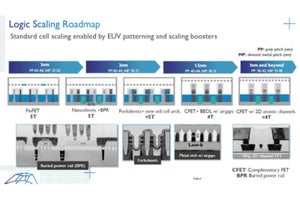
元Intelのフェローでテクノロジ開発を率いていたShekhar Borkar氏がSC20においてムーアの法則以降のコンピューティングと題する講演を行った。Borkar氏に最後にお会いした時はIntelを辞めたらリタイヤすると言っていたのだが、暇を持て余したのか現在はQualcommのテクノロジ関係のシニアディレクタと以前のIntel時代と同じような仕事をされているようである。
-

いわゆる、ムーアの法則以後のコンピューティングについて講演するQualcommのShekhar Borkar氏 (出所:SC20におけるShekhar Borkar氏の講演資料。以下すべて同様)

ムーアの法則とは何なのか?
2000年ころまでは、ムーアの法則で集積されるトランジスタ数が増え、デナードスケーリングでクロック周波数が上がってきた。しかし、その結果、消費電力が大きくなり、2010年ころにはパワーの壁にぶつかり、シングルスレッド性能を上げることができなくなってきた。そのため、2005年ころから、各社はマルチコア化で1チップに集積するコア数を増やして性能を上げ、結果として、スループット性能やチップに集積されるトランジスタ数の増加のペースはほとんど減速せず、ムーアの法則の鈍化は抑えられていた。
そのトランジスタ数であるが、1980年ころはトランジスタはロジックに使われたが、1990年ころになると、50%のトランジスタはロジック、50%はメモリに使われるようになった。そして、2000年以降は、大部分のトランジスタはメモリに使われるという傾向になった。
-
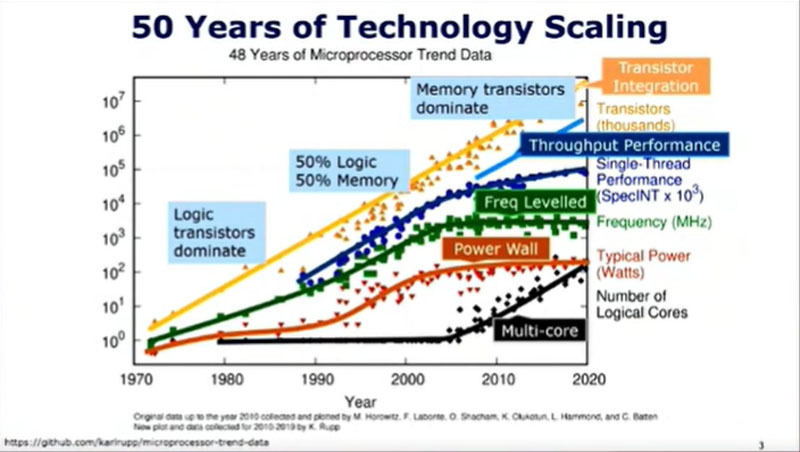
50年間のテクノロジスケーリング。元ネタはStanford大のHorowitz教授

また、ムーアの法則であるが、1980年ころはトランジスタ数が2年ごとに倍増するという本来のムーアの法則でプロセサの性能が上がってきた。1990年ころには、性能の向上は2年間で2倍になるクロック周波数に支えられ、これがムーアの法則と言われた。2000年以降の性能向上はその他の要素で性能を2年間で倍増するペースで伸びており、これがムーアの法則と言われている。
-

2000年ころに消費電力は100Wを超え、これ以上、あまり増やせないという熱の壁に直面し、マルチコアで性能を上げるという方向になった。しかし、2年間で性能2倍というムーアの法則は鈍化していない

