AMDのスタイルであるが、まず、コアを発表し、その何か月か後に、マルチコアのプロセサ製品を発表する。こうした方が開発の流れと一致しているし、コアの発表と製品の発表で、2回話題になるというメリットがある。
ということで、AMDは今回のHot Chips 33で「Zen 3コア」を発表した。そして、Zen 3コアを8個搭載するチップレットを発表した。
-

図1 これまでのZenプロセサの開発の歴史。2017年のZenからZen+、Zen2を開発し、今回、Zen 3を発表した。前世代からIPC(1サイクルに実行する命令数)を19%向上している。また、Cacheチップを3D実装で積み重ねる3D V-Cacheをサポートすることが発表された (このレポートのすべての図はHC33でのAMDのMark Evers氏の発表資料のコピーである)

Zen 3を新たに開発した目的は、性能の向上、新しい機能の追加とソケット互換を維持しながらエネルギー効率の改善などを行えるプラットフォームを作ることである。
図2では中央下側に黒銀色のチップがあり、上に2つのチップらしいものが見える。上の方は写真を貼り付けただけのような感じであるが、ここに8CPUのチップレットが2つ搭載されることを示しているようである。なお、本物ではCPUチップレットは下向きに搭載されるので、黒銀色の背中が見え、チップのパターンは見えない。
-

図2 Zen 3開発の目的。性能の向上と新しい機能の追加、ソケット互換の新たなプラットフォームの提供を目標としている。右の写真は2個のCPUダイを使う16CPU製品のイメージとなっている

Zen 3コアはコアあたり2命令を同時に実行するSMTとなっている。そして、整数ユニットを4個、メモリアクセスのアドレス計算は3アドレス/サイクルで計算でき256bitのFPの積和演算を2回/サイクル実行できる。メモリアクセスは毎サイクル3回実行でき、アドレス計算とあわせて、2つのオペランドをメモリから読んで演算し、その結果をメモリに書き戻すという操作を平均1サイクルで実行できる設計である。
全体に豪華な造りであるが、微細化でトランジスタは余ってきており、消費電力の増加よりも性能の向上が大きければ意味があるという判断のようである。
-
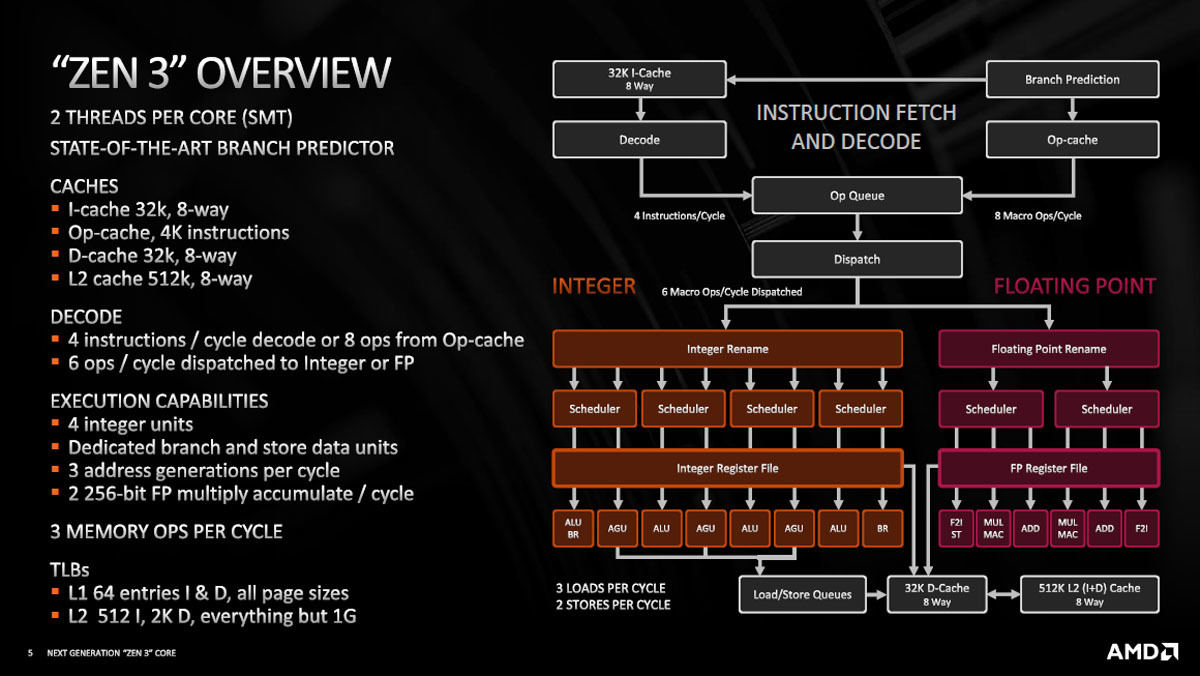
図3 Zen 3の概要。2スレッドのSMT実行と高性能の分岐予測、毎サイクル6命令を整数またはFPに発行。メモリ操作は3命令/サイクル

