IntelはHot Chips 33において次世代のデータセンターCPUである「Sapphire Rapids」を発表した。
-

図1 Sapphire Rapidsはデータセンターの新しいアーキテクチャの標準となるものである。マイクロサービスやAI処理向けの設計で、先進的なメモリやIOトランザクション処理を行う (このレポートのすべての図はHC33でのIntelのArijit Biswas氏の発表資料のコピーである)

ノード性能に関しては、新アーキテクチャの高性能コアを開発して搭載している。また、データ並列の性能向上という点では複数のアクセラレータエンジンを集積すると同時に、搭載しているコア数を増やしている。
キャッシュやメモリサブシステムについては、キャッシュの容量の増加、DDR5 DRAMの採用、次世代のOptaneメモリのサポート、PCIe5.0の採用などを行っている。ソケット内/ソケット間のスケーラビリティについてはモジュラーなSoCやモジュラーなダイ接続ファブリックの使用、UPIの幅や転送速度の改良、Embedded Silicon Bridge(EMIB)を使う接続でスケーラビリティを確保している。
-

図2 ノード性能の改良。コア性能の改善、データ並列性の改善、キャッシュやメモリ系の改善、ソケット内とソケット間のスケーリングの改善を行った

データセンター性能に関してはコンソリデーションとオーケストレーション、性能の整合性、データセンターの効率の高い運用、インフラとフレームワークのオーバヘッドの低減などを行っている。
コンソリデーションやオーケストレーションについては、VMのマイグレーションの高速化、遠隔計測の改良、IO仮想化などの改善を行っている。性能の整合性については低ジッタアーキテクチャで実行時間のばらつきを減らし、キャッシュの追い出しやメモリレーテンシのばらつきを減らし、さらに、プロセサ間の割り込みの仮想化などを行っている。
データセンターの使用効率の改善については、次世代のOptaneメモリのサポートやCXL1.1のサポートなどを行っている。インフラストラクチャの改善としてはセキュリティーやRASの改善を行っている。
-

図3 データセンター性能に関してはコンソリデーションとオーケストレーション、性能の整合性、データセンターの効率の高い運用、インフラとフレームワークのオーバヘッドの低減などが重要になる

Ice Lakeでは1個のシリコンチップにCPUが収まっていたが、Sapphire Rapidsではダイサイズが大きくなり、4チップに分割することになった。4分割されたチップレットは論理的にはまったく同じであるが、端子位置などは異なる。
-

図4 Ice Lakeは1個のダイでできていたが、Sapphire Rapidsは4個のタイルをEMIBでつなぎ合わせている

-

図5 Sapphire Rapids CPUは4枚のタイルに分割して作られている。どのスレッドもすべてのタイルのすべての資源にアクセスできる。整合の取れた低レーテンシで高バンド幅のアクセスができる

-

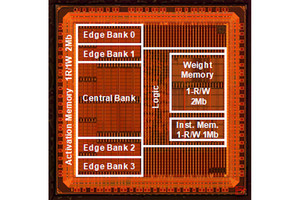
図6 Sapphire Rapidsの主要な構成要素。コアやアクセラレータなどのCompute IP、CXL1.1、PCIeGen5、UPI 2.0などのI/O IP、DDR5、Optane、HBMなどのMemory IPがある。右の図はタイルの中でのIPの配置を示す

パフォーマンスコアの主要マイクロアーキテクチャは一新されており、IPCも向上している。大きなコードやデータに対するサポートが改良されている。複数ユーザで分割して使用しても公平に分割した性能が得られる。高精度でジッタの少ない性能モニタリングなどができるようになっている。
-

図7 データセンター向けのアーキテクチャ改善。主要なマイクロアーキテクチャの改善とIPCの向上

パフォーマンスコアはAI向けのAdvance Matrix Extensionsの新設、アクセラレータ接続インタフェースAiAの追加、半精度浮動小数点数の演算命令の追加などを行っている。
-

図8 パフォーマンスコアの改良。AI計算用のAdvanced Matrix Extensions命令を追加、アクセラレータの接続インタフェース(AiA)を新設、半精度Float命令を追加

Sapphire Rapidsはコア以外にAiAを使ってアクセラレータを付けることができる。これらのアクセラレータで、コアからCommon Modeの処理をオフロードすることができる。これにより、コアはより多くのサイクルを主要計算に振り向けることができる。
-

図9 Sapphire Rapidsのアクセラレーションエンジン。ユーザスペースからアクセラレーションエンジンを起動、コアとアクセラレーションエンジン間でメモリをコヒーレントに共用するので、アクセラレーションエンジンがコアをオフロード

図10に見られるように、オフロードを行っていない場合は、CPUコアは45%程度のサイクルは処理を行い、55%の時間はデータの移動を行っている。しかし、データ移動をDSAにオフロードすると39%のCPUコアサイクルがCPUからオフロードでき、他の仕事をやることができるようになる。
-

図10 データストリーミング用のアクセラレーションエンジン。オフロードを行うとこのケースではCPUのコアサイクルの39%がオフロードできる

暗号化とデータの圧縮、伸長を行うQATオフロードの場合は、対称暗号の場合は400Gb/sまで、圧縮、伸長の場合はそれぞれ160Gb/sでの処理をオフロードすることができる。したがって、次の例ではQATオフロードの場合は98%の仕事がオフロードできてしまう。
-

図11 暗号化とデータの圧縮、伸長のオフロードのケース。98%のサイクルがオフロードされ、98%のサイクルで別の仕事ができるようになる

ロードバランスをする場合は、毎秒400M回のロードバランス判定、ソフトウェアキュー管理のオフロード、ダイナミックなフロー型のロードバランスと、順序変更、最大8レベルまでのプライオリティーキュー処理、ダイナミックに電力を見ながらアプリのサイズ決定などをオフロードすることができる。
-

