
◆Sandra 20/21 31.139(グラフ92)
Sandra 20/21 31.139
SiSoftware
https://www.sisoftware.co.uk/
-
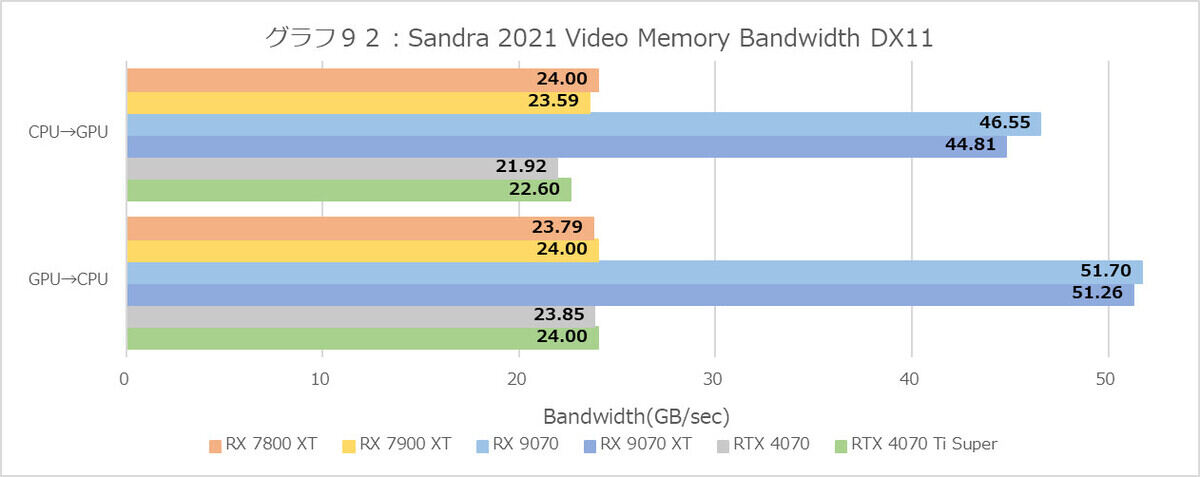
グラフ92

さてここからはゲーム性能以外の部分を。まずはSandraだが今回はVideo Memory Bandwidthのみである。要するに先のグラフ3と同じくPCIe経由での帯域の確認である。結果はご覧の様に、Radeon RX 9070シリーズはそれ以外の製品の倍の転送性能を発揮しており、間違いなくPCI Express Gen5が動作している事が確認できた。
◆HandBrake 1.9.2(グラフ93)
HandBrake 1.9.2
HandBrake
https://handbrake.fr
何でHandBrakeか? というと、これはMedia Encoderの性能比較である。これまでだとTMPGEnc Video Mastering Works 7を使うのが常なのだが、今回Radeon RX 9070シリーズで利用しようとしたところ、こんなエラーが出て実行できなかった(Photo50)。
-

Photo50: そういわれても...

恐らくなのだが、Radeon RX 9070シリーズに対応した新バージョンのAMD Media SDKを利用してTMPGEnc Video Mastering Works 7のビルドをやり直す必要があるのだと思われる。同種の事は過去にもあった。TMPGEnc Video Mastering Works 7は今年2月6日にVersion 7.1.1.36が公開されており、これを利用したのだが残念ながらまだ未対応の模様だ 。
ということで他のツールを探したところ、現状でRadeon RX 9070が動作したのがHandbrakeだった、という話である。
ベンチマーク方法だが、元データ(VP9フォーマット、4K30fps、11296フレーム)をAMD及びNVIDIAのMedia Encoderを利用してHEVC(10bit HEVCフォーマット、4K30fps、Constant Quality Level 24、Main 10 Profile)に変換する時間を測定した。TMPGEncだとバッチを使って同時に複数Streamのエンコードが可能だったが、今回HandBrakeで同じ環境を実現する事ができなかったので、1streamだけでのエンコードとなっている。
-

