いと リソースのスペックを落とせるので利用量減り、コストが削減される」(KT氏)
「Snowpark」はJavaとScalaの対応が先行して始まり、2022年に「Snowpark for Python」の一般提供が開始された。「Snowpark for Python」では、3つの方法でデータを扱える。
-
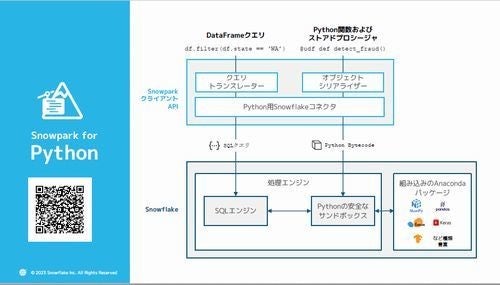
「Snowpark」の仕組み



「Snowpark for Python」の導入効果は?
続いて、dely 開発BU クラシル開発部 バックエンドエンジニアリングS Dataチーム データエンジニアのharry氏が「Snowpark」の導入について説明した。同社は、料理レシピ動画サービス「クラシル」において「Snowpark」を導入している。同氏は、2022年、2023年と2年連続で、「Snowflakeデータスーパーヒーロー」に選ばれている。
-

dely 開発BU クラシル開発部 バックエンドエンジニアリングS Dataチーム データエンジニア harry氏

同社はこれまで「1分レシピ動画」を数多く提供してきたが、今後は、「ユーザー投稿型プラットフォーム」として、パーソナライズドとライブ配信に注力していくことを計画しているという。
その一環として、コンテンツのロングテイルの可能性を信じ、多様なユーザーのニーズとコンテンツをマッチングさせるレコメンドエンジンの開発に着手している。
こうした中、同社は以下のような課題を抱えていたという。
- できるだけリアルタイムでユーザーへのリコメンデーションを実現すること
- ML基盤やMLOpsをこれから考えていくこと -アジリティを持った開発サイクルを回していくこと
同社は、こうした課題を解決するため「Snowpark for Python」を導入して、パイプラインを構築した。これにより、既存のリアルタイムデータパイプラインの延長線上で機械学習を用いたレコメンデーションが実現可能になったという。サービス、クラウド間でデータの移動もないため、「コストメリットも高い」とharry氏は語っていた。
そのほか、「Snowpark for Python」の導入効果として、以下を実感しているという。
- データの入力、学習、推論処理を呼び出しアプリケーション側へ結果を返すまでの処理をすべてイベントドリブンに実現できた
- Snowparkに最適化されたウェアハウスも選択可能になった
- 推論処理の実行頻度とウェアハウスのサイズによるコスト調整も比較的楽になった
-
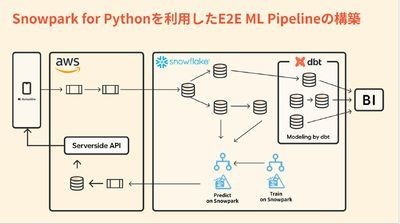
「Snowpark for Python」を活用したE2E MLパイプラインの構築

harry氏は、Snowparkに対する今後の期待として、「Streamlit」と「Pythonワークシート」を挙げていた。— Streamlitは、Pythonで実装されたオープンソースのWebアプリケーションのフレームワークで、SnowflakeはStreamlitの統合を進めてる。また、「Pythonワークシート」は、SnowflakeをブラウザからGUIで操作できるSnowsight上で、Snowpark for Pythonのコーディングができるもので、現在、パブリックプレビューが提供されている。いずれも、これから一般提供を控えているサービスだ。














