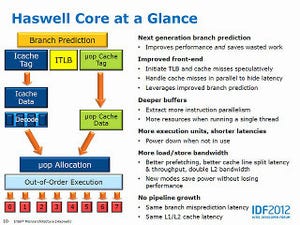
前回(記事はこちらのリンク)は省電力の話までしたので、今回は拡張命令系に関して。
AVX2
Sandy Bridge世代で初投入されたAVXであるが、Haswellではこれを大幅に性能改善すると共に、FMA(Fused Multiply and Add)命令を追加した。このFMAに関しては、AMDのSSE5というか、XOP(eXtended Operations)、正式には"128-Bit and 256-Bit XOP, FMA4 and CVT16 Instructions"を意識した感じもある。ただFMAそのものは初代のAVXで搭載されており、これを拡張した形になる。
むしろ差は性能改善の方が大きい。Photo01がざっくりした対比であるが、Haswell世代では浮動小数点演算性能がSandy Bridge世代から倍増している。この性能改善を表にしたのがこちら(Photo02)。この性能改善にはLoad/Storeユニットの強化が必要であり、その結果として64Bytes/cycleのLoadと32Bytes/cycleのStoreの能力がHaswellに搭載された事になる。

|
Photo01: AVX2はAVXの帯域増加+若干の新命令、と考えればわかりやすい。 |

|
Photo02: FMAに関しては後述。要するに今までだと2命令を要していたので合計8cycle掛かっていたのが、今度からは1命令で出来るようになったので5cycleで済むようになったという話。 |
このあたりをもう少し細かく説明したのがこちら(Photo03)。AVX2は、AVX命令を浮動小数点演算に拡張した、とでも言えば良いのだろうか? これを図で示したのがPhoto04・05である。Sandy BridgeのAVXは、レジスタこそ256bitに拡張されたものの、演算ユニットそのものは128bitのままで実装されていたが、Haswellでは全てが256bit拡張された形だ。

|
Photo03: 例えば従来も整数演算のFMAは可能だったが、今回から浮動小数点演算のFMAもサポートされた。またSSE2/SSSE3/SSE4系命令も統合されたことで、AVX2はほぼ完全にSSEのSuperSetになった形だ。 |

|
Photo04: なのでSandy Bridgeの場合、AVX命令はまず上位128bit分、次いで下位128bit分を演算することになっており、256bit分を一度に計算できるとしながらも性能そのものはSSEと同じでしかなかった。 |

|
Photo05: すべての演算ユニットを256bit幅に拡張したことで、所要時間を半分に減らせることになり、これが演算性能が倍になった要因である。 |
もう少し細かく見てみよう。FMAとはA=±(A×B)±Cを計算するもので、演算結果が元のデータを上書きする、所謂FMA3(3オペランドのFMA)命令である(Photo06)。フォーマットはこんな形(Photo07)で、またオペランドが即値なのかレジスタなのかアドレスなのか、に応じて命令オーダーが3種類あるわけで、これだけで20×3=60命令ということになる(Photo08)。ただIntrinsicはシンプルであり(Photo09)、後はコンパイラが最適なものを自動選択するという話であった。このFMAの効果として、多項式を展開するケース(Photo10)では、FMAを使わずに済ませた場合と比較してLatency/Throughput共に高速化できるという例も示された。

|
Photo06: FMM3、というからにはFMA4(4オペランドのFMA)も存在するが、とりあえずAVX2のFMAは全部FMA3の模様。 |

|
Photo07: この手の命令を見るとき、加減算でそれぞれ命令を分けるのはどこまで効果的なのかちょっと考えることもある。勿論係数の符号反転に1命令余分に掛かるのは無駄ということなのだろうが、中には計算に応じて動的に係数の正負が変わるケースもあるわけで、本当にここまで命令を増やす必要があるのか、よく判らない。 |