左側のグラフは横軸がトランジスタのゲート電圧、縦軸はログスケールで描かれたトランジスタのドレイン電流である。2つの曲線があるが、右側の曲線が普通の使い方で、曲線の右端がトランジスタがオンの状態、左端のY軸と交わる点がゲート電圧がゼロでも流れる漏れ(リーク)電流を表している。
ムーアの法則に立ちはだかった壁とそれを乗り越えた技術
消費電力を減らすために、電源電圧を小さくして、かつ、同じオン電流を得ようとすると、左側の曲線のようにする必要があり、漏れ電流が増える。このグラフはログスケールであるので、漏れ電流は指数関数的に急増する。1μmプロセステクノロジの場合はこの漏れ電流による消費電力はμWレベルであったが、0.35μmプロセステクノロジではmWになり、180nmプロセステクノロジではワットレベルになる。そして、このままでいけば90nmプロセステクノロジでは100Wレベルになってしまう。
下側の棒グラフは各プロセステクノロジ世代の電源電圧を示したものであるが、設計としては100Wの漏れ電流は許容できないので、電源電圧も下げ止まってきた。そうすると、ドレイン電流は増加が止まり、クロック周波数は上がらなくなる。
-
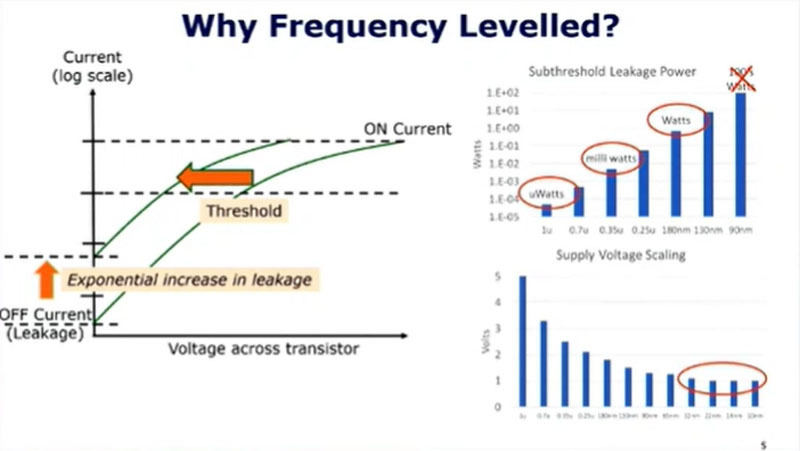
なぜ、クロック周波数は上がらなくなったのか? 電源電圧を下げて同じドレイン電流を流せるトランジスタは漏れ電流が大きくなってしまう。90nmプロセステクノロジでは漏れ電流だけで100Wの消費電力

しかし、半導体プロセス屋も頑張っており、次の図の左の2つの写真のように、NMOSトランジスタはチャネル領域のシリコンを引き延ばして結晶を歪ませてドレイン電流を増やし、PMOSトランジスタは逆にチャネル領域のシリコンを圧縮して歪ませ、ドレイン電流を増やすという方法を編み出した。NMOSは2003年の90nmプロセス、PMOSは2007年の45nmプロセスのころから、これらの歪み技術が使われている。
左から3つ目の写真はゲート絶縁膜にSiO2より高誘電率(High-K)のHfO2などを使い、物理的には分厚いがゲート電圧の影響は薄いSiO2と同様にシリコンに伝わるという技術を実用化した。HfO2の実用化には長い時間が掛ったが、ドレイン電流を増やすことができた。
右端のトランジスタはシリコンのチャネルを薄い板のような形状にして、その上にゲート絶縁膜とゲートを付ける技術で、シリコンのチャネル領域の底部を除く3方向にゲートがあるという構造を作った。この構造は一般にはFinFETと呼ばれたが、Intelは3方向にゲートがあるので、Trigateと呼んだ。この構造は3方向をゲートで囲んでいるので、ゲート電界の影響が効果的に働き、ドレイン電圧を低減しても、ドレイン電流を増やす効果があった。FinFETは2012年の22nmプロセスから量産に使われてきている。
-
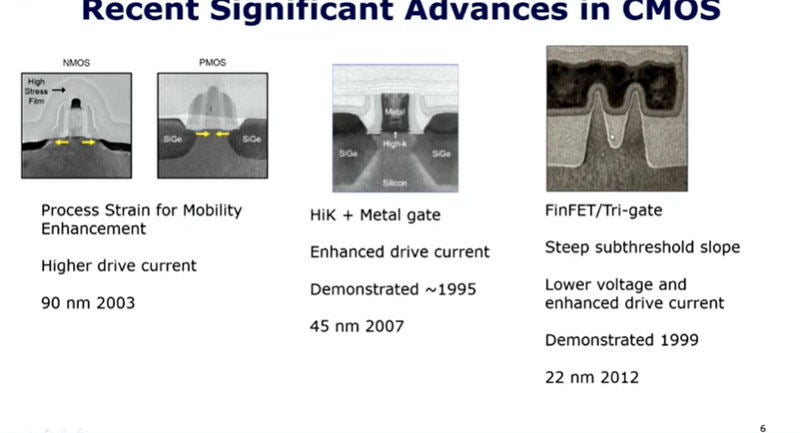
半導体技術者はチャネルのシリコンの引き延ばしや圧縮で電流を増加させる歪みシリコン、高誘電率ゲート絶縁膜、FinFETなどでトランジスタの性能を改善してきた