グラフ93

グラフ93がその結果だが、ご覧の通りあまり芳しくない。恐らくだが、HandBrakeもまだRDNA 4のMedia Encoderに未対応(そもそもVersion 1.9.2は今年2月23日にリリースされたもので、最新のAMD Media SDKを利用しているかどうかも疑わしい)で、互換モードで動作しているためにその性能が発揮できていないのではないか? と考えて居る。この辺は今後、アプリケーションの対応が済んだ段階でないとちゃんと確認出来ないようだ。
とりあえず現状としては、動くには動くが、最適化されていないという結果となってしまった。
◆AIDA64 v7.60.7300(グラフ94)
AIDA64 v7.60.7300
FinalWire Ltd.
https://www.aida64.com
AIDA64にはBuild inのGPGPU Benchmarkが搭載されている。Sandraにもあるのだが、以前も書いたがこちら2023年末を境にメンテナンスが成されなくなっており(なんせトップページ https://www.sisoftware.co.uk の最新の話題は2023年10月末、ベンチマーク自身のバージョンも2023年12月30日リリースの31.139が最後となっている)、まともに動かない事が増えて来たので、今回はAIDA64の方を利用してみた。
-
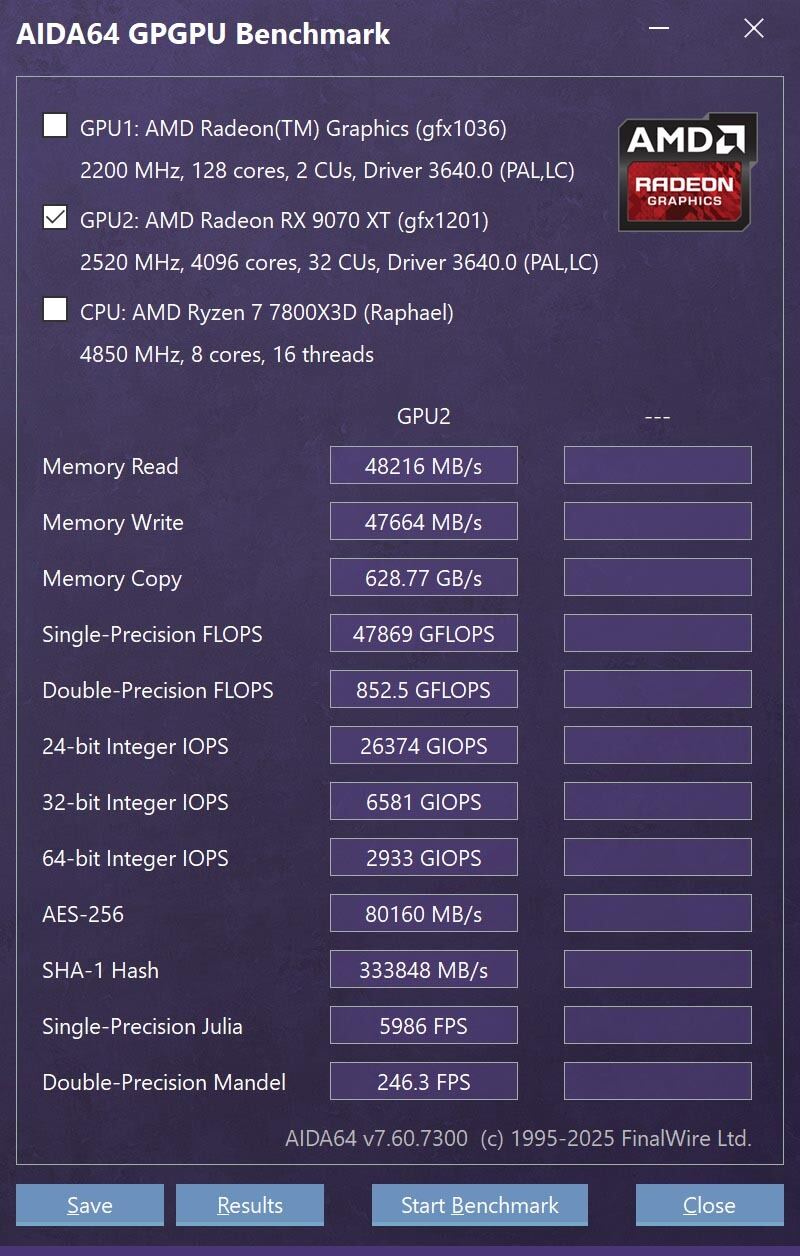
Photo51: CPUのベンチマークとしても使えるのが珍しいといえば珍しいところ。あと内蔵GPUも選択できる。

さてAIDA64のGPGPUベンチマークはこんな具合(Photo51)に12項目で実施する様になっている。実際は12ではなく、例えばMemory ReadでもPinnedとPageableでそれぞれ測定を行うし、Memory Copyは15/32/64/128/256/512/1024MBの7パターンで実施して、平均をとるといった具合。Single-PrecisionならFMA Float 1/2/4/8/16とFMAC Float 1/2/4/8/16を実施しての平均値といった感じに全部で100項目のテストを行い、これを12項目にまとめて示している格好だ。ただ結果はご覧の通り、12項目がそれぞれ別の単位で出力されるのでグラフにまとめるのが難しい。なので生の結果は表2に示し、グラフ94はRadeon RX 7800 XTの結果を100%とした相対性能グラフとさせていただいた。
| ■表2 | RX 7800 XT | RX 7900 XT | RX 9070 | RX 9070 XT | RTX 4070 | RTX 4070 Ti Super |
|---|---|---|---|---|---|---|
| Memory Read(MB/s) | 25845 | 25943 | 48187 | 48286 | 24758 | 24930 |
| Memory Write(MB/s) | 25988 | 26025 | 47503 | 47521 | 25385 | 25354 |
| Memory Copy(MB/s) | 840450 | 933553 | 696487 | 643540 | 960711 | 1145055 |
| Single-Precision FLOPS(GFLOPS) | 38436 | 54928 | 39584 | 47841 | 31959 | 45810 |
| Double-Precision FLOPS(GFLOPS) | 647.5 | 968.4 | 699.0 | 852.2 | 502.4 | 714.0 |
| 24-bit Integer IOPS(GIOPS) | 19504 | 28975 | 21105 | 26370 | 16015 | 23074 |
| 32-bit Integer IOPS(GIOPS) | 5210 | 7650 | 5465 | 6586 | 16019 | 23068 |
| 64-bit Integer IOPS(GIOPS) | 2288 | 3403 | 2415 | 2930 | 3853 | 5623 |
| AES-256(MB/s) | 62840 | 91938 | 66621 | 80157 | 56302 | 81166 |
| SHA-1 Hash(MB/s) | 175096 | 269652 | 238891 | 333852 | 132112 | 165459 |
| Single-Precision Julia(FPS) | 4823 | 6679 | 4936 | 5977 | 6164 | 8846 |
| Double-Precision Mandel(FPS) | 197.6 | 289.3 | 214.6 | 246.7 | 143.3 | 197.3 |
-

