
◆Execute
さて、次は実行ユニットである。Photo02でも明らかな様に、実行ユニットはALUとFPUで完全に独立しており、まずはALUについて。大きな違いは先にも書いた通りAGUを3ユニット搭載した(Photo12)事で、これでALUは最大7 issue/cycleの処理性能となっており、この点ではCoffeeLakeと大差ない(Coffee LakeはALU×4、AGU×3、StoreData×1の8 issue/cycle)事になる。
-
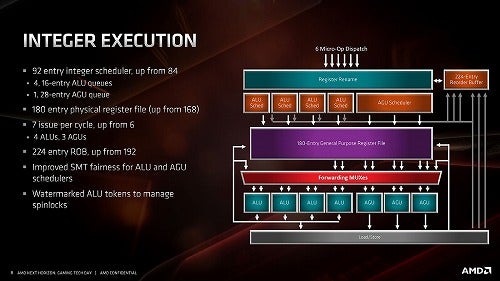
Photo12: AGUのスケジューラが一本化されたのがちょっと興味ある部分。AVX2のLoad/Storeをハンドリングするにはこの方が便利だったのかもしれない。

従来のZen/Zen+(Photo13)との比較で言えば、AGUの追加以外に
・スケジューラが84(6×14)から92(4×16+28)に変更
・Register Fileが168→180に増加
・ROB(Re-Order Buffer)が192→224に増加
などが主なポイントである。
-
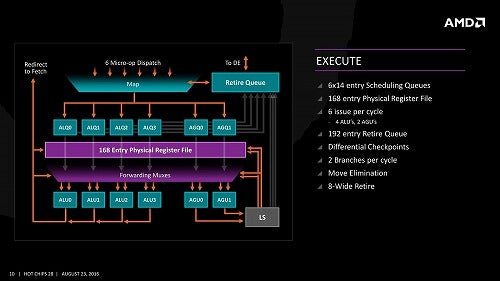
Photo13: AGU毎にスケジューラが用意されているのが判る(AGQ0/AGQ1)。

ALUの各々の性能というか、各命令毎のThroughput/Latencyはまだ公開されていないし、一覧を並べても仕方がないところで、これは後程の性能評価のところで判断するとして、ROBの振る舞いだけ確認してみた。
-
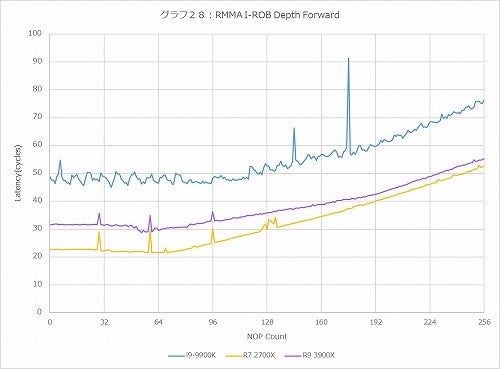
グラフ28

