前回のGTCに続き、今回のGTC 2019でもCitadel SecuritiesからマイクロベンチマークでTuring GPUのアーキテクチャを解剖するという研究結果が発表された。Citadel Securitiesはいわゆるセキュリティの会社ではなく、社名のSecuritiesは株や投資信託などの証券のことである。
CitadelはMarket Makerで、証券取引所が開いていない時間でも株式の売買を受け付ける大手の証券会社である。売値を高めに、買値を安めにすれば売買で損をすることは少なくなるが、投資家はCitadelで売買をして手数料を払ってくれなくなる。逆に、売値を安め、買値を高めにすれば、投資家には歓迎されるが、売買で損をしてしまう。したがって、株価の予測の精度が高く、株価を短時間で投資家に提示できることが重要である。この点でCitadelのスピードは定評がある。
このため、CitadelはGPUを使って、これらの計算を加速することに力を注いでいる。今回の論文を発表した人たちは、CitadelのHigh Performance Computing R&D Teamという所属になっており、高性能の計算を仕事にしている人たちのようである。
第一著者のZhe Jia氏の写真を取り忘れてしまったが、中国から来られてまだ半年程度の短期間しか米国におられないとのことであったが、流暢な英語で発表され、大したものであった。
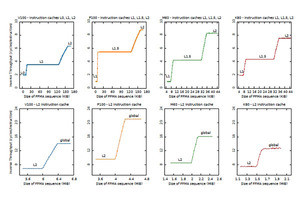
Citadelのチームはマイクロベンチマークと呼ぶGPUの機械命令で書いた小さなプログラムをいろいろと作り、これらを実行させて実行時間を測ることで、GPUがどのような構造になっているのかを推測している。しかし、プログラムを作るには、マイクロアーキテクチャを仮定する必要があり、仮定したマイクロアーキテクチャを測定するプログラムを作って実測し、仮定が正しかったかどうかを検証するという作業の繰り返しであり、手間のかかる作業であったと思われる。
しかし、Citadelのチームは、マイクロアーキテクチャがどうなっており、どう動くかを正しく理解しないとGPUの最高性能は引き出せないという考えで、Turingのマイクロアーキテクチャの調査を行っている。
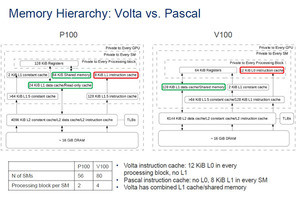
なお、TuringではリアルタイムレイトレーシングのためのRTコアの追加が大きな改良点であるが、この機能はCitadelが必要としている数値計算の機能ではないので、この調査では対象に入っていない。
なぜGPUのアーキテクチャを調査するのか
CUDAライブラリは、かなり人手によるチューニングが施されており、ピーク性能の90%以上の性能が出ている。しかし、すべてのケースで最適になっているわけではない。NVCC(NVIDIAのCコンパイラ)は柔軟性があるが、計算バウンドのカーネルの場合、生成されるコードの性能はピークの80%程度である。
したがって、本当に性能が重要な場合は、NVIDIAがCUDAライブラリでやっているように、人手でチューニングを行いたい。
-

CUDAライブラリは、人手でチューニングされており、ピークの90%以上の性能。NVCCで作った場合は80%程度の性能。このため、本当に性能が問題になる場合は、CUDAライブラリのように人手でチューニングしたい (本連載の画像はGTC2019にてCitadel Securitiesが発表したスライドのコピー)

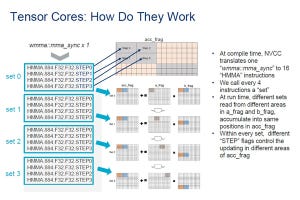
NVCCで作ったプログラムで性能が出ないケースの大部分は、メモリバンド幅を最大限使っていない。あるいは、命令のスループットを最大限使っていないというケースである。これらの資源を使い切って最高の性能を実現するためにはGPUのローレベルのアーキテクチャの理解が必須である。今回は、例1として単精度のa*X plus Yの計算と例2のマトリクスの乗算を使って説明がなされた。なお、例1はメモリバウンドの処理、例2は計算バウンドの処理である。
-

最高性能が出せないのは、メモリバンド幅を使い切っていない、命令スループットを使い切っていないというケースが多い。これらを使い切るにはローレベルのアーキテクチャの理解が必須である

次回は、この2つの例の説明を行う。
(次回は4月9日に掲載します)