
◆Memory Controller
内部構造の最後はそのMemory Controllerを。といっても第3世代Ryzenではこの部分が別チップになっている訳だが。既に性能評価編でRMMTのReadとWriteの結果はご紹介しているので、性能そのものが悪くない事はご存知かと思う。
性能だけでなくOverclock耐性も高く、先のPhoto22にも出てきたが、デモではDDR4-5133の動作も不可能ではない(当然メモリの方も選別品が必要)とされている(Photo23)が、さすがにここまでくると結構大変で気軽に試せるレベルではない(Photo24)。ただ先にPhoto22にもあるように、「DDR4-4200+は容易」という事で、むしろメモリを何を使うかの方が問題と言える。ちなみにAMDによれば「価格性能比で言えばDDR4-3600が現時点ではお勧め」だそうである。
-

Photo23: 当然ながらMemory Moduleとか駆動電圧などは未公開。発表会では液体窒素冷却と対でデモされたが、それでもなかなかうまく行かなかった。

-

Photo24: Next Horizon Gamingにおけるデモ風景。これがまたうまくいかないという...ちなみにこれは筆者の撮影でなく、AMD提供のものである。

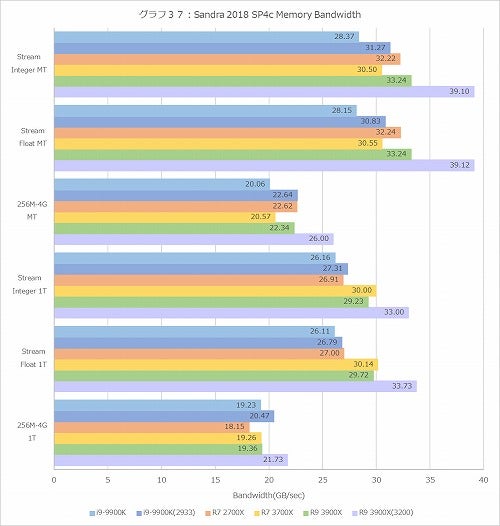
さて、そんな訳でRMMTの結果は既にご紹介したので割愛し、SandraのMemory Testを中心にちょっと確認しておきたいと思う。まずグラフ37はStreamのInt/Floatと、それと先にグラフ4・5で示したCache/Memory Bandwidthのうち、256MB~4GBの範囲のThroughputを、MT(全スレッド)と1T(1スレッドのみ)で実施した結果である。
-
グラフ37

やはりRyzen 9 3900Xを、特にDDR4-3200で利用した時の帯域の高さは他を圧倒しており、Streamでほぼ40GB/sec近く(理論帯域は64GB/secだから、効率60%強)、これは悪い数字ではないと思う。また1 Threadの場合の性能も特に傾向に違いは無い。強いて言えば、MTで言えばRyzen 9 3700XがRyzen 7 2700Xよりやや低い結果なのに、1TだとRyzen 9 3700Xの方がスループットが高い、というのはメモリコントローラの想定速度が異なっており、Ryzen 7 3700Xの性能を生かしきれないという事かもしれない。同じDDR4-2666でも、Ryzen 9 3900Xの場合には、恐らく2つのダイからMemory Access RequestがcIODに来る結果として、常にMemory Controllerが稼働する事になり、これが効率が悪くない結果に繋がっている可能性がある。まぁ第3世代Ryzenを使うなら、メモリはDDR4-3200をお勧め、ということであろうか。
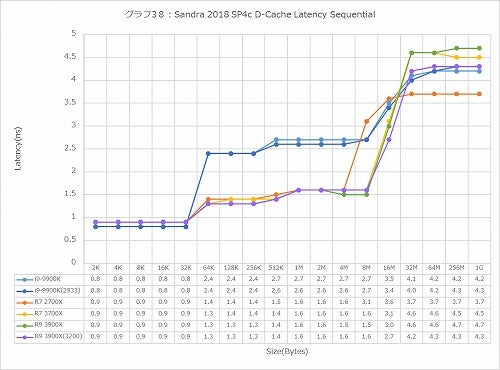
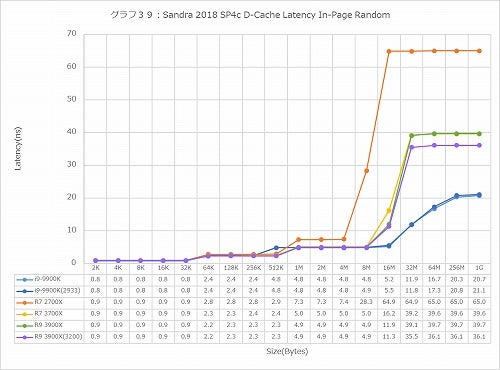
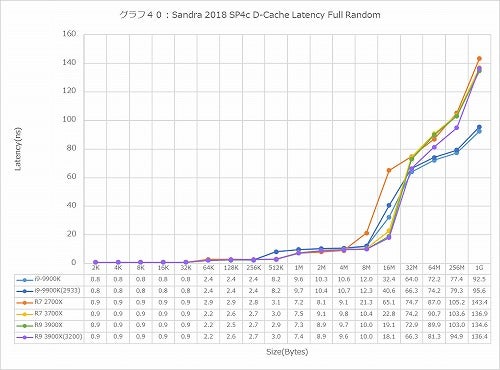
グラフ38~43は、先ほどグラフ6~11として示したものと同じ、D-Cache/I-CacheのLatencyであるが、こちらは縦軸の単位をnsにしたものである。動作周波数が各々異なるから、CacheにHitするL1~L3の領域はともかく、Memory AccessのLatencyにはそぐわない。そんな訳で32MB以上のサイズについての比較はこちらのグラフで行う事にしたい。
-
グラフ38