-
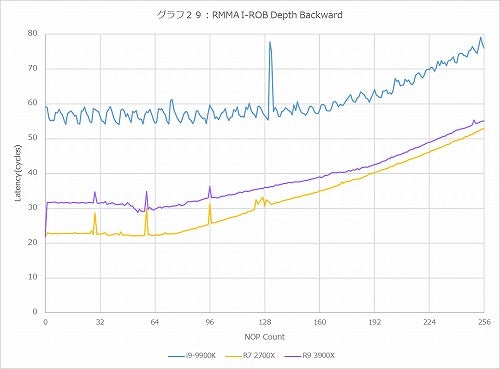
グラフ29

-
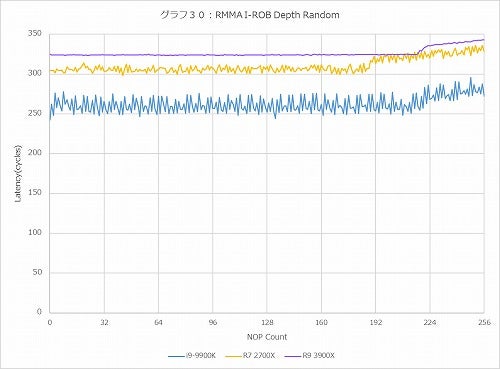
グラフ30

-
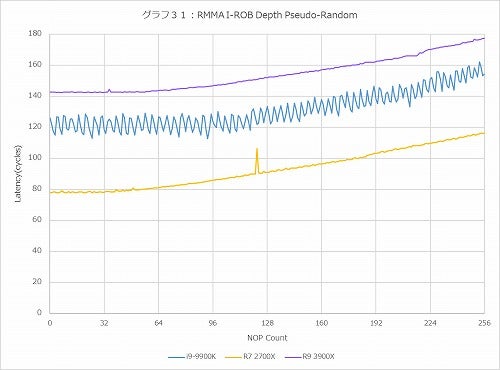
グラフ31

グラフ28~31がそれで、まずForward(グラフ28)で言えば、Countが少ない所ではRyzen 9 3900XのLatencyはややRyzen 7 2700Xより大きいが、それでもCore i9-9900Kよりは随分マシである。Backward(グラフ29)も概ね同じである。ただ、これがRandom(グラフ30)になると、Core i9-9900Kよりもやや大きくなっているのはRyzen 7 2700Xと同じである。ただ細かな変動がなくストレート、というあたりは構造に若干の手が入っている事が想像される。一番大きな違いがあるのがPseudo-Random(グラフ31)で、Ryzen 9 3900Xが概ねRyzen 7 2700Xより60cycleほどLatencyが増えている辺りは結構不思議ではある。ROBのエントリを増やした分Latencyが多少増えるのは致し方ない所だが、ROBの管理方法にあるいは手が入ったのかもしれない。
同様にFPUについて。Zen 2の構造(Photo14)とZenの構造(Photo15)を見ると一見同じなのだが、最大の特徴は256bit化にある。Zenの場合、128bitのFPU×4なので、これを組み合わせれば128bitのFMAを1cycleあたり2つ実行できそうなものなのだが、以前にこちらの記事で説明した通り、Zen/Zen2のFPUは非対称構成で、FMAが実行できるのは常に1つだけとなっている。
-
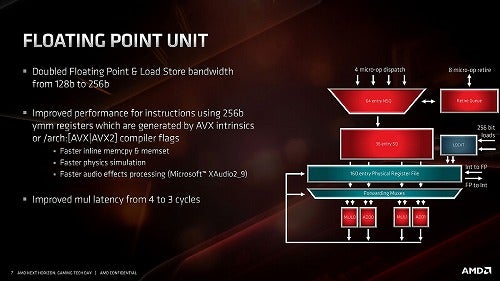
Photo14: Zen 2のFPUの基本的な構造は、Zenから変わらない。

-
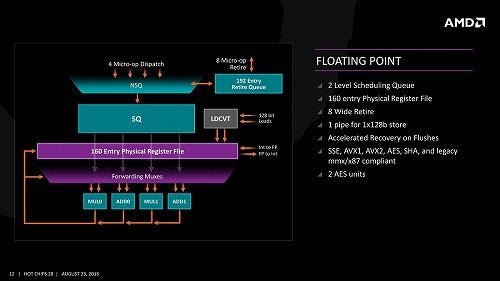
Photo15: AVX512はともかくとして256bitのAVX2命令が実行できないのは、そろそろZen世代のウィークポイントの一つになり始めていた。

「なんで非対称構成にしたのか」とAMDの担当者に確認したことがあるのだが「いや一応対称構成も検討したのだけど、色々上手くなかった」という返事が返ってきた(なにがどう上手く行かなかったのかは不明)。それもあってZen 2ではFPUを全部256bit幅にしており、これにあわせてLoad/Storeも256bit幅に強化されている。ただFMAを実行できるのは1組だけになっており、なので256bitのAVX2命令は実行できるが、AVX512は未サポートのままという形だ。こちらも、あとで性能評価という形でその性能を確認してみたいと思う。