これからもムーアの法則を維持するために必要な新技術
そしてBorkar氏は、(1)10-20年の長期の目標として、CMOSを置き換える新しいデバイスの開発を上げた。もちろん、それと並行して新デバイスを使う回路やアーキテクチャ、システムの研究も行うべきと考えている。
また(2)の5-10年の中期目標としては、CMOSの強化と新しいシステムの考案、そして(3)の1-5年の短期目標としてはCMOS以外には考えられないが回路を見直し、効率を下げている部分を取り除くことを目標に挙げた。
-
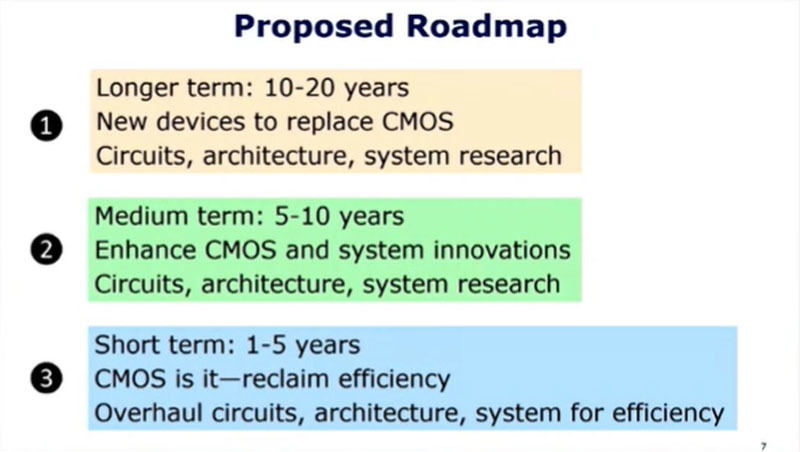
長期にはCMOSに替わるデバイスの研究、中期はCMOSを強化する新規な方法の研究、短期にはCMOSの効率を制限している要因を取り除きCMOSの効率を最大限に発揮させる開発を行うべき

CMOSを置き換える候補として提案されているデバイスは数多くあるが、まだ、CMOSを超えるデバイスは見つかっていない。しかし、このようなデバイスの研究を続けてCMOSを超えるデバイスを作る努力は続けなくてはならない。
-
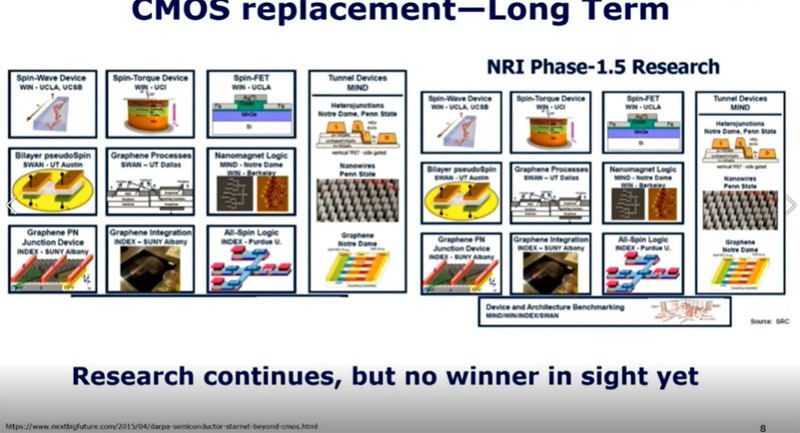
CMOSを置き換えるデバイスの候補として提案されている候補は数多く存在する。しかし、まだCMOSを超えるものは無く、将来、どの候補がCMOSを超える性能を実現するかは分からない