グラフ94

結果を見ると、まずMemory Read/WriteにおけるRadeon RX 9070系の性能の高さが目立つが、その割にMemory Copyが妙に遅いのはどういうことか? あと32bit/64bitのInteger IOPSでGeForce RTX 4070/4070 Ti Superの性能が突出しているが、これは生データを見ても本当に突出しているので、恐らくはGeForce RTXではTensorRTを使って処理しているのではないか? という気がする。ただそれを除くと概ね理解できる性能になっている。しいて言えば、Radeon RX 7900 XTが84CU×2000MHz(Game Frequency)、Radeon RX 9070 XTが64CU×2170MHz(Game Frequency:Photo11参照)だが、RDNA 4ではSIMD VectorがDualになっているので、本来ならSingle Precisionの性能とかはRadeon RX 9070 XTの方が60%位高速になっていてもおかしく無いにも関わらず、実際にはRadeon RX 7900 XTの方が高速な結果になっているというのは、ベンチマークがRDNA 4対応になっておらず、RDNA 3相当の動き方をしているという事なのだろうか?SHA-1 Hashの性能とかが本来想定される性能に近い気がする。アプリケーションのRDNA 4への最適化作業が結構広範に必要、ということなのかもしれない。
◆PCMark 10 v2.1.2704(グラフ95~100)
PCMark 10 v2.1.2704
UL Benchmarks
https://benchmarks.ul.com/pcmark10
-