図4に見られるように、Zen 2に比べてZen 3は25のワークロードの幾何平均でIPCは19%向上している。そして、クロックが4.7GHzから4.9GHzと4%ほど向上しているので、全体としての性能向上は23%とかなり高い性能向上となっている。
IPC 19%向上の中身を右端のグラフに示しており、Load/Storeの改善やFront Endの改善の寄与が大きいが、あちこちで改善が入っており、それらの合わせ技で19%向上が実現されている。
-
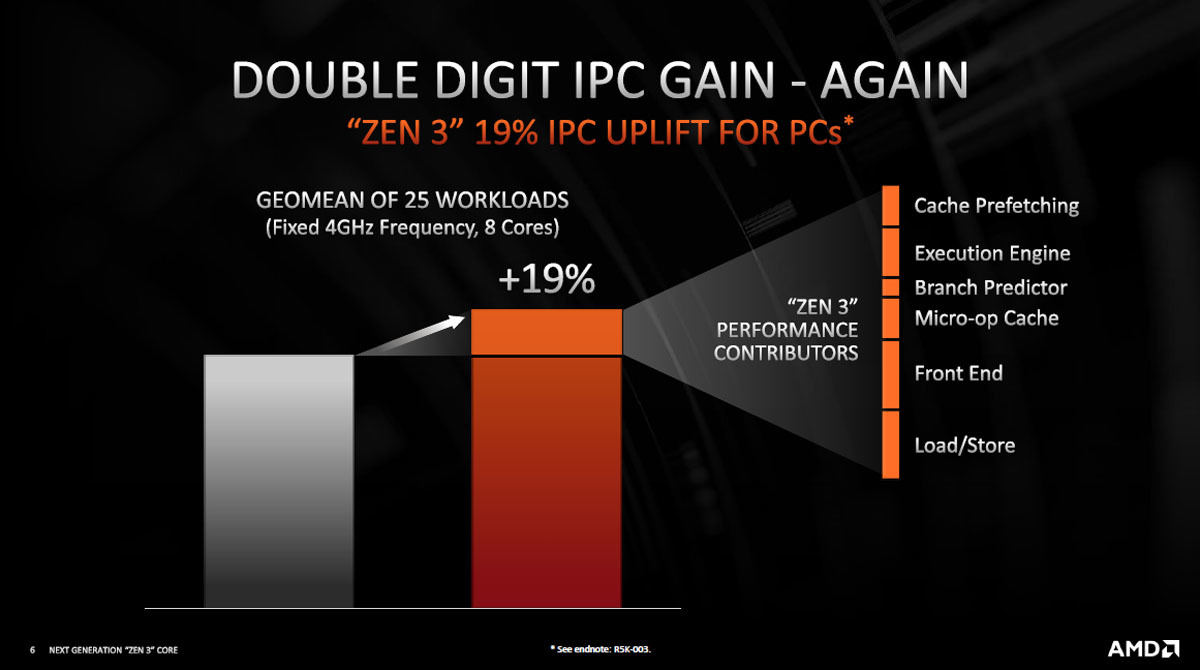
図4 Zen 2に続いてZen 3でも2桁(%)のIPC向上を実現。向上の中身を右端の棒グラフに示しているがLoad/Store、Front Endなどの改良が大きい

図5は整数の演算系での性能改善項目を示す。Zen 2では整数命令は7命令/サイクルの発行であったが、Zen 3では10命令発行に増えた、整数のレジスタファイルのエントリ数も180から192に増加している。整数命令のスケジューラも92命令から96命令にスケジューリングの幅が増えた。そして、アウトオブオーダに実行する命令の結果を並べ替えるRe-Order Buffer(ROB)の個数も224から256に増やしている。これらはアーキテクチャシミュレータを使って、ROB数を変えて性能変化を見ながらチューニングを行って決めたのであろう。
-
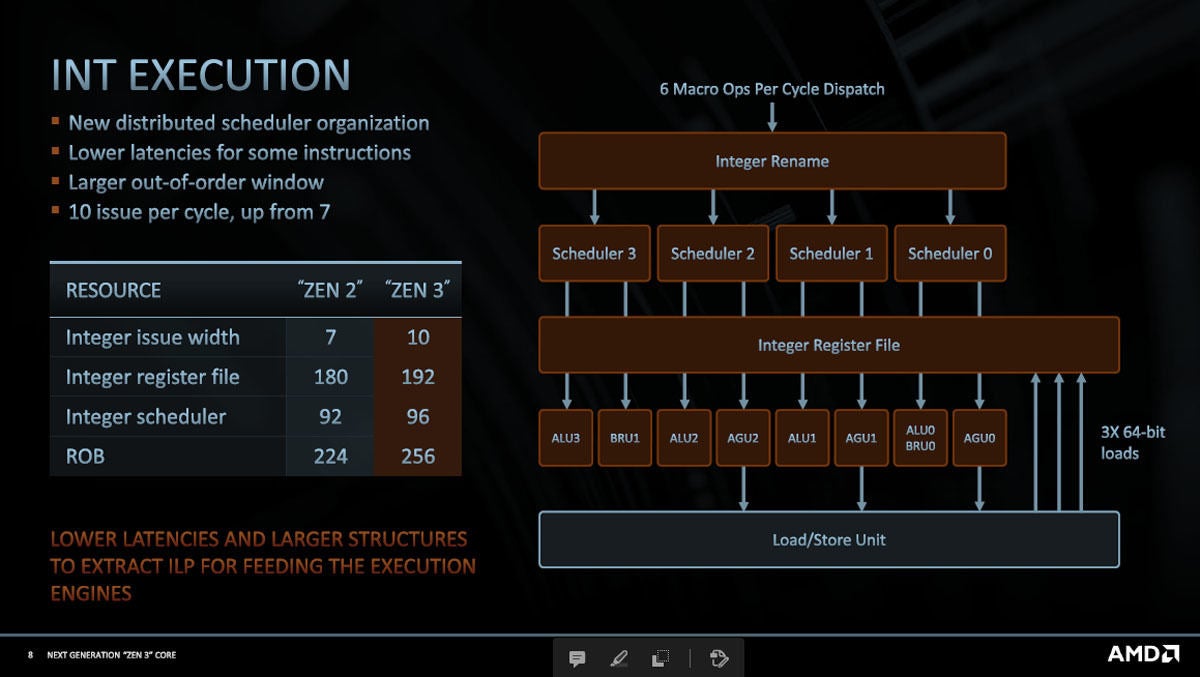
図5 整数命令実行系は命令発行系や整数レジスタファイルなどを増強して実際に実行される命令数を向上させている