次のグラフは横軸が遅延時間、縦軸が消費エネルギーで、研究開発されている新デバイスがプロットされている。左下に近いデバイスが小さいエネルギーで速くスイッチする望ましいデバイスである。いろいろな動作原理のデバイスが提案されているが、各種の次世代型FETが左下に近いところに並んでおり、他の動作原理のデバイスでこれを超えるには今後、大きな性能向上を実現する必要がある。
-
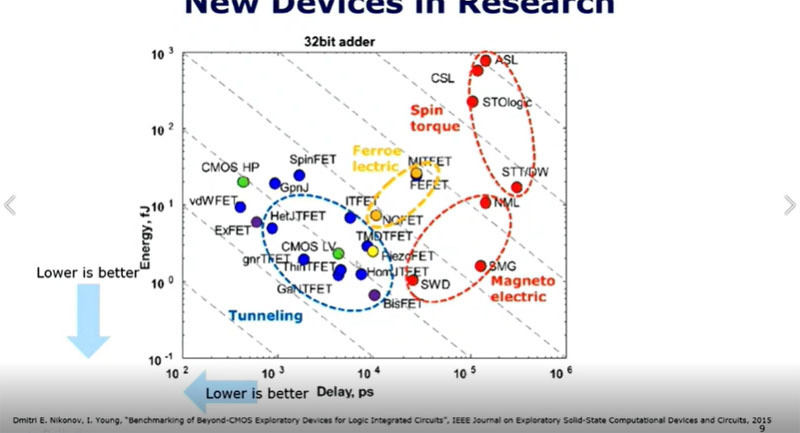
CMOSを置き換えるデバイス候補。横軸は遅延時間、縦軸はスイッチングエネルギー。左下のデバイスが性能が高い。青〇の電界効果トランジスタが性能が高く、どの新デバイスが超えられるのか分からない

5-10年レンジの中期の研究を超伝導のジョセフソン接合(JJ)素子を例にとって考えてみよう(Borkar氏はJJが良いと言っているわけではない)。
JJ素子は信号電圧変化が小さいので、低エネルギーで動作する。超伝導を起こす低温で動作させるため、熱ノイズは非常に小さく、小さな信号振幅でも信号/ノイズ比は大丈夫である。超伝導は動作周波数を高めるには効果があるが、エネルギー低減の効果はない。超低温に冷却するのにエネルギーが必要であるが、超電導の支持者は全体的には必要なエネルギーは小さくなると言っている。しかし、この主張が正しいとすれば低温動作用に設計されたCMOSも同様の利点を持つはずである。
-

超伝導のジョセフソン素子を例にとって考えてみよう。低温でノイズが小さい状態で動作させるので、雑音が小さく、低振幅で動作するので消費電力は非常に小さい。しかし、これはCMOSを超低温に冷却しても同じである

詳細は省略するが、低温用CMOSは、電源電圧を100mV程度に下げ、スレッショルド電圧を~25mV程度にできる。常温に比べてトランジスタは高速で動作し、消費エネルギーを小さくできる。
-

