
Intelは8月13日(米国時間)、オンラインにてIntel Architecture Day 2020を開催、ここで様々な製品についてのロードマップのUpdateを行った。この模様はビデオでも参照できる(トータル2時間42分)が、本稿では取り急ぎプロセスとプロセッサ/GPUのパートだけ要点をかいつまんで、まずはご紹介したい。
Process
既存の10nmプロセス(Photo01)に対し、トランジスタの改良(Photo02)やInterconnectの改良(Photo03)により、10nm++は10nm+と比較して18%近い性能改善が出来た、とする(Photo04)。この新しいFinFETとSuperMIM(新しい配線層)を組み合わせたものはSuperFinと呼ばれ、2021年の製品に投入されるとの事だ(Photo05)。更にその後(2022~2023年?)には、更に改良したEnhanced SuperFinが投入される予定とされている(Photo06)。
-

Photo01: SAQPによるパターニングとかInterconnectへのコバルトの採用、更にCOAG(Contact Over Active Gate)の利用など、技術的には随分難易度が高いもののオンパレードであった。

-

Photo02: やはりゲートピッチは少し緩められる事になったそうだ。また、プロセスにも若干改良があるようだが、詳細は不明。

-

Photo03: 層間接続(VIA)の抵抗を3割減らしたとするが、具体的には不明。Hi-K材料の厚みを更に減らしたのも改良点とされる。

-

Photo04: ちなみに筆者はCannon Lakeを10nm、Ice Lakeを10nm+、Tiger Lakeを10nm++としているが、Intel的に言えばCannon Lakeは無かったことになっていて、Ice Lakeが10nm、Tiger Lakeが10nm+らしい。

-

Photo05: Rajaの着ているシャツがなかなかいい(笑)

-
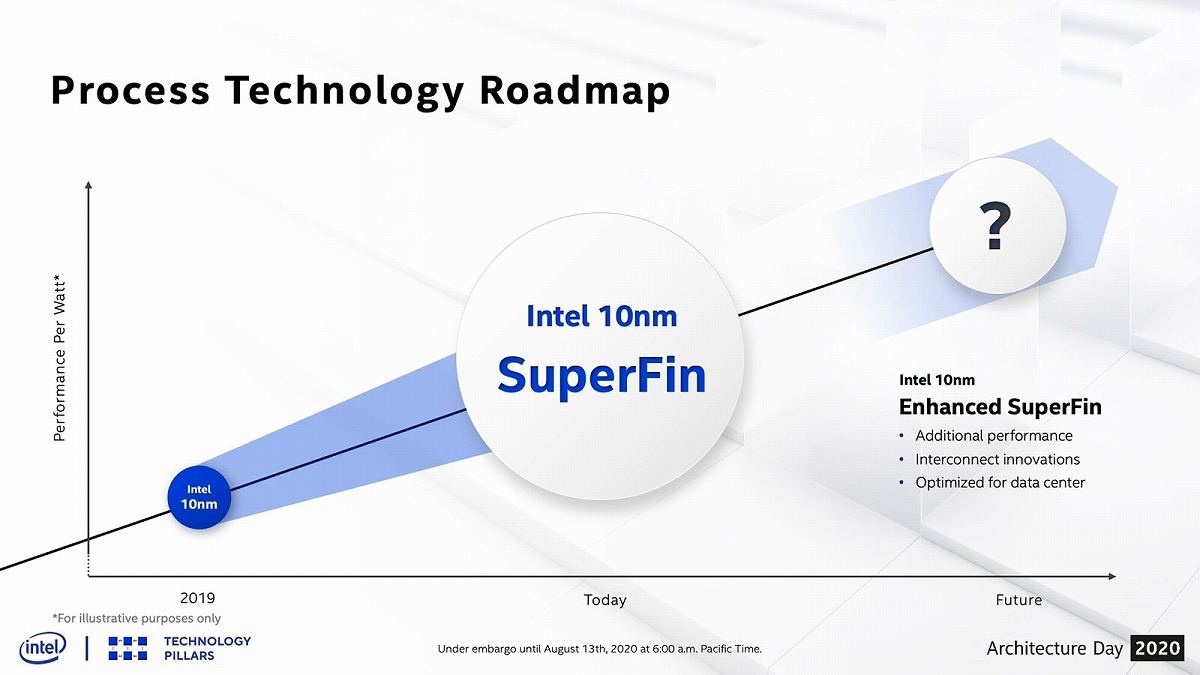
Photo06: Interconnect Innovationsが気になるところだが、今のところヒントはない。EUVを使うつもりなら色々方法はあるのだろうが。