整数命令実行系は、ALUやAGUの個数は増えていないし、レジスタファイルの書き込みやバイパスのポート数も増えていないが、ALU/AGU共用のスケジューラの採用によりバランスが良くなったなどの改良で性能が改善したという。
-
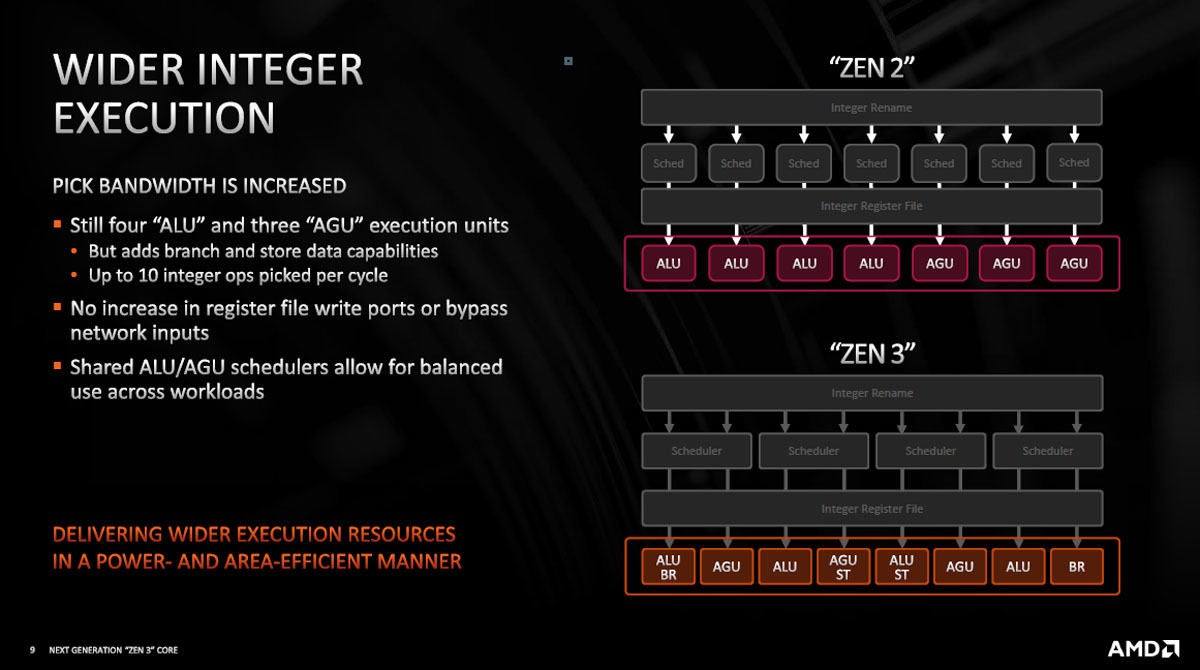
図6 整数演算系の改良。ALUやAGUの個数は増やしていないが、ALU/AGU共用のスケジューラを設けて込み具合を改善したという

