Armの日本法人であるアームは4月4日に都内で「Japan Media Day」と題した説明会を開催、主に同社のIPに関する最新動向についてArm本社の担当者を招いての説明が行われた(Photo01~03)。
-

Photo01:冒頭の挨拶を行ったアームの内海弦社長
-

Photo02:クライアントおよびインフラストラクチャに関して説明を行ったIan Smythe氏。以前の肩書はSenior Director, Marketing Programs, Client Line of Businessだったが、この4月よりVP Marketing Programs, Client Line of Businessに
-

Photo03:ADAS/自動運転について説明を行った新井相俊氏(ADirector, ADAS/Automated Driving Platform Strategy)。現在はベイエリアで勤務中



といっても、実はあまり新しい話は無かったりする。まずクライアントに関して言えば、CPU IPおよびGPU IPに関しては昨年6月のCOMPUTEXにおけるCortex-A76やMali-G76の発表が最新という状況で、そこからの大きなアップデートは特にない。ADAS/自動運転に関しても、昨年12月の説明会の内容とほぼ同じであって、ここからの大きなアップデートは特になかった。ただ、会話の折々で色々と新しい情報が得られたので、その点に着目してご紹介したい。
クライアント
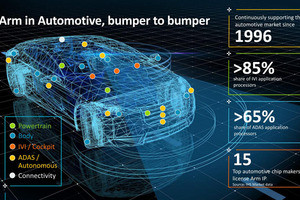
ロードマップ的に言えば、現行のCortex-A76/Mali-G76が7nm向けに提供されており、これに続いて「Deimos」が7nm EUVをターゲットに恐らく今年中(COMPUTEXあたりの可能性が高い)、それに続き「Hercules」が7nm/5nmをターゲットとしており、これが2020年中のリリースになると思われる。そのDeimosであるが、対応する命令セットに「Armv8.5A」が入るという話であった。ただArmv8.5AはこれはCortex-A76には入らないものの、Neoverse N1にはすでに実装されているものである。以前の記事では「実装はされているが検証およびソフトウェアのサポートがNeoverse N1のリリースで間に合ったというあたりで、後追いでCortex-A76でもサポートされる可能性はありそうだ」と書いていたが、Deimosまでお預けとなりそうだ。
もう1つ、このDeimos/Herculesに関しては、性能比較が示された(Photo04)。Cortex-A73と比較した場合、Herculesでは2.5倍の性能になるというものだ。Smythe氏曰く「このCortex-A73を搭載したSnapdragonを実装したHPのEnvy X2が(Hercules世代では)2.5倍高速になる」ということで、Intelに負けない性能を達成できる、というのがArmの見解である。ただ後で「でもWindows Clientに搭載されるのはSnapdragonであって、それ以外のベンダのSoCでWindowsが動くわけではないよね?」と確認したところ「現状はそうだが、今後の製品の広がり方を考えれば可能性はある」という返事が。現在はWindowsではなくChromeBookという選択肢もある訳で、Deimos/Hercules世代になればなんにせよこのマーケットでIntelのプロセッサと互角の性能になる、と考えているそうだ。この点については、Intelの10nm世代がどこまで性能を上げてくるか、というところが今後の焦点になりそうではある。
-

Photo04:公式にはSnapdragon 835のコアはKryo 280である。まぁ中身がCortex-A73ではないか? という声は以前からあった

ADAS/自動運転
2つ目の話題はADAS/自動運転関連。以下のスライドは以前もご紹介したものであるが(Photo05)、これに絡んで新井氏がちょっと興味深い話をしていた。
-

Photo05:このシステムの消費電力は、先日GMがこれを公開したので、Armもこれについて話せるようになった、との事だった

現状の自動運転プラットフォームの場合、システムの消費電力は2000~3000W、多いものでは5000~6000Wに達しているそうである。現時点の自動運転車の中心はソフトの開発なので、サーバ用のCPUというかサーバそのものをトランクに積んで利用しており、それ故に許容される数字なのだろうが、これを2桁落とさないと実用化には遠いという話であった。
もう1つ、これはクライアントの話の際にも出てきているのだが、例えばFace Detectionを利用したロック解除(Face Unlock)にどの程度の推論時間が必要か、ArmのIPごとに比較してみると(Photo06)、最速なのがArm NPUというのはともかく、さまざまなコアを利用しての性能が垣間見えるのが面白い。もちろん自動運転においてもさまざまなところでCNNを利用したマシンラーニング(ML)が使われていく事は間違いなく、こうしたところにもCPU/GPU/NPUというソリューションを用意し、かつそれをArm NNという共通のフレームワークで扱えるようにすることで、ADAS/自動運転向けのソリューションを提供できるとした。
-

Photo06:個人的には、先日発表になったArmv8.1M/Heliumを利用した場合、これがどの程度の処理時間になるのか興味あるところだ

インフラストラクチャ
最後の3つ目となるのがインフラストラクチャであるが、こちらは新しい情報は特にない。ただ、マーケット予測の中で少々面白い話題が出てきた。
Armはインフラストラクチャに関して、スループットコンピューティング(Throughput Compting)が重要という言い方をしているが、その根拠となるべき資料がPhoto07だ。
-

Photo07:Smythe氏曰く「これはCiscoの資料だ(から、別に我々が数字を盛ったわけではない)」

CDN(Contents Deliver Network)とManaged IP serviceの要求する帯域が急増するというもので、その一例として挙げられたのが右側の3つである。HD解像度の監視カメラが5億台あると、その帯域が329EB(ExaByte)/月、カーナビにおける映像を利用した指示などが6EB/月、スマートスピーカーなどによる音声UIの帯域が1EB/月になる、というもので案外馬鹿に出来ない規模なのが判る。要するにこれからは大量のデータをいかに捌くかというスループットコンピューティングが処理の中心になっていくとしており、Neoverseはこのスループットコンピューティングのワークロードに最適化したアーキテクチャである、というのがSmythe氏の説明であった。