
GPU
Raja Koduri氏の指揮の元に開発されているX^e GPU(Xe GPU)であるが、今回そのブランディングが公開された(Photo20)。最初に投入されるのはTiger Lakeに内蔵されるX^e LP(Xe LP)であるが、先に触れたように96EU構成(Photo21)で、また動作周波数もGen11に比べて大幅に向上&高効率になっているとする(Photo22)。
-
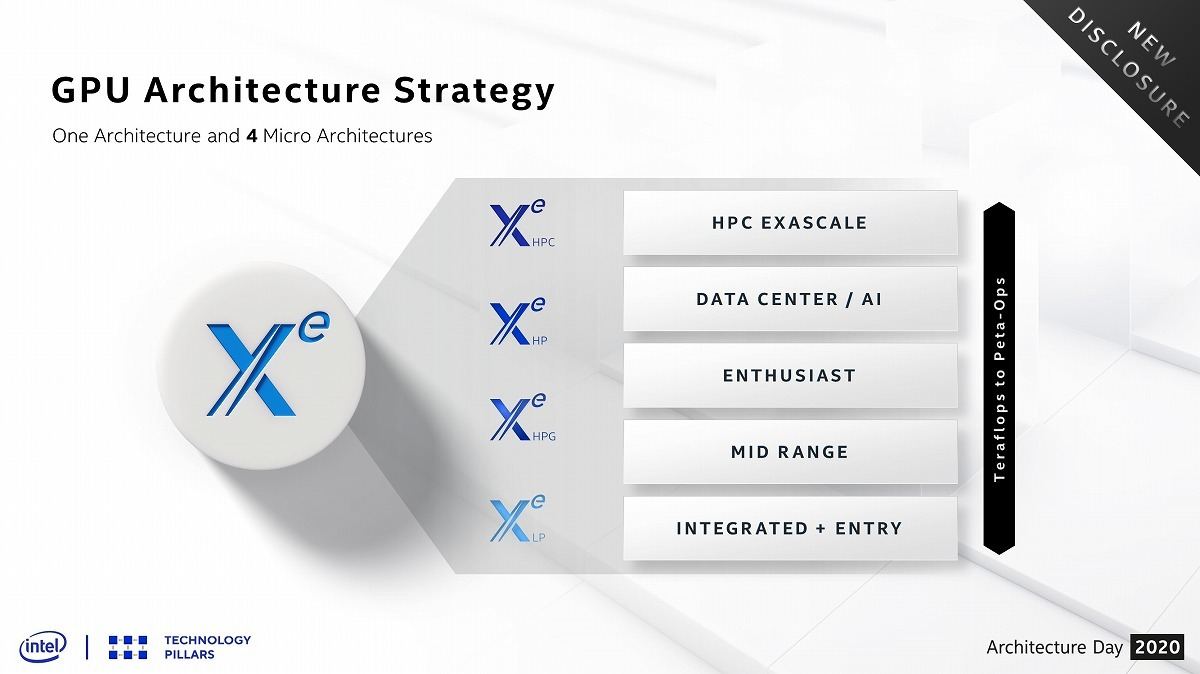
Photo20: 統合GPUがX^e LP、Discrete GPUがX^e HPG、AI向けがX^e HP、HPC向けがX^e HPCということになる。

-

Photo21: 全体が3つのSliceに分かれ、各々が2つのSubsliceから構成されるという構造になっている。

-

Photo22: 先ほどのPhoto12と併せてみると興味深い。やはりこれも10nm SuperFinの効果が大きいのだと思われる。

各々のEUは8wideのFP/INT ALU(32bit×8 or 16bit×16。他にINT 8もサポートするそうだ)構成となっている(Photo23)。また先にPhoto17でGPUのL3は3.8MBと書いたが、これはTiger Lakeの場合の話で、技術的には最大16MBまでのL3が実装可能だとする。
-