浮動小数点演算は発行命令数を4から6に増強した。そして、FMAの計算レーテンシを5サイクルから4サイクルに短縮した。さらにFPのスケジューラのエントリ数を36から64と大幅に拡張した。また、マシンラーニング向けのINT8命令のスループットを倍増した。
-
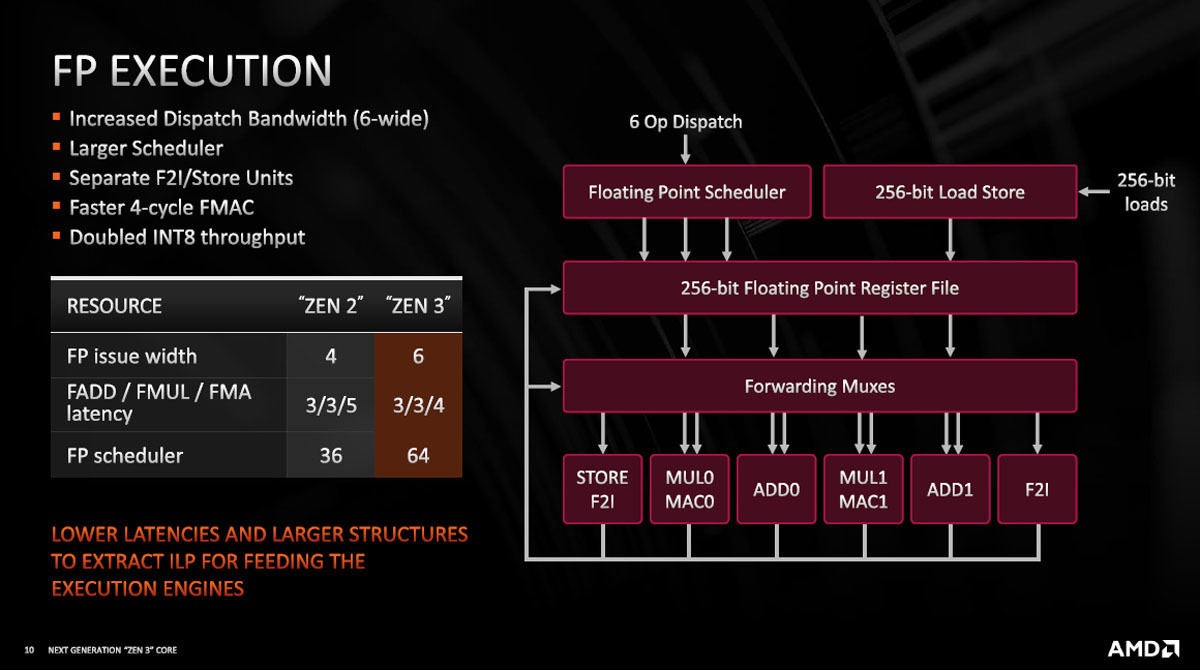
図7 FP命令の発行幅を4命令から6命令に増強し、FMA命令の実行レーテンシを5命令から4命令に短縮した。また、INT8命令のスループットを倍増した

ロードストアユニットはストアユニットのキューの長さを48から64に増強し、1サイクルに実行するロードやストアの個数を増やした。また、TLBミス時のテーブルウオーカーを増やすなどの改善を行っている。
-
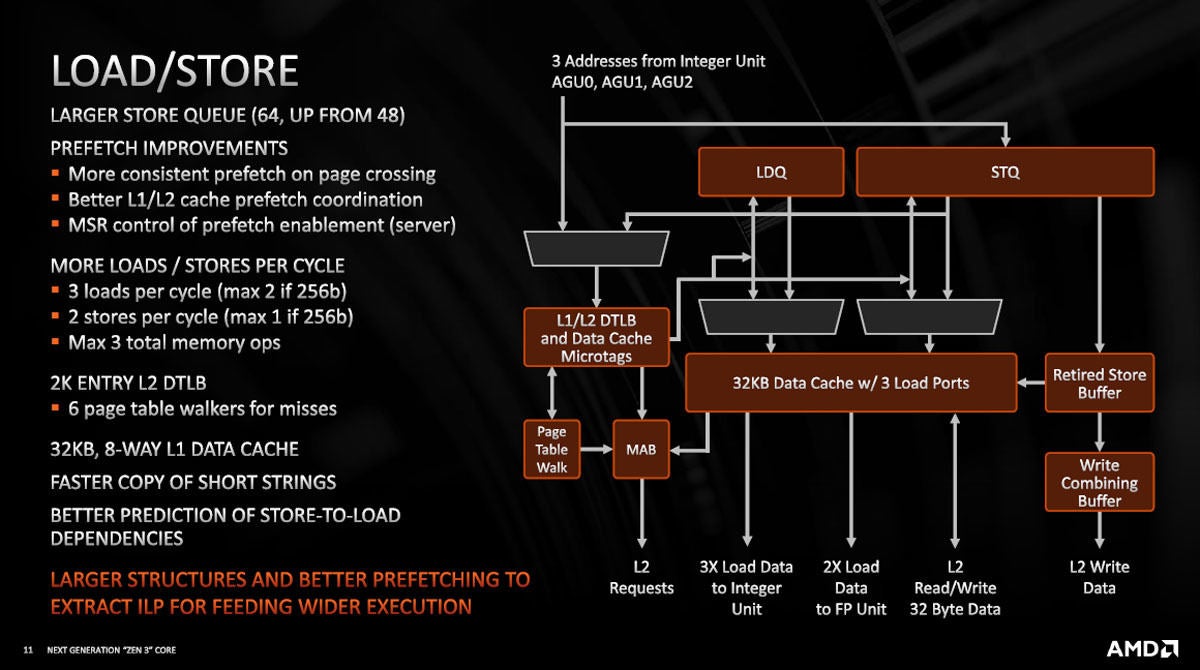
図8 ロードストアユニットは改善が多く行われている。ストアキューを64エントリに増やし、プリフェッチの改善や並列に実行できるロードやストアの個数を増やしている