次にPackage。既にEmbedde Bridgeまでは実用化されている(Photo07)。ここで利用されているAIB(Advanded Interface Bus)であるが、AIB 2.0の開発が進んでおり、より広帯域かつ高密度な実装が可能とされる(Photo08)。またSRAMへTSVを利用した積層という新しいパッケージオプションも開発中(Photo09)との事だ。将来は、バンプピッチを10micron未満、転送エネルギーを0.05pJ/bitに抑えるものを提供予定としている(Photo10)。更にGNA 2.0を新しく搭載したとされる。
-
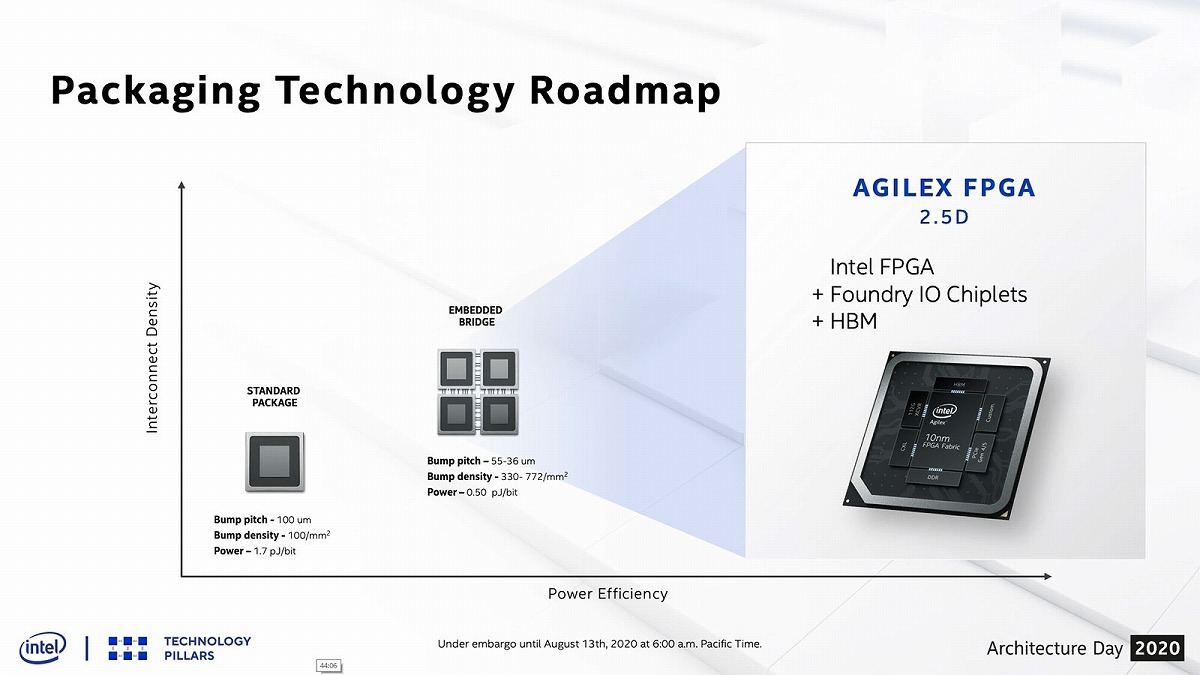
Photo07: Embedded BridgeはAgilex FPGAで実用化されている。また、2021年に投入予定のPonte Vecchioにも利用されるだろう。

-

Photo08: 帯域が大幅に増えるほか、密度も上がる。またI/O Voltageとして0.4Vをサポートし、これを利用すると転送エネルギー節約になるとされる。

-

Photo09: DRAMではなくSRAMなのがポイント。

-
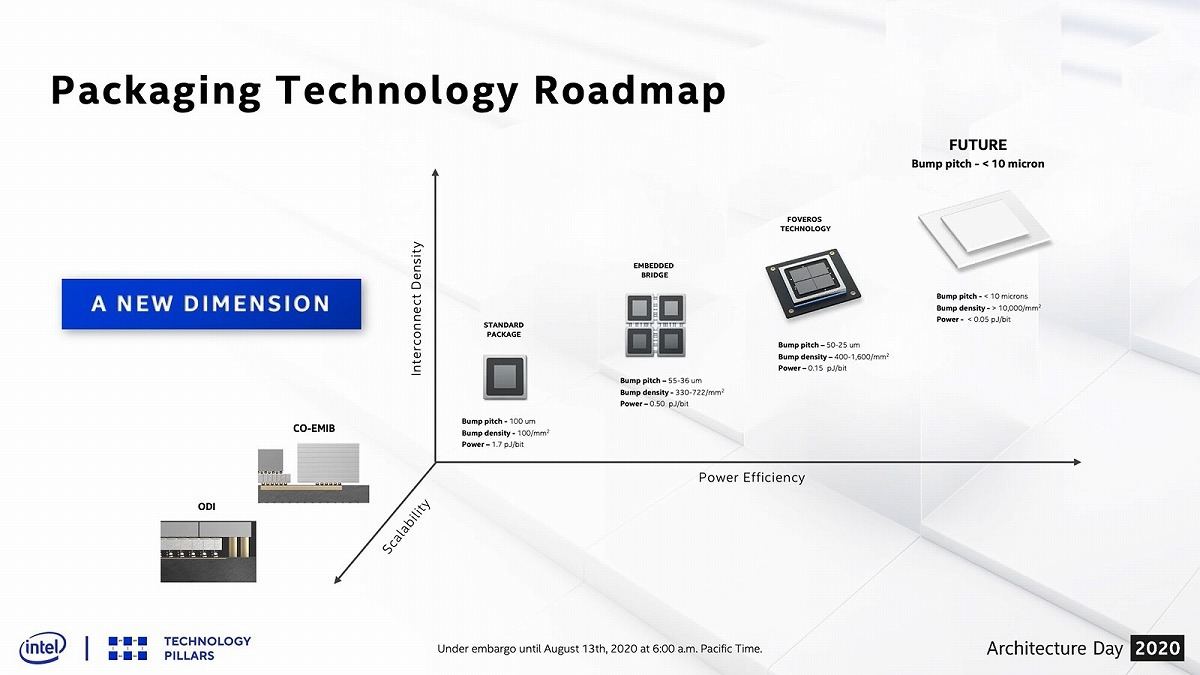
Photo10: もっとも「提供予定」というよりは「目標」あるいは「願望」かもしれないが。









