
◆Fetch&Decode
さて、次はFetch&Decodeである。まずFetch。Fetchそのものはまず32Bytes/cycleでL1 I-Cacheから取り込みを行い、Decode Unitに送り込む。このFetchの際に、次の命令を分岐予測する必要がある訳だが、第3世代Ryzenではこの分岐予測に従来のPerceptronベースのものに加え、新たにTAGE(TAgged GEometric)という技法が採用された。
正式には"TAgged GEometric history length branch prediction"という名前がついているこの技法、現時点で提案されている技法の中では一番精度が高いとされる。ただしその分実装が重い(すごくラフに言えば、履歴の長さを2倍・4倍・8倍・...と増やしていって、一番マッチするものを選ぶという技法であり、履歴を長く取れば取るほど精度が上がるが、それを記憶したり比較したりするために処理時間と処理回路規模の両方が大きくなる)という欠点がある。そこで第3世代RyzenというかZen 2では、一次分岐予測には従来と同じくPerceptronベースのものを入れ、二次分岐予測にこのTAGEを採用するという形を取った。具体的にどの位の履歴を比較するのかの詳細は無いが、これによって30%ほど分岐ミスを低減出来た、としている(Photo08)、他にBTBの大容量化や、新たにL0 BTBの追加なども行われている(Photo09)。残念ながらこの分岐予測周りについては、これを確認できるようなベンチマークがそもそも存在しないので、後程Sandraでパフォーマンスを見ながら確認してみたいと思う。
-
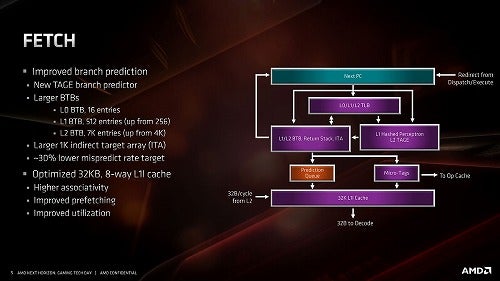
Photo08: このL1とL2を、どう組み合わせているかも明確ではない。普通に考えればまずPerceptronである程度候補を絞り込み、そこで候補同士に明確に差が無い場合のみL2で更にTAGEを利用して判断を行う、というあたりではないかという気がする。

-
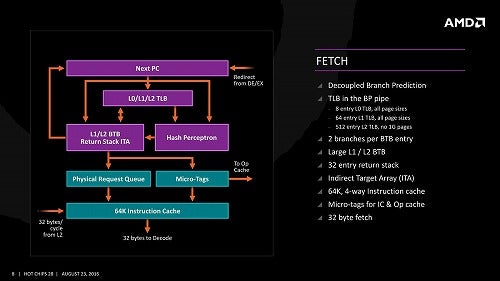
Photo09: こちらは初代Zenの内部構造。BTBはL1/L2のみだった。

次がDecode(Photo10)。Decodeそのものは1cycleあたり32BytesをI-Cacheから読み込み、最大で4つのx86命令をデコードする。このあたり、Coffee Lakeでは5命令/cycleのデコード能力を持つが、Intelは従来同様にSimple Decode×4+Complex Decode×1という構成、対するZen系はUnified Decode×4なので、実質的には大差ないというか、場合によってはZen系の方が高速な場合もあり得るだろう。Zen(Photo11)と比較した場合、Zen 2ではMicroOp Cacheの容量を倍増(4K Fused Ops)にしたほか、"effective throughput"を増強したとしているが、具体的にどんな? という話は公開されていない。
-
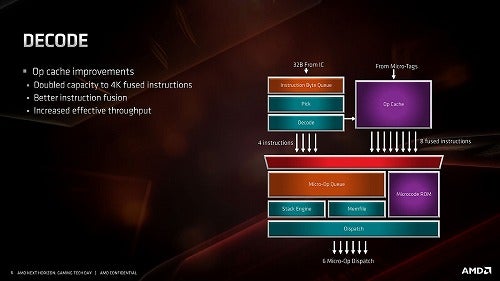
Photo10: MicroOp Cacheからは最大8つのfused instructionを送り出し可能。もっともこれはMicroOp Cacheに2つのMicroOp(例えばLoad+Addとか)を1命令として格納しているという話で、だからOpCacheからは4命令/cycleで送り出されるが、MicroOp換算だと8命令/cycleになる、という意味と思われる。