グラフ95

-

グラフ96

-

グラフ97

-
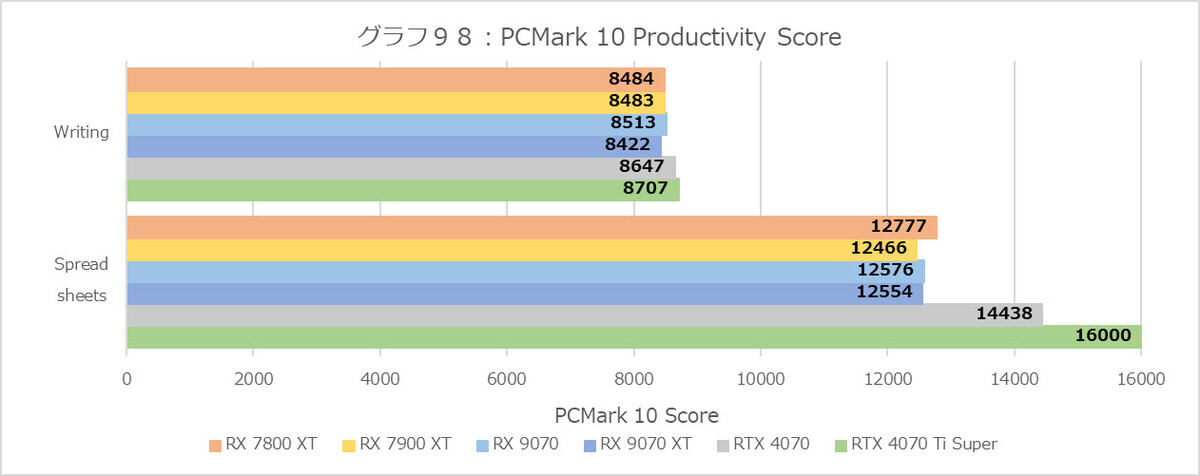
グラフ98

-
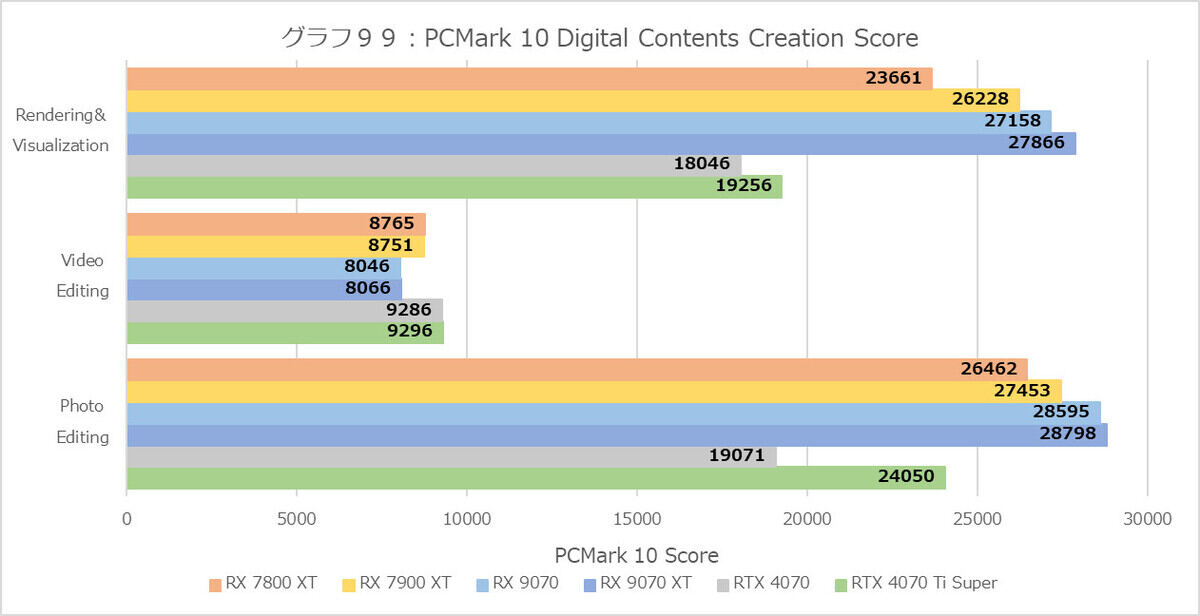
グラフ99

-
グラフ100

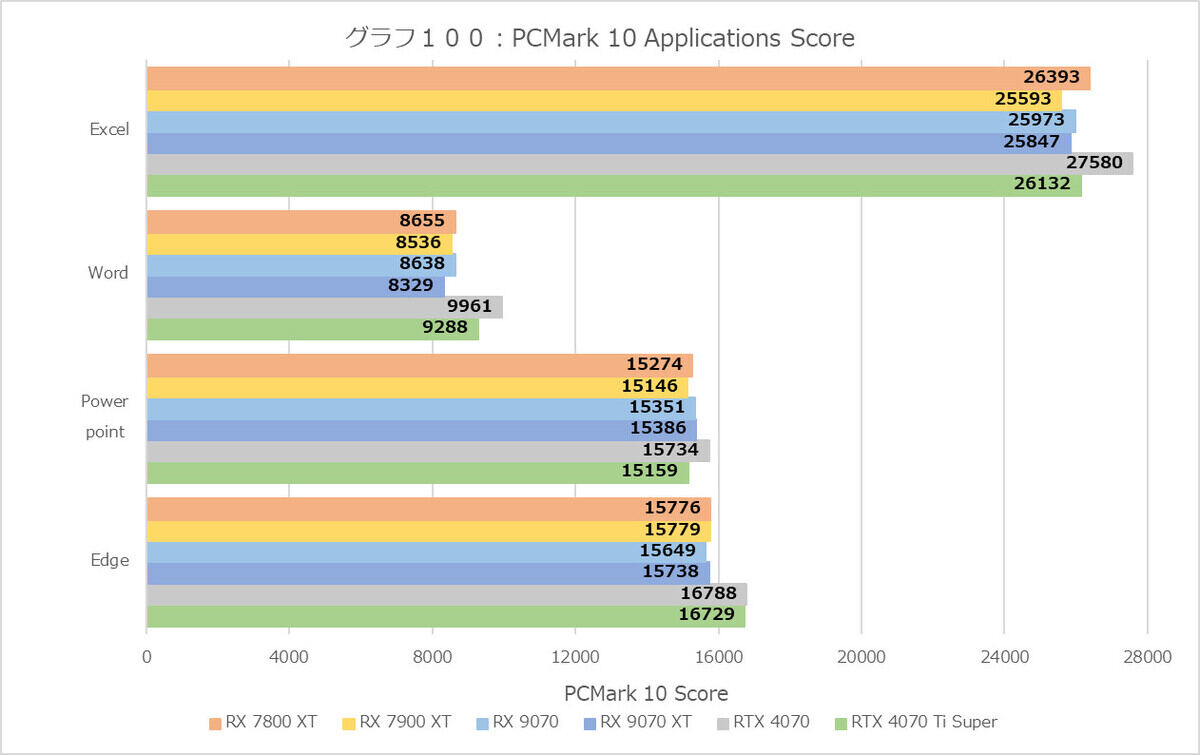
OpenCL周りの確認も兼ねて、普通にGPUとして使えるという確認のためにPCMark 10も実施してみた。基本的にここでは大差ない筈で、実際Overall(グラフ95)を見てみるとそんな感じ。Test Group(グラフ96)を見ると差がついているのはDigital Contents CreationとGaming(要するに3DMark Firestrike)である。Essentials(グラフ97)ではApp Startupで妙にGeForce RTX 4070系が遅いが、その分Web Browsingで盛り返している。そしてProductivityではSpreadsheetでGeForce RTX 4070系が高い性能を出している。
まずApp Startupは確かにGeForce系が遅い(例えばWriterのCold StartはRadeon系が1.4秒弱のところ、2秒強を要している)。一方Web Browsingは、殆どのテストは同等だがShopLoadのテストでややGeForce系のロード時間が短いといった違いが見られる。Productivity(グラフ98)では、特にOpenCLを利用したSpreadsheetMonteCarloOclなどで処理時間が劇的に違う(Radeon系が平均2.2秒、対してGeForce RTX 4070が1.5秒、GeFoce RTX 4070 Ti Superは0.68秒)事が大きな要因となっている。