Zen 2から、フロントエンドがかなり強化されている。分岐ターゲットバッファのサイズを倍増し、分岐予測器のバンド幅も増強している。また、分岐予測ミスからのリカバリも速くなっている。
演算器も改良され、アウトオブオーダ実行する窓のサイズを32命令増やしている。また、演算器のレーテンシも短縮している。FPは4命令発行から、6命令発行に増強している。
ロードストアは、ロードもストアもZen 2と比べて並列に実行できる命令数が1個ずつ増えている。
-

図9 Zen 2からの主要な変更。Zen 3ではフロントエンドの改良、実行ユニットの改良、そして、ロードストアの改良が行われている

25のワークロードでのZen 3での性能改善の幾何平均は19%であるが、主要なゲームでの性能改善は30%を超えるものもある。
-

図10 25のプログラムでのZen 3での性能向上。9%の性能向上から39%の性能向上まであり、幾何平均が19%の性能向上である

-

図11 Zen 3では暗号化やセキュリティの改良などのために命令の追加を行っている

コア以外の改良ではZen2では16MBのL3キャッシュに4CPUコアが付いた形のユニットが2個であったが、Zen 3では32MBのL3キャッシュに8CPUコアが付いた形となっている。つまり、Zen 2では各コアは16MBのL3キャッシュの中の情報しかアクセスできないが、Zen 3では32MBのキャッシュ全体のどこでもアクセスできる。Zen2では、同じ情報を上の16MBと下の16MBに重複して格納することが必要になる場合もでてくるが、 Zen 3では、32MBのキャッシュのどこに入っていても、どのコアからもアクセスできるので、このようなケースは存在しない。このため、キャッシュがより有効に利用でき、Zen 2より性能が高くなる。
-
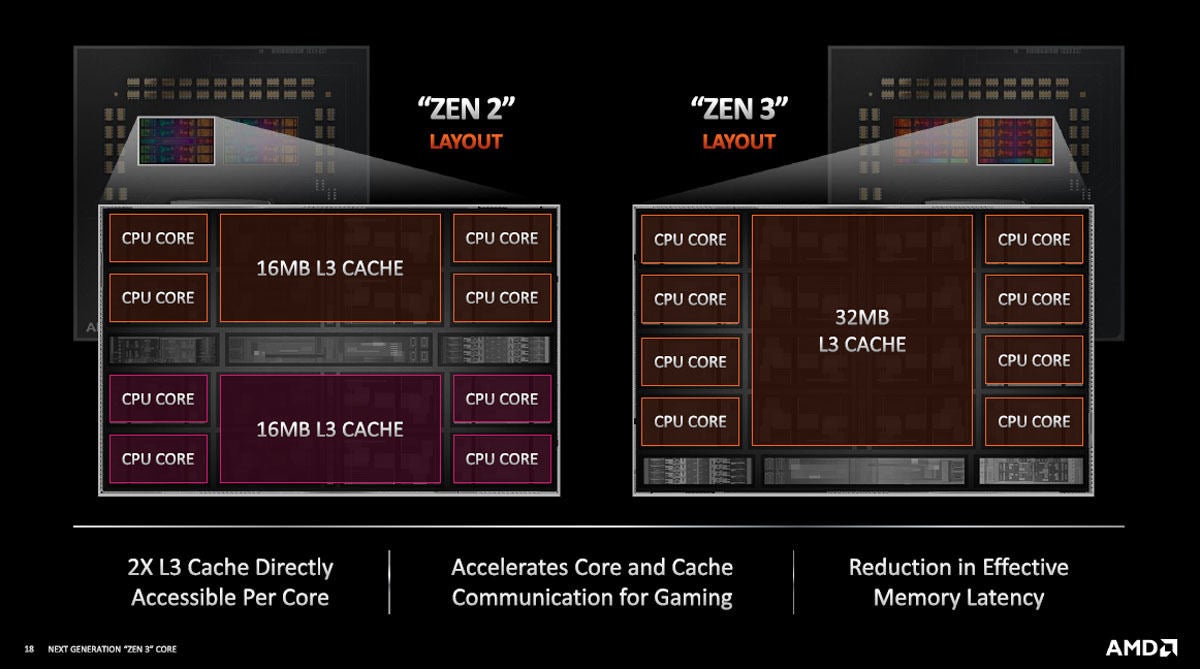
図12 Zen 2では16MBのキャッシュに4コアCPUが付き、これが2系統有ったが、Zen 3では中央の壁が無くなり、32MBのキャッシュのどこでも8個のコアからアクセスできる