超低温のCMOSもJJと同程度の高速で動作し、非常に小さなエネルギーで動作できる

その結果、超低温動作のCMOSの動作周波数は32倍となり、室温で4GHz動作の設計は100GHz以上で動作する。そして、動作あたりのエネルギーは1/1000になり、32倍の周波数で動かしても、電力は常温動作の半分で45Wで済む計算になる。
-
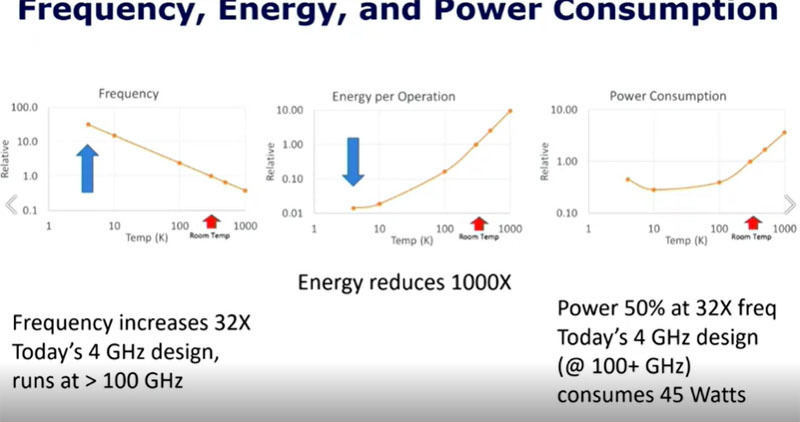
低温のCMOSはドレイン電流が増え、32倍、高速で動作できる。電源電圧を下げられるのでエネルギー消費は1/1000に減る。結果として、32倍のクロックで動かしても45Wの消費電力で済む

デジタル回路のFigure of Merit(FOM)はエネルギーと遅延時間の2乗の積(E×D2)で、小さいほうが性能が高い。超低温CMOSは遅延が~1pSで、エネルギー消費は~1aJ、JJ素子も遅延は1pS、エネルギーは1aJであり、FOMはJJ素子と低温CMOSはほぼ同じである。つまり、低温動作用に作ったCMOSはムーアの法則の寿命を延ばすことができる。
-
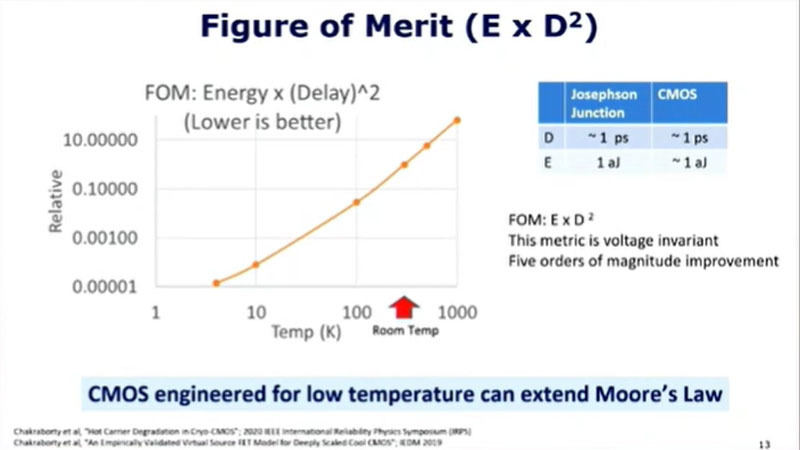
Figure of Merit(FOM)はエネルギーと遅延時間の2乗の積(E×D2)で、JJ素子と超低温CMOSのFOMは同程度

メモリの方も色々な新しい記憶素子が提案されている。SRAM、DRAM、NAND-Flashなどは広く使われている定番メモリで、Spin Torque、Ferro-electric、Magnetic、Resistiveなどのメモリも一部では使われている。
-
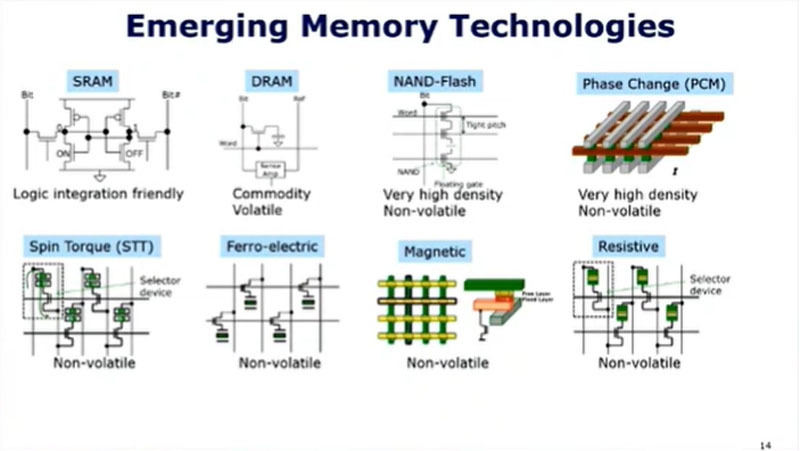
提案されているメモリテクノロジ。SRAM、DRAM、Flashは現在のメインの技術。STT、強誘電体、磁気、抵抗メモリも一部では使われている