ではOpenCLだとGeForceの方が高速か? というとそういう単純な話でもない。Digital Contents Creation(グラフ99)を見ると、まずRenderingAndVisualizationは3DMark Slingshotのスコアがそのままだから仕方ないとして、例えばPhotoEditionDenoiseOcl(OpenCLベースの写真のDenoise)の処理時間は、Radeon系が0.18秒前後なのにGeForce系は0.37~0.57秒と2~3倍の時間を要しているなど、得手不得手が確実に存在している。結果から言えば、グラフ95のPCMark 10 Score(ExtendedはFireStrikeが入るから怪しくなる)が示すように、「普通に使うにはあまり差が無い」として良さそうだ。グラフ100(Office365での性能)もこれを物語っている。
◆Procyon v2.10.1542(グラフ101~107)
UL Benchmarks
https://benchmarks.ul.com/procyon
最後はProcyonだが、実はこのProcyonは昨年4月には生成AIを利用した画像生成、昨年11月にはLLMを利用したテキスト生成もサポートした。要するにStable DiffusionやLlamaなどの性能を比較できる様になったということだ。なので最後にこうしたAI性能の比較をしてみたいと思う。
-
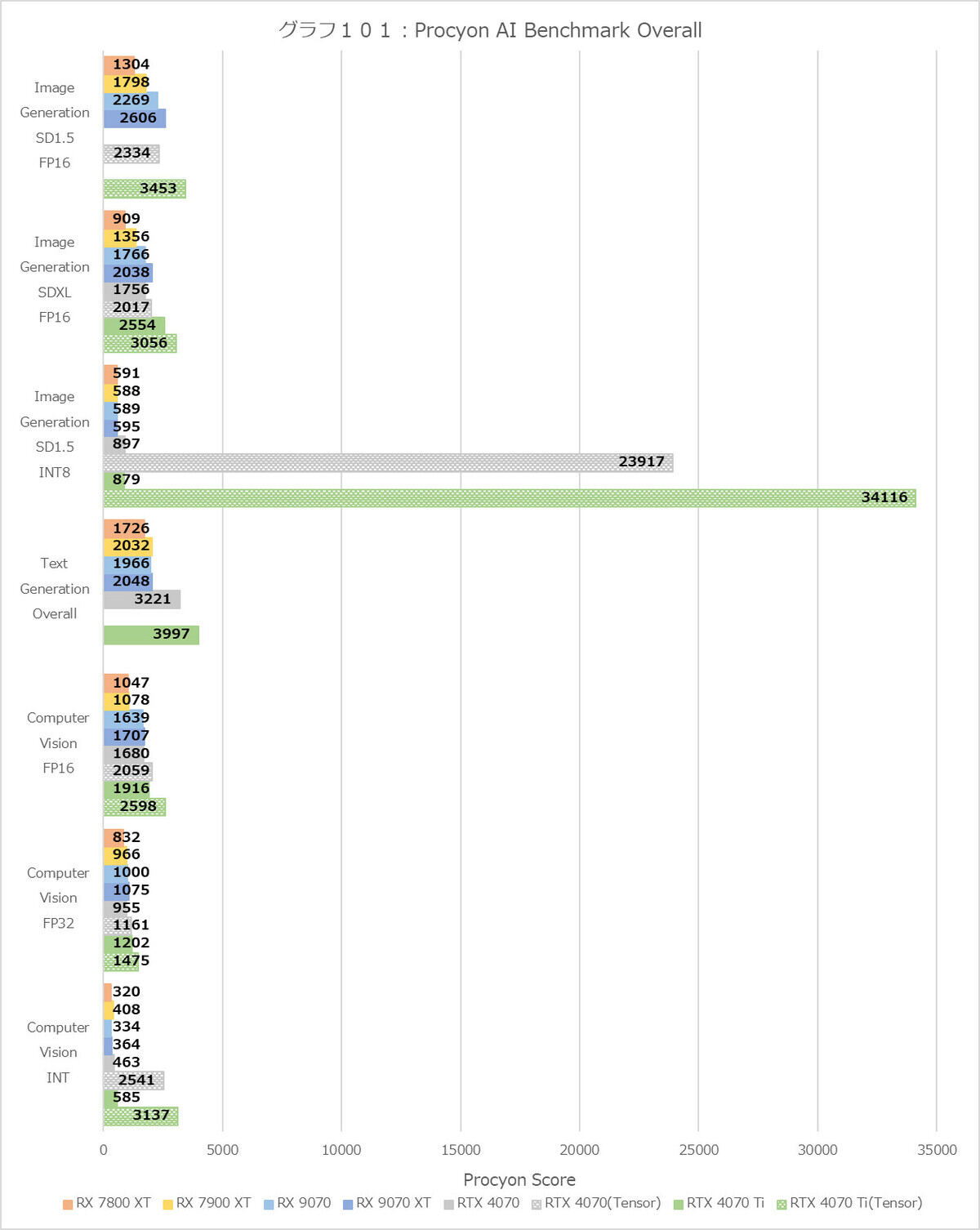
グラフ101