そして、32MBのL3キャッシュは2重の高速のリングバスで繋がれており、アクセスレーテンシを短縮している。
-
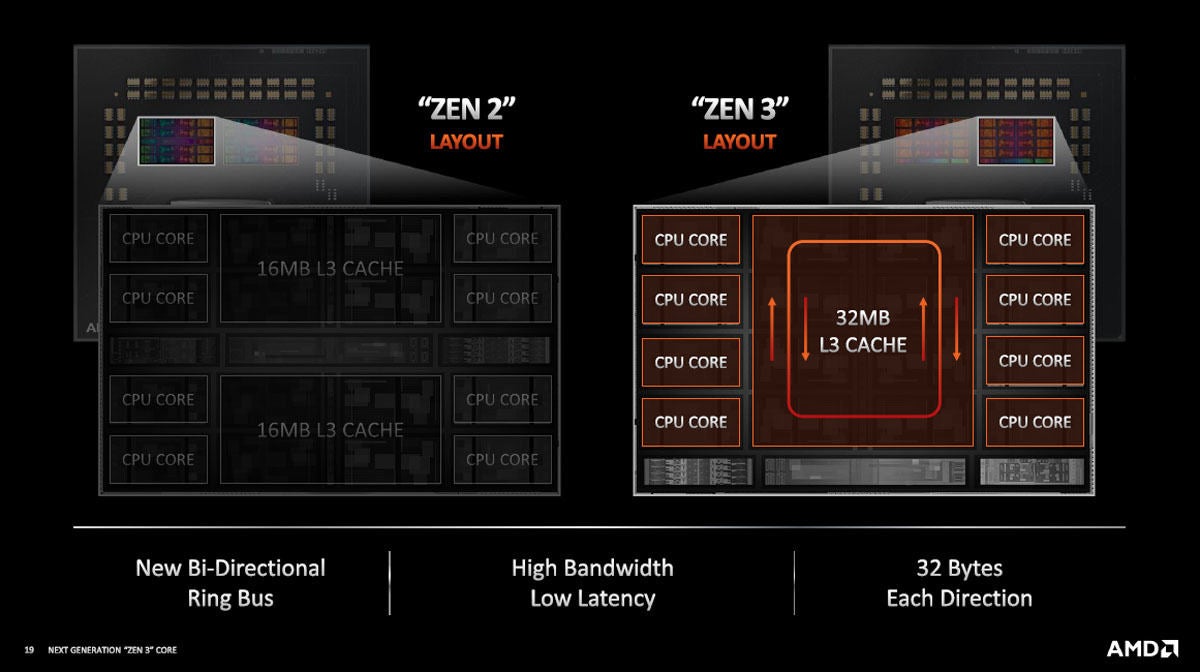
図13 Zen 3では32MBのL3キャッシュは32バイト幅の双方向のリングバスで繋がれており、レーテンシを短縮している

Zen 3のキャッシュは、8コアCCDの場合は、高速の512KBのL2キャッシュがあり、L3にはL2から追い出されたキャッシュラインが格納されるビクティムキャッシュとなっている。L2のタグはL3にも格納されておりプローブフィルタリングが高速に行えるようになっている。L2は最大64個のミスが発生した状態でもL2ヒットの処理を行えるようになっている。また、L3は最大192個のミスを抱えた状態でもL3ヒットの処理を行えるようになっている。
そして、L3にはAMD 3D V-Cacheを付けることができるようになっている。もちろん、V-Cacheの取り付けは半導体ファブでなければ行えないと思われるので、最初はV-Cachesなしで買って、その後、V-Cacheを増設するといいうことはできないと思われる。
-
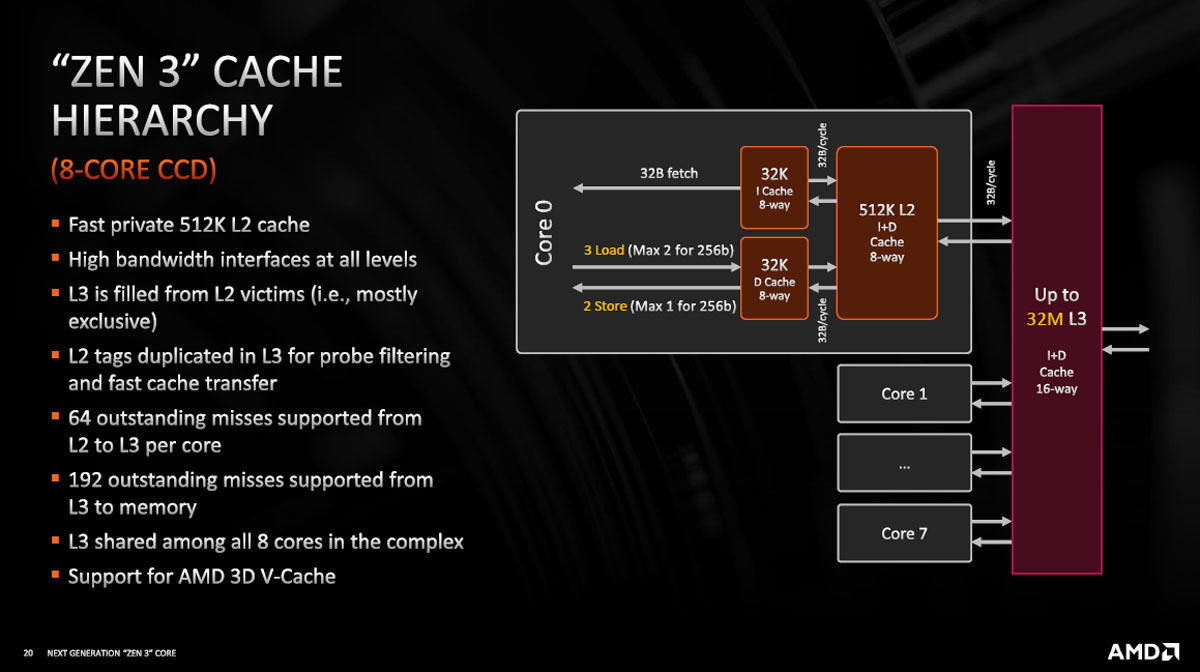
図14 8コアCCDの場合、高速のプライベートL2キャッシュは512KB。L3はビクティムキャッシュで、L2ミスのデータがL3に入る。L3はComplexの8コアで共同使用され、AMD 3D V-Cacheが付けられる

