|
|
SC16でAuroraを発表するNECの百瀬氏 |
NECが「Aurora」というプロジェクト名で次世代スパコンを開発していることはすでに発表されていたが、その実体はベールに包まれていた。今回のSC16で、NECはそのベールを少し持ち上げてチラリと中身を見せた。SC16での発表を行ったのは、NECのITプラットフォーム事業部のAuroraプロジェクト担当プリンシパルエンジニアの百瀬真太郎氏である。
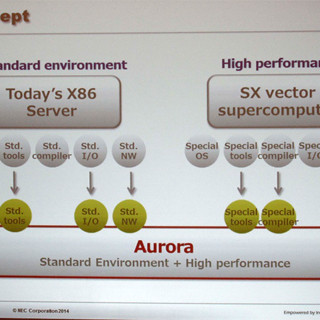
NECは1983年に発表したSX-1以来、30年以上にわたってベクトル型スパコンを開発し続けてきた。その最新の製品が「SX-ACE」であり、3代目の地球シミュレータは、SX-ACEベースのシステムである。 そして、今回発表されたAuroraは、SX-ACEの次世代となるNECのスパコンエンジンである。

|
|
NECは1980年代から一貫してSXシリーズのベクトル型スパコンを作り続けてきた。最新のマシンはSX-ACEで、Auroraはその次の世代にあたる (このレポートのすべての図は、百瀬氏の発表スライドを撮影したものである) |
例えば、毎サイクル倍精度浮動小数点数の加算を行なおうとすれば、8バイトの入力データが2個必要となり、結果が1個生成される。これをすべてメモリで賄おうとすると1演算に24バイトのメモリバンド幅が必要になる。ベクトルレジスタを使えば、メモリアクセスは減らせるが、それでも4バイト/Flop程度のメモリアクセスは必要というのがベクトルスパコンに常識であった。
一方、スカラプロセサでは、キャッシュを持たせるのが一般的で、メインメモリのバンド幅は富士通の京コンピュータで0.5バイト/Flop程度、Xeonでは0.25バイト/Flop程度と小さくなっている。これは、演算器を多数搭載するのに比べて、高バンド幅のメモリバンド幅を大きくするのは高くつくからという理由もある。
この結果、NECのスパコンは、メモリバンド幅リッチなマシンとなり、他の大分部のメーカーのスパコンは演算器リッチなスパコンとなっている。
NECは、次の図のようなHPCGベンチマークを使った演算効率や演算/電力の比較の図を使うが、HPCGはメモリアクセスは効くが、ピーク演算性能はほとんど効かないというプログラムである。従って、メモリリッチなNECのSX-ACEがHPCGの場合、ピーク性能の11.3%と圧倒的に高いスコアをマークし、電力効率では113GFlops/Wと、これも圧倒的に高いエネルギー効率を出すのは、ある意味、当然である。
しかし、TOP500のランキングに使われるHPLはメモリ性能はあまり必要でなく、ピーク演算性能が効くプログラムである。両方のベンチマークを作ったJack Dongarra教授が、HPLとHPCGはブックエンドの両端というように、どちらも、ある程度高い性能が得られるのが望ましい。
重要なのは、実アプリケーションでの性能がどうなるのかであるが、それはユーザがどのようなアプリケーションを実行するかに依存する。NECスパコンのユーザはメモリ性能が重要というアプリケーションを主に実行するということであれば、NECスパコンを使うことは正しい選択であると言える。
一方、0.5バイト/Flop程度のメモリ性能があれば良いアプリケーションの場合は、富士通のスパコンを使った方が、価格性能比では安上がりであると思われる。

|
|
HPCGベンチマークでの演算効率と性能/電力 |
プロジェクトAuroraを紹介するロードマップスライドは次の図のようになっている。NECは、LXシリーズというx86ノードを使うクラスタ型スパコンを持っているが、Auroraのロードマップでは2018年に登場するAuroraがSX-ACEのベクトルスパコンの流れと、x86ベースのLXシリーズの両者を統合するように書かれているところが注目に値する。
ただし、LXシリーズはドイツで開発されており、社内ポリティックスも絡むので、技術的な判断だけで統合が実現するのかどうかは分からない。