次の6つの棒グラフは、これらのメモリのセルサイズ、アレイ効率、密度、サイクルタイム、R/Wエネルギー、書き込み耐性を比較したものである。セルサイズではDRAM、Flash、PCM(Phase Change Memory)などが最小である。一方、アレイ効率(チップ全体の面積の内のメモリの面積)はSRAMが最大で、セルサイズが小さいこれらの3種のメモリはアレイ効率は低くなっており、セルは小さいが、それ以外に面積が必要になっていると思われる。それでもDRAM、Flash、PCMは密度が高いメモリである。
R/Wの速度はSRAMが一番速く、DRAMもそれに次いで速いメモリである。R/WのエネルギーはこれらのアレイではDRAMとFlashはエネルギーが小さい。
不揮発性メモリの書き込み耐性はデータの書き換えができるかという回数で、FlashやPCMは書き込み耐性が低く、外部回路で書き込み回数を平準化するような工夫をして平均寿命を延ばして使用している。
-
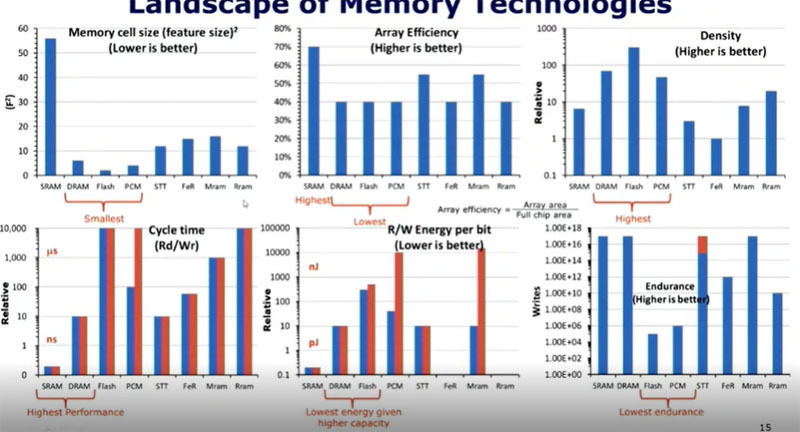
各種メモリのメモリサイズ、アレイ効率、密度、サイクルタイム、R/Wエネルギー、書き込み耐性を比べた棒グラフ

現状のメモリの得点表をまとめたのが次の表で、各種の特性比較を総合すると、SRAM、DRAM、Flashと多分、PCMがこれからの5年の間に使われるメモリとなると考えられる。
-
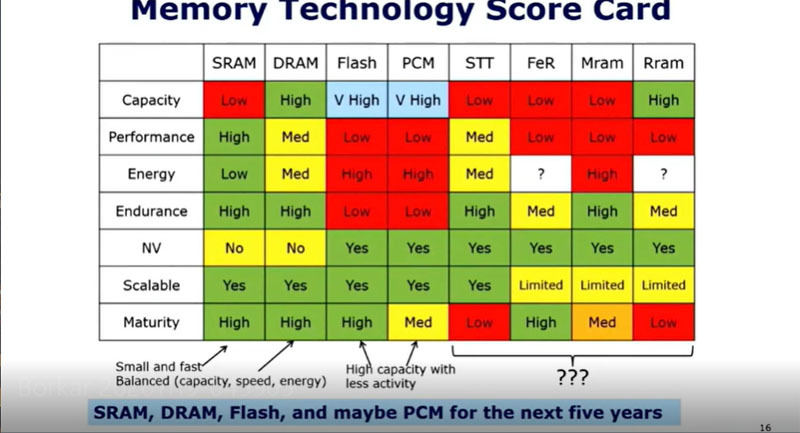
各種メモリの星取表。今後、5年間を見て、SRAM、DRAM、FlashとPCMが使われる可能性が高い