図12 Dynamic Load Balancingをアクセラレーションする場合。毎秒400M回のロードバランス判断、そのほかに、キューの管理やロードバランスなどをオフロードすることができる

CXL1.1にはアクセラレータやメモリを接続することができ、IO拡張の自由度が高い。また、Intel UPI2.0を使うと改良されたマルチソケットの拡張ができる。UPI2.0は16GT/sのデータ速度で4×24本の伝送線路を持つので、全体では192GB/sの伝送バンド幅を持つ。
-

図13 Sapphire RapidsのI/Oの進歩。CXL 1.1サポートでアクセラレータやメモリ拡張。PCIe 5.0サポートで性能と接続性を拡張。Intel UPI 2.0でマルチソケットスケーリングの改善

Sapphire RapidsではIO仮想化を強化している。今日のデータセンターCPUでは、色々なIO処理を行うので、1つのIO処理を同じCPUで続けて実行するとは限らない。その時々で、できるだけIO処理が詰め込めるようにCPUを選んで実行して効率を上げる。しかし、その場合は、仮想空間のアドレス変換などが必要になる。Sapphire Rapidsは仮想化で必要となる処理をオフロードする機能を充実している。
-

図14 IO仮想化でシェアード仮想メモリ(SVM)とスケーラブルIO仮想化をサポート。VMやコンテナとPCIeデバイスの通信のアクセラレーション機能を持つ

そしてSapphire Rapidsでは最終レベルのキャッシュを100MB以上搭載している。Sapphire Rapidsは10nmプロセスを使っているので、7nmプロセスを使うAMDのZen3に比べて集積度の点では不利である。しかし、EMIBで4つのタイルを使えばSapphire Rapidsの方がたくさんのLLCメモリを搭載できる。
消費電力やコストの点では不利と思われるが、現在のところ、消費電力やコストは発表されていない。
そして、Sapphire RapidsではDDR5メモリを搭載し、メモリ暗号化エンジンを搭載している。また、Intelは不揮発性のOptaneメモリというAMDには無い技術がある。OptaneメモリはDRAMに近いアクセス性能で、DRAMより大容量の不揮発性メモリを作ることができる。
-

図15 メモリと最終レベルキャッシュ(LLC)。LLCを100MB以上に拡張することができる。DDR5メモリでバンド幅、安全性、信頼性を拡張。Optane 300シリーズ Persistentメモリのサポート

そして、Sapphire Rapidsは、DDR5に加えてHBMが付けられるようになっている。HBMの付け方は2通りあり、Flat ModeではHBMとDDR5メモリは異なるアドレスのデータを記憶するメモリとなる。もう1つのモードはHBM Caching Modeで、このモードではHBMはDDR5のキャッシュメモリとして動作する。
Flat Modeでは、HBMに割り付けたメモリは高速でアクセスできるが、その他のアドレスは普通のDDR5メモリである。HBM Caching ModeではHBMをキャッシュメモリとして使うので、DDR5メモリにキャッシュが付いたように動作する。
-

図16 Sapphire RapidsはDDR5とHBMの両方を使う。HBM Flat ModeとHBM Caching Mode

IntelはAIが広範囲に利用されるようになると考えており、Sapphire RapidsはAI処理を主要なターゲットとして設計されている。AI処理の効率を高めるためディープラーニング計算用のint8やBfloat16などのデータタイプをサポートしている。これらの命令は普通のXeonの命令として使用することができるようになっている。そして、これらの命令は業界の一般的なフレームワークやライブラリで使用することができる。
-

図17 Sapphire RapidはAI向けのアーキテクチャ。Int8やBfloat16のサポート、AI向け命令もフルのIntelアーキテクチャで利用可能、業界で標準のフレームワークやライブラリで利用可能。AVX512でFP32で計算すると64Ops/Cycle/Coreに対して、AMX BF16で計算すると1024Ops/Cycle/Core、AVX-512でInt8で計算すると256Ops/Cycle/Coreであるのに対してAMX Int8で計算すると2048Ops/Cycle/Core

Sapphire Rapidはマイクロサービスを組み合わせてソフトウェアを作る最近の開発の方向性に合わせて、マイクロサービスの実行オーバヘッドの小さい造りになっている。実行開始までの最大レーテンシを守ってマイクロサービスを実行する場合のSapphire RapidのスループットはCascade Lakeと比べて69%高い。
-

図18 マイクロサービスを組み合わせてソフトウェアを作る最近の傾向に合わせて、Sapphire Rapidsではマイクロサービスの実行スループットを(Cascade Lakeと比べると1.69倍に)高めた

まとめると、Sapphire RapidsはデータセンターCPUのアーキテクチャとして大きなジャンプを実現しており、データセンターCPUの新しい標準となるものであると、Intelは書いている。IntelはプロセステクノロジでAMD CPUに遅れている点をEMIBでカバーし大チップ面積のCPUを実現している。さらにマイクロサービスの実行スループットなど、新しい使い方に向けた改良を盛り込んで、AMDに対する優位点を増やしている。
IntelがEMIBでマルチタイルを作り、大規模なCPUを実現した点は評価に値する。しかし、コストは高そうで、コストや消費電力が発表されないと、評価はしにくいと言える。
-

図19 Sapphire Rapidsはこの10年以上の間でのデータセンターCPUでの最大の飛躍。物理的にはマルチタイル化、論理的にはモノリシック。マイクロサービスとAI処理にフォーカス。先進メモリと先進IOインタフェースを採用