-
グラフ39

-
グラフ40

さてまずはD-Cacheアクセス(グラフ38~40)。Sequential(グラフ38)だと意外にもRyzen 7 2700XがもっともLatencyが少なく、次がCore i9-9900Kと、DDR4-3200のRyzen 7 3900X、一番Latencyが多いのがDDR4-2666の第3世代Ryzenというちょっと面白い結果である。ただ何しろ一番Latencyの少ないRyzen 7 2700Xが4.2ns、一番多いRyzen 9 3900Xでも4.7nsでしかないから、これは誤差の範囲に近い。
ではIn-Page Random(グラフ39)では? というといきなり第3世代Ryzenの素性の良さが目立つ結果になった。さすがにCore i9-9900Kに比べるとややLatencyは多いが、Ryzen 7 2700Xに比べるとLatency 4割減といったところで、これはかなり優秀な結果だと思う。Full Randomになるとその差が多少縮まるが、それでも1GBのところで10ns近い差があるあたりは、やはりMemory Controllerを再設計した効果があったことが見て取れる。
-
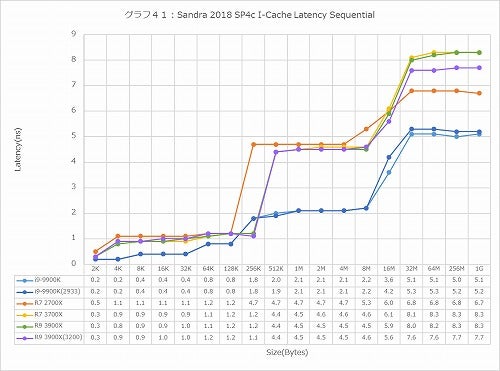
グラフ41

-
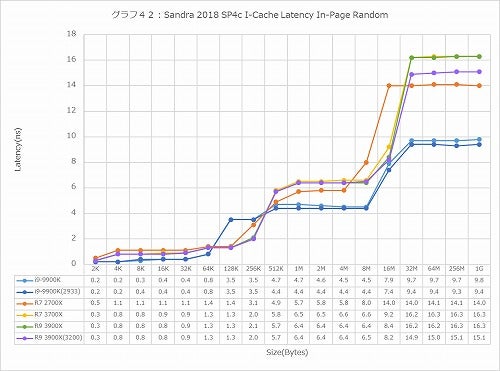
グラフ42

-
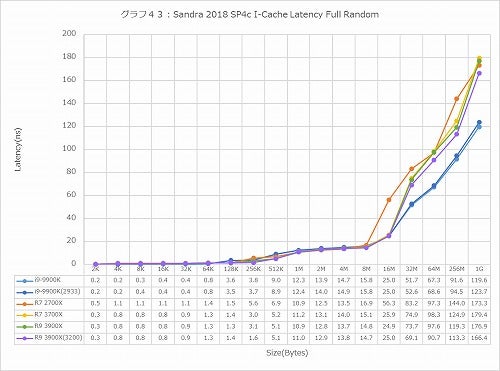
グラフ43

ちょっと様相が変わるのがI-Cache、つまりL1 I-Cache経由でのアクセス(グラフ41~43)であるが、こちらは確実に第3世代Ryzenの方がLatencyが増えている。恐らくは、Branch Predictionの性能強化によって、実際のアクセスまでに余分な時間が掛かっているため、と想像される。
ただこれはおそらく実害はない。というのは、このアクセス性能がモロに性能に反映するシチュエーションというのは、要するにMicro-Op CacheもL1 I-CacheもMissしており、しかもL2/L3もHitしなかったというケースになるからで、そんなシチュエーションがどの程度あるか? といえば、ベンチマークを掛けるとき位であろうと想像される。