|
Photo08: このあたり、自由にSrc1/2/3を選択できるようにさせるとデコーダの負荷が大きすぎるのでこうなったのだろう、とは想像できる。 |

|
Photo09: Intrinsics(組み込み関数)は確かにこのフォーマットに帰着する(というか、これが一番楽であろう)。 |

|
Photo10: 2次の多項式だと、まずax+bをFMAで計算、この結果をもう一度FMAで計算するという2回の演算で済む。他方FMAを使わないと、乗算を2回と加算を2回することになり、効率が悪いという話。 |
次がGather Instruction(Photo11)である。直訳すれば「かき集め」であるが、Photo12が多少判りやすいだろう。このGather Instructionは8つ、Intrinsicは4つが用意される(Photo13)。

|
Photo11: 32bitもしくは64bit単位で、指定されたIndexの値にあわせてメモリから値を取り込み指定されたYMMレジスタに格納するというもの。 |

|
Photo12: これはちょっと複雑な、マスク付のもの。ymm0で指定された順番に、EAXの指定したアドレスからデータを取ってきてymm1に格納するというもの、ただしymm2でマスクが指定され、これが0だとymm1の値は変更されない。 |

|
Photo13: Index SizeがIntとFPで分かれているのがちょっと面白い。仕組み的には別に区別の必要は無いように思うのだが。 |
Gatherとはまた異なる、細かなデータ置き換え命令がこちら(Photo14)である。例えばPer Element Variable Vector Shiftsの例がこちら(Photo15)。またBit Manipulationに関しても15種類(こちらもデータサイズに応じて各々複数が用意されるので、命令数は40ほどになる)ほどある。ちなみにこちらの命令はAVXレジスタではなく汎用レジスタ向けである。その他、Rotate命令が若干変更された(Photo17)ほか、MOVBE及びTSX命令が追加された(Photo18)。

|
Photo14: Gatherとは別に様々なデータに対する操作命令をまとめたのがこちら。 |

|
Photo15: これは要素毎にShift演算を行うが、どれだけShiftを行うかも個別に指定できる。 |

|
Photo16: さすがにもう個別の説明は省くので、興味がある方はIntelのサイトから"Intel Architecture Instruction Set Extensions Programming Reference"を入手していただければと思う。このドキュメントに、今回追加された命令の詳細が示されている。 |

|
Photo17: この命令は、仮想86モードやリアルモードでは動作しない64bit専用命令となっている(32bit値の場合でも)。 |

|
Photo18: TSXはこの後説明する。MOVBEは、所謂Endianの変更。SoC的な使い方をする場合、x86系で利用されるLittle Endianではなく、旧68Kなどで広く使われているBig Endianのデータを扱う可能性が増えるため、データのEndian変更は組み込み系ではごく当たり前に要求される。ARMなどの場合、CPUの起動時にEndianをどちらにするか変更できるものもある。 |
で、TSXに話を移す前にコンパイラのサポートについて。今回の追加された命令はIntelCompiler 12.1以降、及びgcc 4.7/binutils 2.22以降でサポートされることになる(Photo20,21)ほか、Microsoft Visual C++でもVisual Studio 2012以降ではNativeにサポートされることになる(Photo22)。またTSXに関しては現状Haswellしか利用できないため、これを使うためには_declspec(cpu_specific())を使い、ここでfuture_cpu_21を宣言してその中で記述する形で区別が必要、という話であった(Photo22)。

|
Photo19: また新しいコンパイラオプションが追加されることになった。 |

|
Photo20: とはいえ、実際にはIntrinsicあるいはインラインアセンブラを使うのが現状必須というのは、当面はまぁ仕方ないところか。future_cpu_21は後述。 |

|
Photo21: ただFMAのサポートなどは現状不十分で、フルに使えるようになるのはSP1なり次のメジャーアップデート待ちといったところか。 |

|
Photo22: 理屈はともかく、なんでこんなシンボル名に…… |
次ページ:TSXについて