-
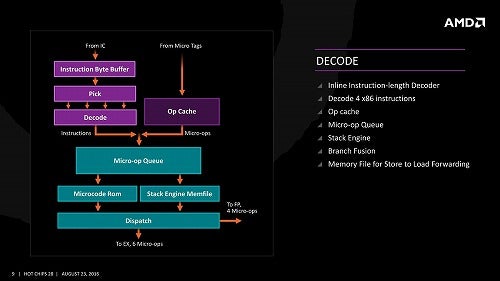
Photo11: 初代ZenのDecode部。基本的な構造は変わらない。

さて、ではそのデコード性能(ついでにL1 I-CacheのBandwidth)を確認ということで、グラフ22~26がRMMAのDecode Bandwidthである。RMMAのDecode Bandwidthは以前こちらの記事でも説明したが、トータル16種類のテストである。ただ結果を見ると、命令長が同じものは同じ結果になっているので、今回は代表として
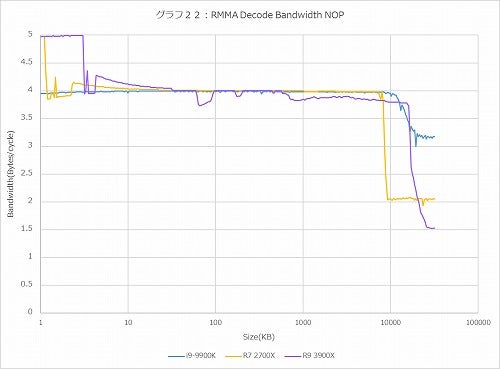
グラフ22:NOP(1Byte)
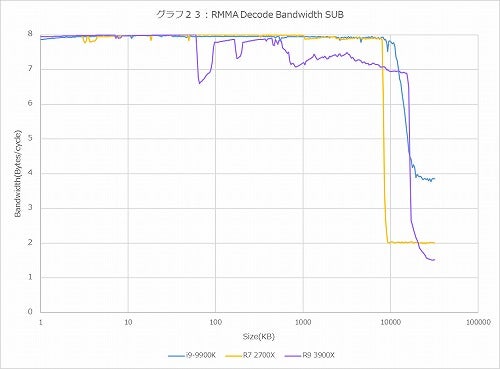
グラフ23:SUB(2Byte)
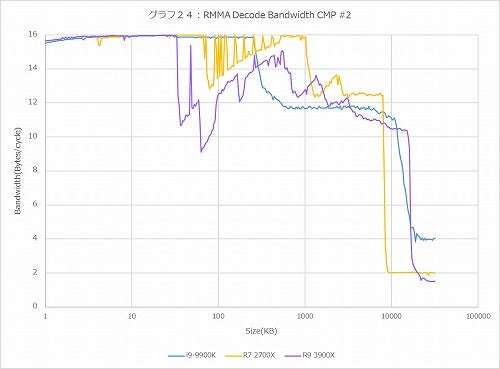
グラフ24:CMP #2(4Byte)
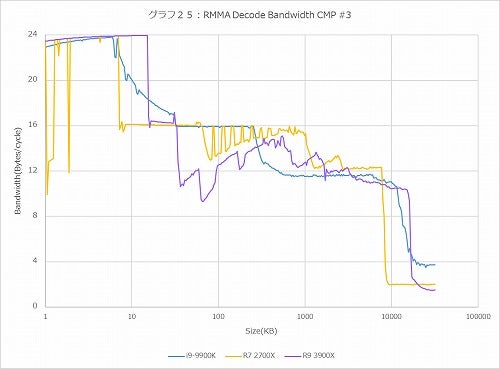
グラフ25:CMP #3(6Byte)
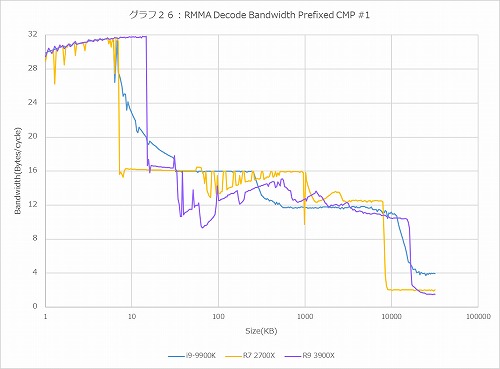
グラフ26:Prefixed CMP #1(8Byte)
の5つに絞り込んだ。
-
グラフ22

さてまずは1Bytes/cycle(グラフ22)。こちらでは4命令/cycleがデコードのピークなのでBandwidthは4Bytes/cycleがピークになる筈なのが、Ryzen系は5Bytes/cycleがピークになっている。しかもRyzen 7 2700Xはこれが2KBあたりまでなのに対し、Ryzen 9 3900Xは4KBまでこのピークが続くあたり、これはMicroOp Cacheから渡されるものについてはこのピークを超える、という動きになっていると考えられる。
ただこの後のグラフではピークが4命令/cycleになっているあたり、これはFused Instructionのお陰ではないか? と考えている。そもそもNOPに関しては、それの処理のために実行ユニットを動かすことはせずに、単にスケジューラ内のキューに空白を1個入れて終わりである。NOPの処理は、そんな訳でALU 0~3のそれぞれのキューに1個づつ空白を入れるだけなので本来は4 NOP/cycleとなるのだが、恐らくFused Instructionのために、
NOP/NOP/NOP/NOP+NOP
という様な形で5つのNOPがスケジューラに渡され、NOP+NOPはただのNOPに変換されて処理される、というあたりではないかと思う。
-
グラフ23