次の図に示すように、1970年代、1980年代から2020年代まで10年ごとにスマートフォンの進歩を実現している原因は変わっているが、10年ごとにプロセサの性能、バッテリ寿命、通信速度、ストレージ容量、使い勝手などが改善され、エンドユーザから見たスマートフォンの価格あたりの価値は2年で倍増している。ムーア氏の述べた素子数増加とは違うが、価値の倍増でムーアの法則を将来に向けて延長しているとみることができる。
この進歩を実現しているのは、マルチチップや3D実装の実用化、ストレージクラスのメモリの実用化、バッテリ容量の増加、5Gなどの高速通信技術の実用化などである。
-

スマートフォン時代のムーアの法則はスマートフォンのユーザ価値を2年で倍増している。この進歩を実現しているのは、マルチチップや3D実装の実用化、ストレージクラスのメモリの実用化、バッテリ容量の増加、5Gなどの高速通信技術の実用化である

プロセサで見ると、キャッシュの搭載、スーパスカラ化による命令の並列実行、アウトオブオーダ実行による命令実行効率の向上、ディープパイプラインによるクロック周波数の向上などの性能向上機構を作るのにトランジスタをつぎ込んできた。次の棒グラフはそれぞれの機構の実装によるチップ面積の増加量と、整数性能、浮動小数点性能、エネルギー効率の増減を示すグラフである。
これらの高性能化機構は、性能を改善しているが、大部分の機構はエネルギー効率を低下させている。右端のグラフのように、簡単なプロセサに戻せば、性能は下がるが、エネルギー効率は3倍程度に改善できる。
-
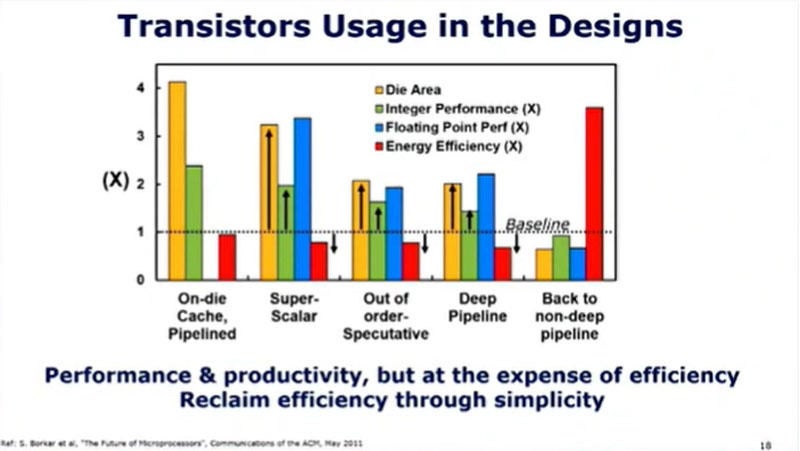
現在のプロセサは性能や生産性のために効率を犠牲にした設計になっている。これらを除けばプロセサのエネルギー効率は3倍になる

次のグラフは色々な機構のエネルギー消費を示すもので、横軸は対数になっている。青色の棒グラフで示す演算命令のエネルギー消費は100pJ以下であるが、64バイトをキャッシュから読んでくるには10倍のエネルギーが必要である。そしてメモリ管理でページを開いてデータを読むという動作は、演算命令の100倍程度の非常に大きなエネルギーを必要としている。また、単純に外部メモリから開かれたページの内容を読むという動作でも、かなり大きなエネルギーを必要とする。
-

プロセサの動作に必要なエネルギー。青色の棒グラフの演算命令は100pJ以下であるが、64バイトをキャッシュから読むには10倍のエネルギーが必要。DRAMメモリから64バイトを読むと100倍のエネルギーが必要

ムーアの法則の延命に向けた3つの案
近い将来でのムーアの法則を伸ばす方法として、次の案が提案された。(1)メモリ階層を考え直し、ソフトウェアにデータローヤリティーが認識できるようにして、(最もエネルギーを消費する)データ移動を減らす。(2)プログラムの生産性のために導入した機構(命令レベル並列実行、仮想メモリなど)の必要性を見直し、マイクロアーキテクチャを簡素化する。(3)エンドユーザにどのような価値を提供しているかを明確にし、価値を倍増するバランスの取れたアーキテクチャを作り上げる。
-