Photo23: EMというのはExtended Math ALUの略で、これは特殊演算向け。これはFPU/INTのパイプラインとは並行して動作するそうだ。

Media Codecは従来比で2倍のスループットになっているとする(Photo24)。Display Engineは最大4出力に対応した(Photo25)。このX^e LPはTiger Lakeの他、今年1月にお披露目されたDG1、更にサーバー向けのSG1という製品も用意されることが明らかにされた(Photo26)。このSG1はサーバー向けの顧客の中で、Media Encoderを使いたいといったニーズがあり、こうしたものに応えた製品ということだそうだ。
-
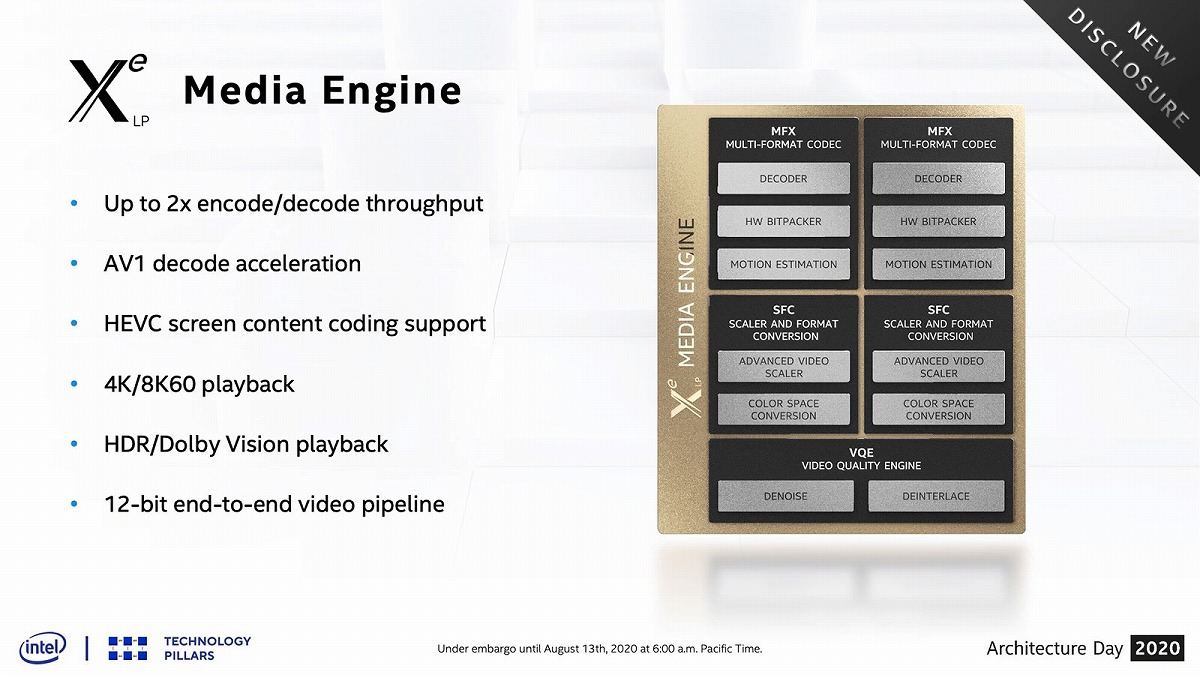
Photo24: 12bit end-to-endのビデオパイプラインが実装された。またHEVCのScreen Content Codingもうまく使えれば効果そうである。