-
グラフ24

-
グラフ25

-
グラフ26

では普通に処理されると? というのが2BytesのSUB(グラフ23)で、ピークで8Bytes/cycle=4命令/cycleでまぁセオリー通りである。ちょっと面白いのはRyzen 9 3900Xのみ、60KBあたりからデコードのスループットがやや凸凹し始めている事だ。この傾向はこの後も出てきており、4BytesのCMP #2(グラフ24)ではRyzen 9 3900XのみならずRyzen 7 2700Xでも似た傾向が出ている。6BytesのCMP #3や8BytesのPrefixed CMP #1でも同じである。ピークのBandwidthはグラフ26の32Bytes/cycleであり、これはまぁセオリー通りである。ではこの変な落ち方は何か? であるが、恐らくは強化された分岐予測のせいではないかと考えている。これにはちょっと説明が必要だろう。
RMMAのDecode Bandwidth Testでは、まずCodeBlockと呼ばれる命令エリアのメモリ領域をDynamicに確保(この場合だと32MB)し(これがNXbitなどの保護機能に引っかからない様に色々策を講じているのだが、それは措いておく)、そこに測定したい命令を埋め込んでおく。例えばグラフ26の場合で言えば、
0xF3, 0xF3, //
0x81, 0xF8, 0x00, 0x00, 0x00, 0x00 // cmp eax, 0x00000000 という8byteの命令が、それこそ32MB分延々と続くわけだ。で、これをメモリに書き出した後で、そこに命令ポインタを移して実行を掛け、その時間を測定するという形でBandwidthを測定している。
これを念頭に置いたうえで、ではそうしたrep rep cmp eax, 0x00000000という命令列が32MB分続いているプログラムを分岐予測が読み込んだ場合、どう判断するかを考えてみる。普通、こんな命令列はまずありえないから、PerceptronベースであってもTAGEベースであっても、間違いなく分岐予測など不可能である。これが人間なら「分岐予測しない」と判断できるのだろうが、恐らくRyzenでは頑張って分岐予測しようと努力し、その結果として妙にBandwidthが悪化するのだと思う。実際、Ryzen 7 2700Xでも多少変な乱れ方をしているが、これはPerceptronベースの分岐予測がバグった結果であり、Ryzen 9 3900XではこれにTAGEが更に頑張ってバグったために一層乱れる傾向になった、というのが筆者の推察である。
「バグって」とは書いたが、これはどう考えてもプログラムが悪い話で、要するにRMMAがPerceptronベースとかTAGEの分岐予測を想定していないからこんな事になってしまった、という話である(まぁ2006年にリリースされたプログラムにそこまで求めるほうが悪い、というのは確かだ)。逆に言えば、こうして乱れていない範囲はMicroOp Cacheが効いているということである。Photo08・10で判る通り、MicroOp CacheはBranch Predictionの後の段で動作するから、ここがヒットしている間は限りなく高いThroughputが期待できる、という話でもある。
ただこれはまた、MicroOp Cacheのデータの持ち方のヒントも与えてくれる。グラフ24、つまり4Bytes命令の場合、16KBあたりから急にThroughputが落ちている。4Bytes×4K MicroOp=16KBだから、これは実にリーズナブルである。ところが6Bytesのグラフ25では15KB=2.5KOps、8Bytesのグラフ26では14.6KB=1.75KOpsあたりでMicroOp Cacheの効果が切れている模様だ。要するに短い命令は1MicroOpで収まるが、1命令が4Bytesを超えた場合、その分格納できるMicroOpが減るという、まぁ当然といえば当然ではあるが、ある程度の制約があることがここから見て取れる。勿論落ちる位置が違うだけでCore i9-9900KもRyzen 7 2700Xもやはり8KB付近でガクンとBandwidthが落ちているあたり、状況は同じであるのかもしれないが。
-
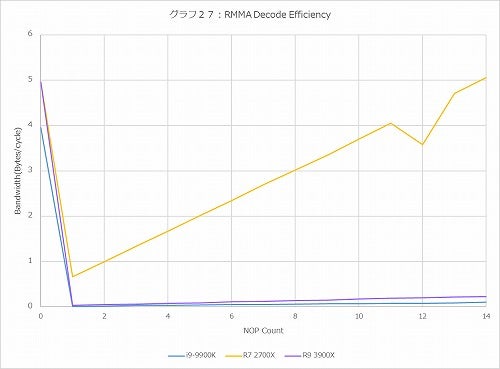
グラフ27

Decode周りではもう一つ、Decode Efficiency(グラフ27)についても確認した。要するに命令の前に無駄にPrefixを増やしてDecode Bandwidthがどう落ちるかを見るものだが、意外にRyzen 9 3900Xではこれが急激に悪化している。まぁそれでもCore i9-9900Kよりも気持ちマシではあるが、Ryzen 7 2700Xとは比べようがない。このあたりは分岐予測というよりは、Decode段の最適化が逆に作用している感じである。
ということでここまでで言えば、第2世代Ryzen(要するにZen/Zen+コア)では割とプリミティブなところが残っており、それが性能が上がらない一因でもあった半面、妙に性能が落ちたりしない部分もあったのだが、Zen 2コアでは大分この辺がソフィスティケートされて性能が上がる様になった半面、あまりに一般と違うプログラムコードがやってくると、急に性能が落ちるという、ややIntelに似た特性になってきた気がする。