Zen 3 CCDは32MBのL3を持っており、3D V-Cacheで64MBのCacheを付ければ、CCDあたり96MBのL3キャッシュになる。図15ではダイの図の上に2つのアレイのダイの写真が付いており、これが32MB分のキャッシュと思われる。左右の半透明のダイはV-Cache付きのチップの厚みを揃えるためのダミーと思われる。
Direct copper-to-copper bondと書かれており、キャッシュダイの表面の銅端子同士をくっつけるだけでファンデルワールス力で接合するのだと思われる。
この3D V-CacheでL3キャッシュの容量を64MB増強して3倍にすると、5種のゲームで平均的に15%速度が向上したとのことである。
なお、図15では192MB L3プロトタイプと書かれているのはL3クラスタが2個ある構成を想定しているからである。
-
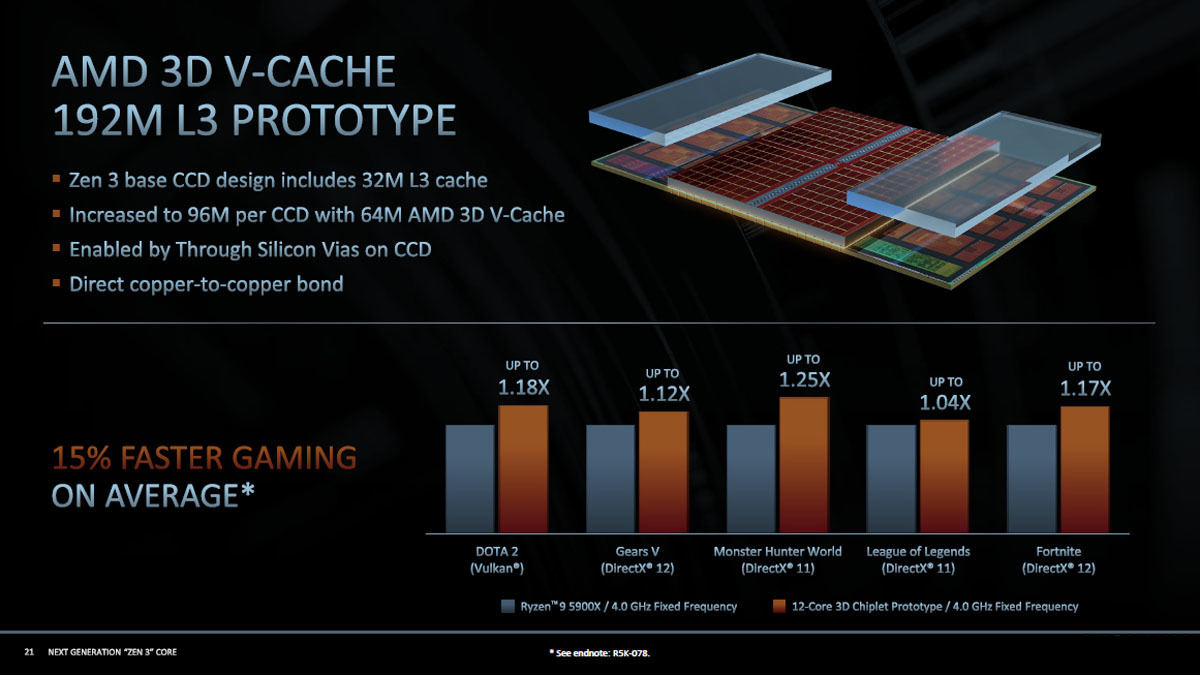
図15 AMDの192MBの3D V-Cacheプロトタイプ。Zen 3 CCDは32MBのL3を持っており、64MBのV-Cacheを付ければ、CCDあたり96MBのL3キャッシュになる