-

Photo25: 最大360Hz出力とかDual eDPとかは結構使い出がありそうである。

-
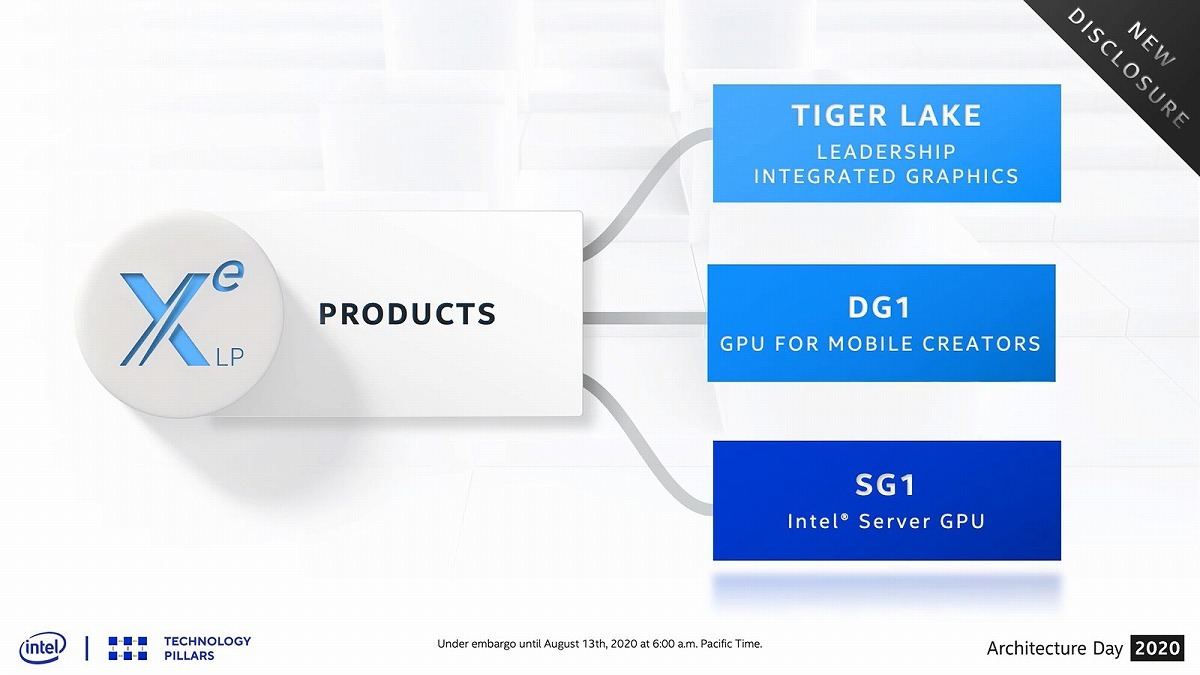
Photo26: DG1の話はこちらの記事を参照。

次がX^e HP(Xe HP)だが、こちらは1/2/4 Tileの構造の製品が用意される(Photo27)。Koduri氏が6月25日にTwitterに投稿したものは、この4 Tileのサンプルと思われる。今回、このサンプルを利用してのピーク性能が示された(Photo28)。ラフに言って1Tileあたり10.5TFlops。4Tileで42TFlopsとなる。

Photo27: この4 Tileのものが人間の手のひらと同程度のサイズである。
-
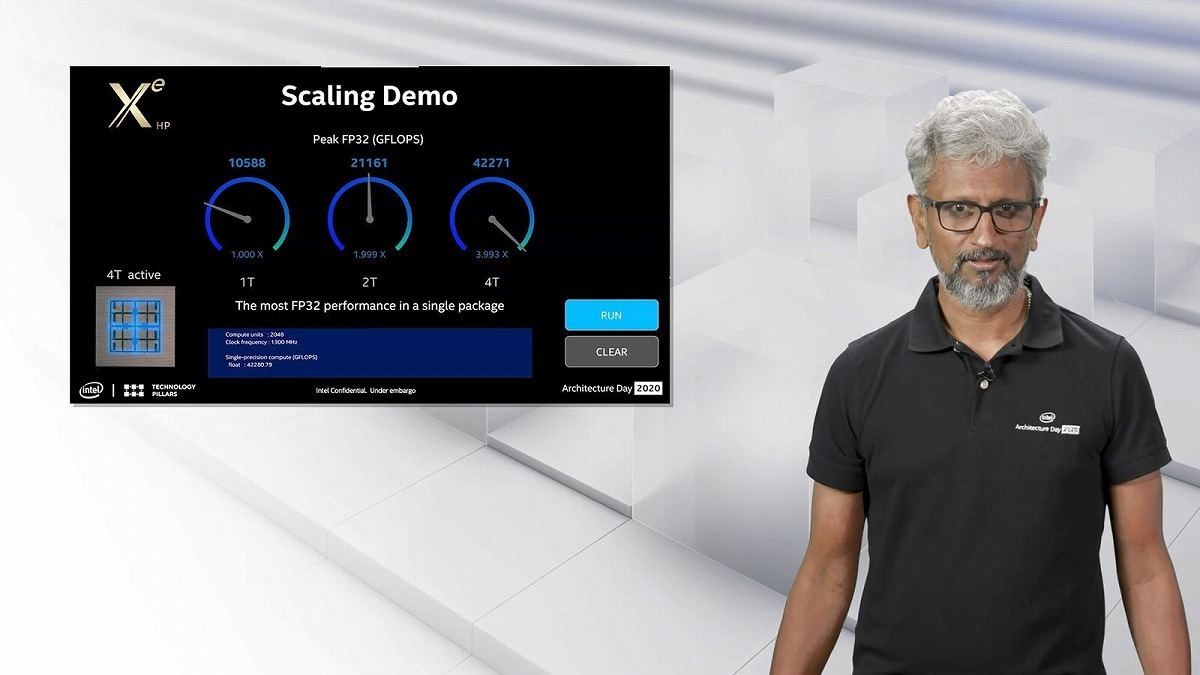
Photo28: デモそのものはあくまでスケーラビリティを示すものだが、性能も同時に公開された形だ。

Photo29は先に示した4つの製品のパッケージ技術をまとめたものである。ここでExternal、とあるのはおそらくTSMCの5nm/6nmと思われる。
-

Photo29: 気になるのはPonte VecchioのRAMBO Cache Tileが10nm Enhanced SuperFinでの製造になっている事だが、間に合うのだろうか?

ということで
説明はこの後ソフトウェアやFPGA、メモリなどもカバーするものであったが、まずは興味をそそられるであろうプロセスとCPU/GPUについて簡単に速報をお届けした。このうちTiger Lakeとか(今回は触れられなかった)Ice Lake-SPについては、来週から開催されるHot Chips 32で詳細な説明が公開される予定なので、こちらのレポートという形でまたお届けしたい。