|
|
このロードマップでは、AuroraはSX-ACEの後継であると同時にLXシリーズの後継でもあり、両者を統合するように書かれている点が興味深い |
次の図は、Auroraのアーキテクチャを説明するもので、現在のSXスパコンとの大きな違いは、左側にx86 CPUが付いた点である。そして、現在は、ベクタエンジンの中にあるSPEでSuper-UX OSを動かしているのであるが、Auroraではx86 CPUでLinuxを動かすという方式に変わる。

|
|
Auroraでは、x86 CPUを使い、Linux OSを動かす。I/Oなどはx86が処理し、ベクタエンジンは演算に専念する |
そして、Linuxの下で動かすVE softwareがベクタエンジンにプログラムを実行させる。プログラム環境はx86のLinux上で動かし、標準のFortran/C/C++をサポートする。また、NEC伝統の自動ベクトル化をサポートする。
このx86とベクタエンジンのペアが計算ノードで、大規模システムを構成するネットワークにはInfiniBandを使用する。

|
|
Auroraはx86 CPU+ベクタエンジン。OSはx86上で走るLinuxとなる |
ベクタエンジンの仕様であるが、倍精度(DP)の演算性能は150GFlops/Core以上となるとのことである。また、単精度(SP)の演算性能は、2倍の300GFlops/Core以上である。そして、メモリバンド幅は150GB/s/Core以上となっている。
NVIDIAのP100 GPUのSM(Streaming Multiprocessor:TOP500ではこれをコア数と数えている)は96GFlopsであるので、Auroraのコアはその1.5倍余りの性能を持つ強力コアである。ただし、P100は現在出荷しているのに対して、Auroraは2018年登場となっているので、時期の違いを考えると、必ずしも優位とは言えない。
NECはVEチップに何コアを集積するかは明らかにしていない。SX-ACEのVEチップは4コアであり、Auroraでは8コアとか16コアになるのではないかと思われるが、P100は56コアであるので、ピーク演算性能では追いつかない可能性が高い。
P100はHBM2メモリを使い、720GB/sのメモリバンド幅を実現しているが、コアあたりにすれば、12.9GB/sに過ぎない。この点ではAuroraは圧倒的に強力である。結果として、メモリと演算のバランスは1バイト/Flopとなり、富士通のスパコンが0.4~0.5バイト/Flopであるのと比べるとメモリリッチな構成となっている。

|
|
ベクタエンジンの演算性能はDPで150GFlops/Core以上。メモリバンド幅は150GB/s以上になる |
VEのモックアップが展示されたが、背の低い大型のヒートシンクがプリント板の大部分を覆っている。この下に、VEチップとメモリが置かれる筈であるが、メモリの容量などは明らかにされていない。
そして、右側にはファンが付き、ヒートシンクに強制的に空気を送る構成になっている。これも、ハイエンドのGPUボードを思い出させる。

|
|
VEボードの外観 |
そして、1Uの薄型サーバシャシーにx86 CPU 1個とベクタエンジン2基を搭載する。

|
|
ラックマウントサーバでは、x86 1個に2台のベクタエンジンを接続する |
製品としては、タワー型のデスクトップサーバ、ラックマウント型のサーバ、そしてスパコン用には専用ラックを使う実装形態を考えているとのことである。

|
|
製品としては、デスクトップサーバから、ラックマウントサーバ、ハイエンドのスパコンまで、幅広い展開を計画している |
まとめであるが、AuroraはベクトルプロセサをPCI Expressカードに搭載し、PCIeでベクタエンジンをx86 CPUに接続するというアーキテクチャをとなる。
そして、これまでのSuper-UXではなく、x86で動くLinux OSを使う。Linux環境で動かすFortran/C/C++コンパイラに、NECの自動ベクトル化技術を入れていく。VEのベクトルプロセサは、高演算性能のビッグコアで、コアあたりのメモリバンド幅は非常に高い。

|
|
AuroraはVEをPCIボードに搭載し、x86 CPUとPCI Expressで接続する。そして、OSやI/O処理はx86で実行する形態となる |
ベクタエンジンは、コアあたりのメモリバンド幅が非常に大きいNEC伝統のベクトルプロセサであるが、CPUとVEの接続はPCIeであり、データ伝送の速度がネックにならないか心配である。この部分に、NVIDIAは独自により高速のNVLinkを開発している。
また、メモリリッチなVEが、役に立つ使い方をユーザにアピールできるかが大きな問題で、例えば、ディープラーニングやビッグデータ処理でNVIDIAのシステムを上回るコストパフォーマンスを示すというようなことが必要ではないかと思われる。