ムーアの法則を短期的に延長するためにやるべきこと。(1)データ移動を減らす。(2)生産性を改善するために付け加えられた機構を簡素化する。(3)ユーザの認める価値だけを効率的に実現する

次の図の上段の4つのグラフは歴代のTop500の1位のシステムのHPLのRmax/Rpeakをプロットしたものである。このRmax/Rpeakは72%である。2番目のグラフは上位の10システムのRmax/Rpeakで、これも70%と左端のグラフとほぼ同じである。3番目のグラフは各種アーキテクチャのプロセサを集めたもので、これも68%とRmax/Rpeakに大きな変動はない。4番目のグラフは各種システムの消費エネルギーをプロットしたもので、平均値は186pJである。
2段目の4つのグラフは分母をRmaxからHPCGの性能に替えたものである。HPCG/Rpeakは左端の歴代Top500の1位のシステムでは平均2.3%で、Top10のシステム、各種プロセサを見ると1.5%や1.4%という値である。
最近の多くの問題では、HPCGの方が計算処理の性質が実際の問題に近いと言われているが、RmaxはHPCGの約50倍の値で大きな開きがある。つまり、Rmaxが2倍のシステムを作ってもHPCG性能は4%程度になるに過ぎないと言える。それならば、Rmaxを引き上げることを犠牲にしても、HPCGの性能を引き上げるアーキテクチャのHPCシステムを作るべきである。このような方法で、実際のユーザの求める性能であるHPCG性能を効率的に倍増することができる。
-
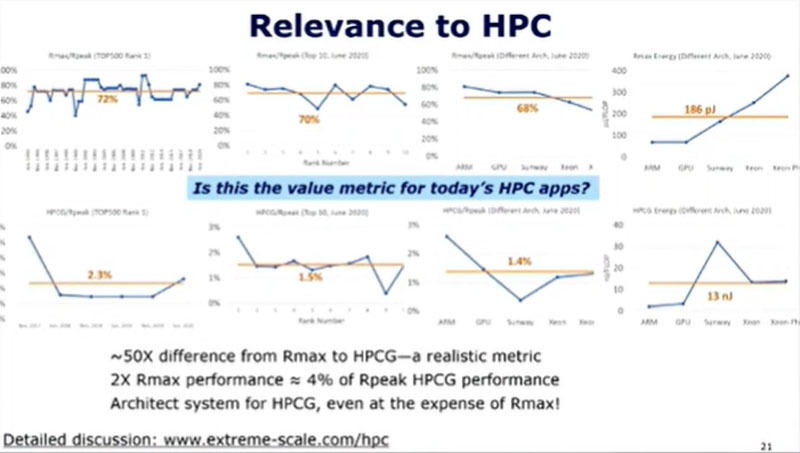
上段の4つのグラフはHPLのRmax/Rpeak、下段の4つのグラフはHPCG/Rpeak。ユーザが求めるのがHPCG性能であれば、HPL性能は犠牲にしてHPCG性能だけを改善するアーキテクチャにすれば効率的である

ムーアの法則は終っていない。一定コストのスマートフォンのバリュー(ユーザにとっての価値)を2年ごとに倍増するという形でムーアの法則は続いている。そして、このバリューの倍増を継続するためには、長期的にはCMOSを置き換えるデバイスの開発、中期的にはCMOSを補強する画期的な方法の研究、短期的には効率を下げているものを取り除いて効率を上げる研究を行うべきである。HPCの分野では、何がバリューであるのかを考え直し、HPCに役立つシステムを作るということを同氏は提案していた。
-

ムーアの法則は2年ごとに同じコストで2倍の価値をユーザに提供するという形で続いている。CMOSに替わるデバイスの研究、CMOSを強化する研究、短期的にはCMOSの性能を制約する要素を取り除く研究を行うべきである。HPCについて言うと、ユーザが価値と考えるものは何か? それを効率的に提供することを行うべきである