グラフ101がOverallである。グラフがちょっとバグっているのは、GPUによって利用できるInference Engineが異なるためである。これは特にImage Generationが判りやすく、Stable DiffusionでRadeon系はONNXしか利用できないのに対し、GeForce系はONNXとTensorRTが選択できる(一部ONNXで動作しないものもある)。それもあってGeForce系ではONNXとTensorRTの両方の結果を示している。これはComputer Visionも同じで、Radeon系はWindows MLでのみの動作だが、GeForce系はWindows MLとTensorRTの両対応となっている。そんな訳でこれまでより結果の項目が多い訳だが、特にGeForce系でStable Diffusionを実施するのはONNXを使うよりもTensorRTを使う方が圧倒的に高速であり、その結果がこのグラフという訳だ。もっともここまで性能差があるのはStable Diffusion 1.5でINT 8を利用した場合のみで、他のケースではもう少し穏当な性能差になっていることが判る。
-
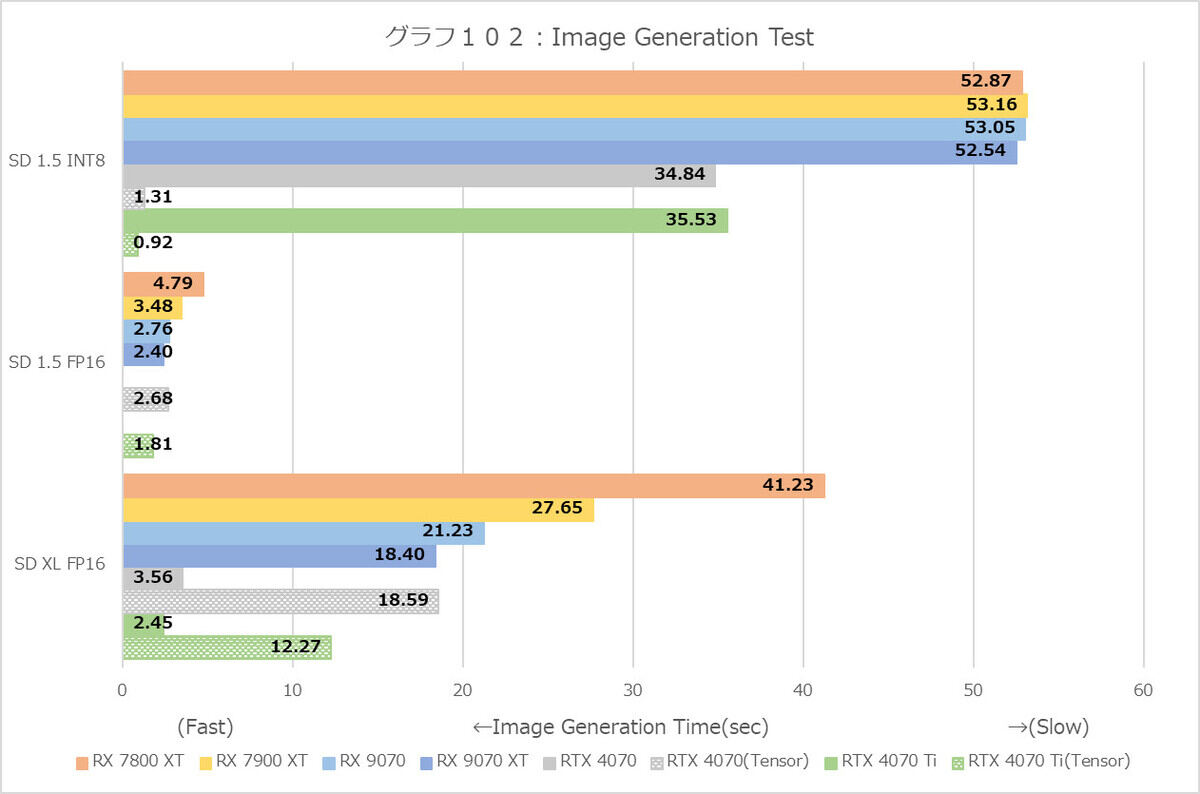
グラフ102

ということで個別に結果を見てみたい。まずそのImage Generation(グラフ102)。結果は画像生成時間で、なのでバーが短いほど高速である。もうここではRadeon系が不利なのは判り切った事で、Stable DiffusionのINT8だと概ね1枚52秒掛かっているのが、GeForceだとONNXを使っても35秒、TensorRTだと1秒前後でしかない。
ただ同じStable Diffusion 1.5でもFP16を使うと大分差が縮まる(ちなみに何故かGeForce系はONNXでFP16が使えないのでTensorRTのみ)。またGPUによる性能差が出るのがStale Diffusion XLで、こちらはFP16のみだがRadeon RX 9070/9070 TiはRadeon RX 7800 XT/7900 XTに比べて大きく処理時間を減らしている。といってもまだGeForce RTX 4070/4070 Ti Superには遠く及ばないのだが。面白いのはそのGeForce系で、ONNXを使った方が高速なことだ。どうしてこうなるのだろう?
次がText Generationである。こちらではONNX RuntimeかOpenVINO Runtimeだが、推奨はONNXということでこちらで統一している。このText GenerationはTTFT(Time to First Token)と(OTS)Output Token Speedの2つからスコアが決まり、
TTFT_Score=C1÷Average TTFT
OTS_Score =C2×Average OTS
Score=√(TTFT_Score×OTS_Score)
と算出される。C1/C2は係数で、これは利用するモデル(Phi-3.5/Mistral-7B/Llama-2-13B/Llama-3.1-8B)毎に決まっている(こちらに詳しい数値が示されている)。
-