電力効率をIntelのCore i9 10900Kと比較したのが図16である。Zen 3を使うRYZEN 9 5900の電力効率は約2.4倍、RYZEN 9 5950Xの電力効率は約2.8倍となっている。
-
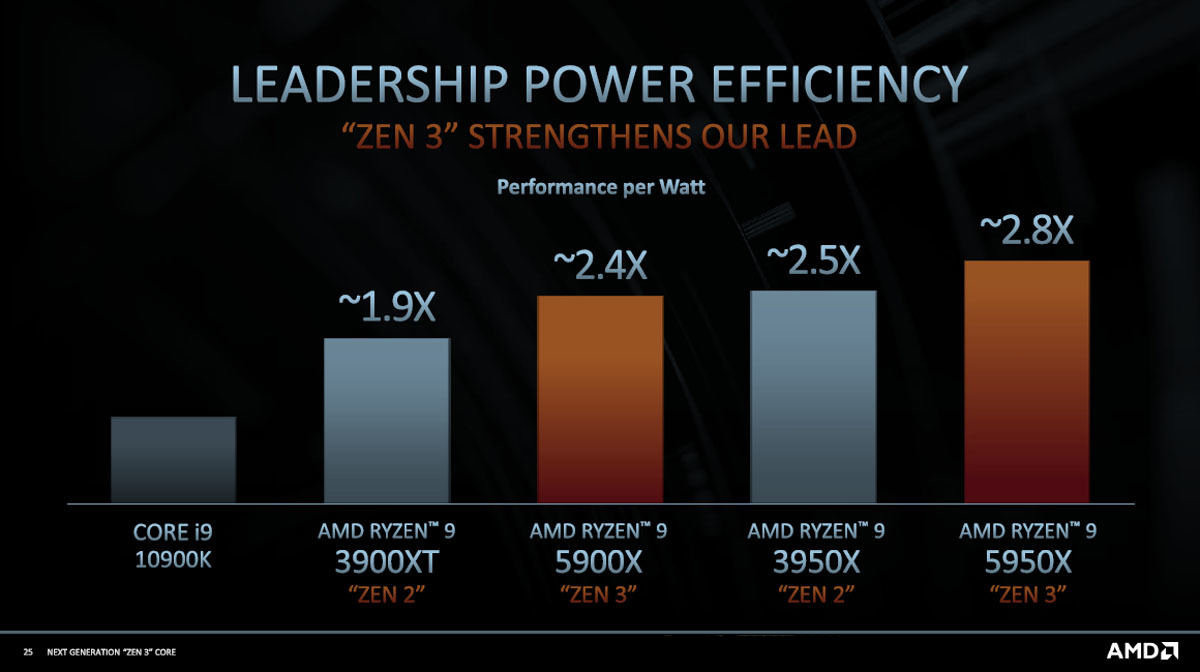
図16 Core i9 10900KとZen 2/3との電力効率の比較。RYZEN 9 5900Xは約2.4倍、RYZEN 9 5950Xは約2.8倍の電力効率

図17はZen 2コアのRyzen 9 3900XTとZen 3コアのRyzen 9 5900の主要ゲーム性能を比較したものである。
-
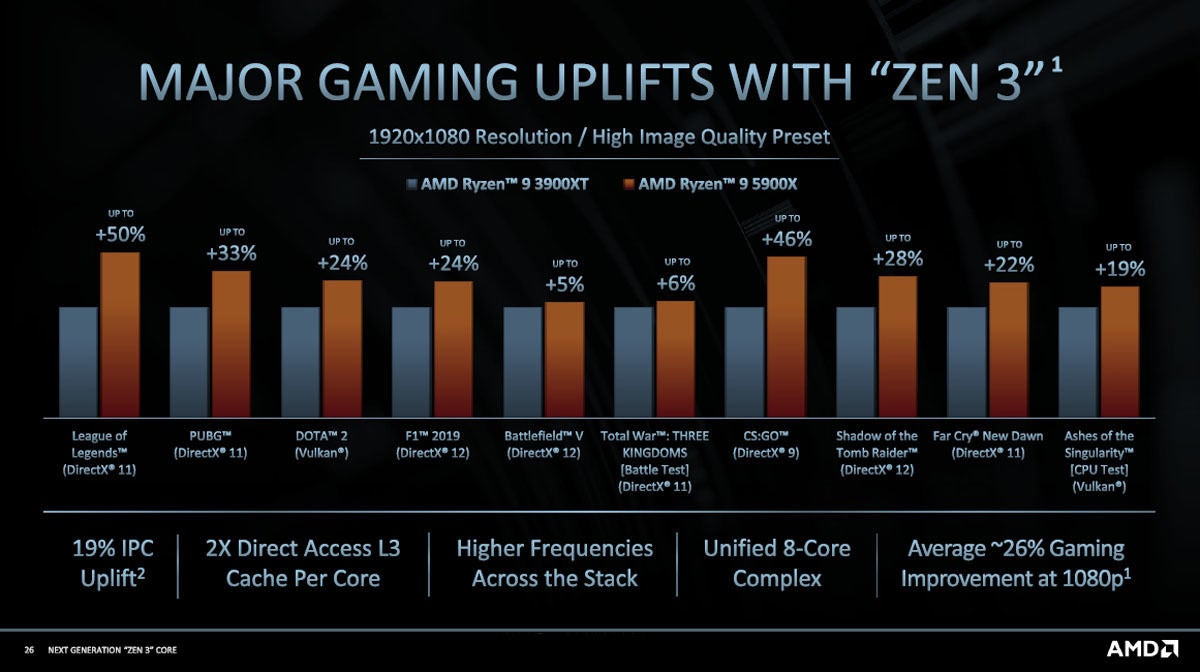
図17 10種の主要ゲームでのZen 2(3900XT)とZen 3(5900X)の性能比較。ゲームによるが、Ryzen 3の方が5%~50%速い。改善した項目としては、IPCでは19%向上、コア当たりアクセスできるキャッシュ量が2倍、クロックが向上、キャッシュアクセスが改善された8コアCache Complex化などで、ゲーム性能は約26%改善

これまでZen/Zen+、Zen2、Zen 3を開発してきており、2022年には5nmプロセスを使ってZen 4コアを出す予定である。Zen 4の開発は順調に進捗しているとのことである。
-

図18 2017年からのZenシリーズは、2021年にZen 3コアを出し、2022年には5nmプロセスを使うZen 4コアを出す予定