グラフ103

-
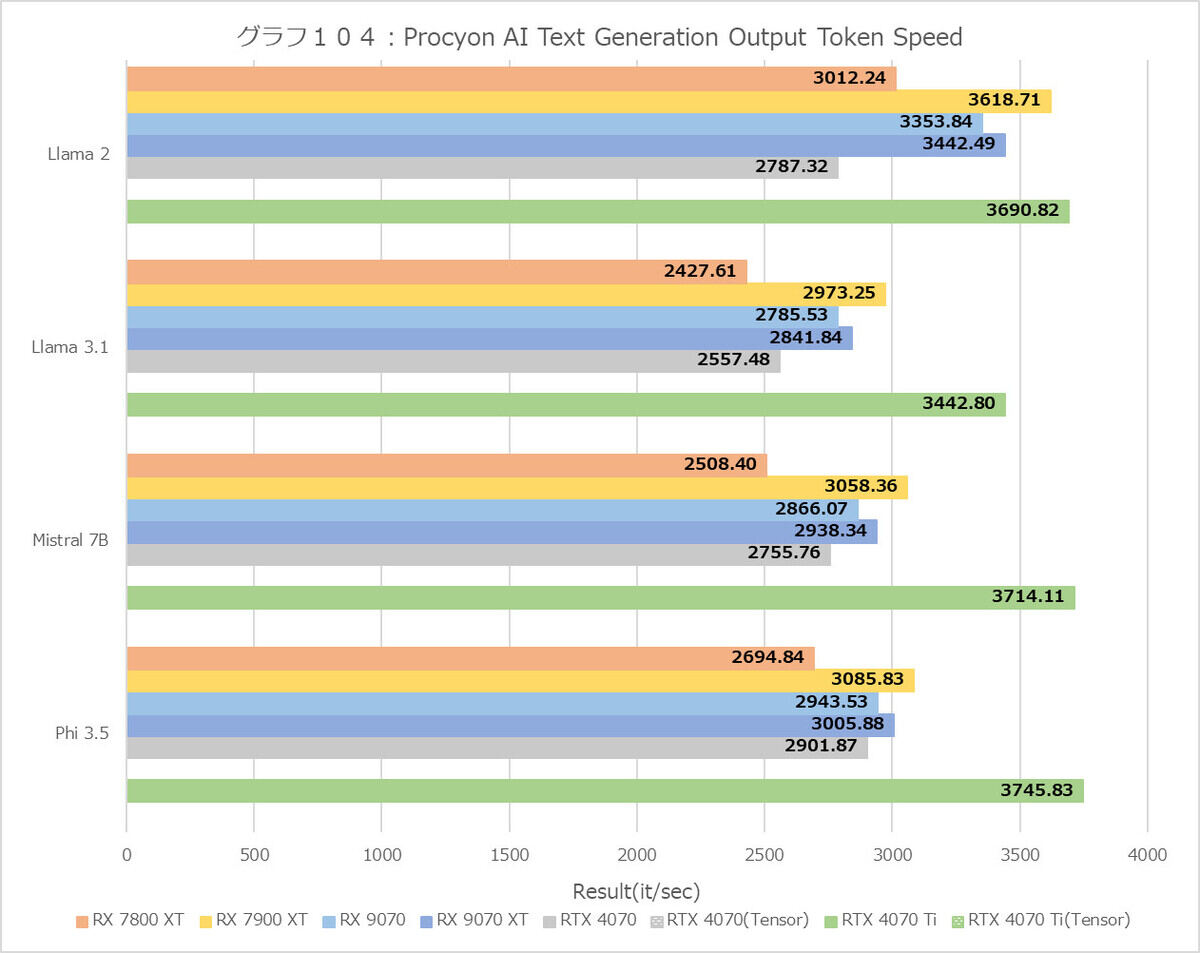
グラフ104

ということでグラフ103にTTFTの、グラフ104にOTSの結果をそれぞれ示してみた。結果から言えば、OTSに関して言えばRadeon系も結構健闘してはいるのだが、TTFTではGeForce系の敵ではなく、結局これがスコアに響いて結果的に大差を付けられて負けという格好である。それはともかくとしてRadeon RX 9070/9070 XTは健闘してはいるものの、Radeon RX 7900 XTに及ばないのは単に最適化の問題なのか、それとも構造的な問題なのかは現時点でははっきりしない。この先最適化が進めばもう少し性能が改善するかどうかも不明である。少なくともテキスト生成という用途で言えば、Radeon RX 7900 XTとさして変わらない(とは言えRadeon RX 7800 XTよりはマシ)というあたりだろうか?
-

グラフ105

-

グラフ106

-
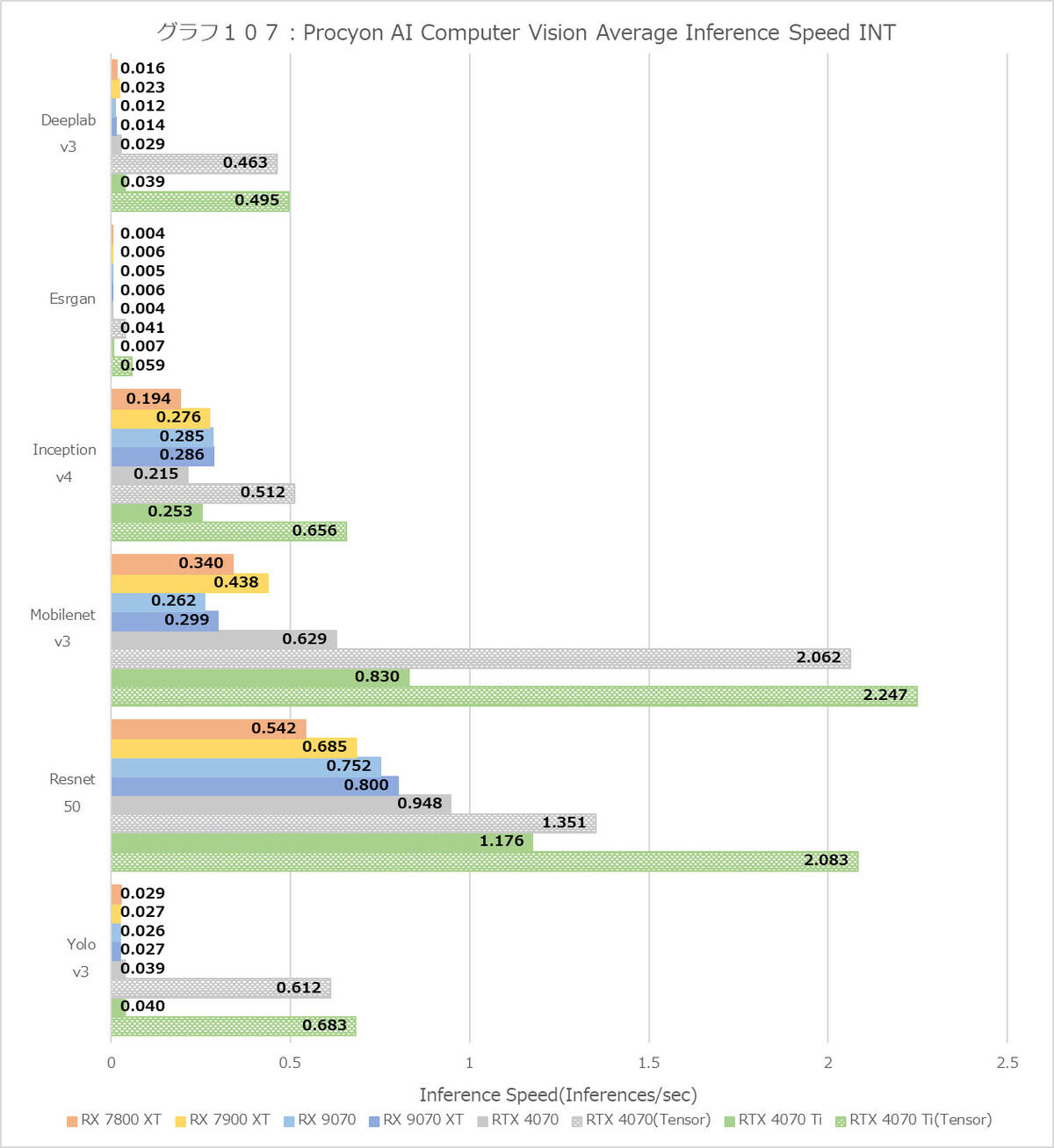
グラフ107

最後がComputer Visionである(グラフ105~107)。スコアは6種類のModelのそれぞれのAverage Inference Timeの相乗平均の逆数で計算されるのだが。そのInference Timeをそのまま示しても見にくいので逆数を取って速度(つまり毎秒当たりのInference実行数)を示してみた。
Modelによって結果に大きな違うがある訳だが、それでも全体としてGeForce系が圧倒的に有利、というのはComputer Visionでも同じである。ちなみにRadeon系はWindows ML、GeForce系はWindows MLとTensorRTの両方の結果を示しているが、そのWindows MLであってもGeForce系の方が有利というものが少なくない。ただそれでも例えばINTのInception v4とかFP16/FP32のMobilenet v3やFP32のResnet 50の様に、時々勝負になるケースも無くはないが、全体としてはやはり勝負にならない。
ただその中でRadeon RX 9070/9070 XTの性能は? というと、少なくともRadeon RX 7800 XT/7900 XTよりは改善しているものは多い。恐らくであるが、これもWindows MLのRadeonへの最適化がちゃんと行われれば、もう少し性能は改善しそうな気がする。その意味ではまだアプリケーションの最適化待ちの状態から変わらない、というのが結論になるだろう。








